
Leia também:

Data Science, ou ciência de dados, é a área responsável por transformar dados brutos em informações que ajudam empresas a tomar melhores decisões.
Assim, você consegue responder perguntas como: o que aconteceu com minhas vendas nos últimos meses? Por que houve queda no engajamento? O que pode acontecer nos próximos trimestres? O que posso fazer para melhorar meus resultados?
Na prática, Data Science é sobre encontrar padrões nos dados, entender o que eles significam e transformar esse conhecimento em ações práticas.
Quer entender melhor esse conceito? Assista à explicação do professor Rodrigo Tadewald no vídeo abaixo:
A ciência de dados serve para transformar grandes volumes de informação em conhecimento útil para apoiar decisões, prever cenários e gerar vantagem competitiva.
Com ela, você consegue entender melhor o público-alvo de uma empresa ou projeto, otimizar processos, reduzir custos e inovar com mais segurança.
Por isso, o Data Science pode ser aplicado em diversas áreas, como:
O Data Science envolve o uso de diferentes tipos de análise que ajudam a entender o passado, explicar o presente e antecipar o futuro de um projeto. Por isso, ele pode ser aplicado em diversas situações. Entenda a seguir como essas avaliações funcionam e por que são importantes.
A análise descritiva examina dados históricos para identificar padrões e comportamentos. É o tipo mais comum de análise e serve para entender o que está acontecendo ou o que aconteceu em determinado período.
Por exemplo, vamos supor que você precisa analisar os dados de reservas dos últimos meses de uma rede hoteleira para identificar os picos de vendas. Com a análise descritiva, é possível perceber que esses picos ocorrem no mês de maio.
A partir desse resultado, você pode gerar gráficos de linha, tabelas ou dashboards interativos para apresentar os dados e facilitar a visualização das tendências.
Depois de entender o que aconteceu, é hora de descobrir o motivo. A análise diagnóstica é usada para identificar as causas por trás de um comportamento ou resultado.
Seguindo o exemplo anterior, ao investigar por que os picos de vendas ocorrem em maio, você descobre que, nesse período, acontecem várias festas regionais em determinada localidade.
Com base em dados históricos, algoritmos de machine learning e estatística avançada, a análise preditiva ajuda a prever comportamentos futuros. Por isso, ela é importante para o planejamento estratégico.
Por exemplo, você pode utilizar os dados das análises anteriores para prever um novo pico de reservas no mesmo período do ano seguinte.
Esse é o tipo mais avançado de análise, já que combina previsões com recomendações. Ou seja, além de indicar o que provavelmente vai acontecer, ela sugere as ações mais eficazes para alcançar os melhores resultados.
No caso das reservas, essa análise permite que você simule diferentes estratégias de marketing para o mesmo período no próximo ano. Assim, fica mais fácil escolher a que apresenta maior potencial de sucesso.
Embora todas trabalhem com dados, essas áreas têm objetivos, ferramentas e aplicações bem diferentes.
Data Analytics (ou análise de dados) é o processo de coletar, limpar, organizar e interpretar informações com o objetivo de entender o que aconteceu e por que aconteceu. Ou seja, o objetivo é descrever e diagnosticar eventos com base em dados existentes.
Já a ciência de dados é uma área mais ampla, que combina estatística, programação, IA e machine learning para criar modelos capazes de identificar padrões, fazer previsões e sugerir ações.
Na prática, o analista de dados transforma informações em relatórios que explicam o passado, e o cientista de dados desenvolve algoritmos que ajudam a antecipar o futuro e automatizar decisões.
E o machine learning ajuda nesse processo. Afinal, ele é uma subárea da Data Science voltada para a criação de algoritmos que aprendem sozinhos com os dados e fazem previsões sem serem explicitamente programados para isso.
Essa tecnologia é usada de várias formas, como sistemas de recomendação de produtos, detecção de fraudes, diagnósticos médicos e análise de sentimentos nas redes sociais.
Você pode não ter percebido, mas a ciência de dados já faz parte do seu dia a dia. Confira a seguir alguns exemplos de práticos de como o Data Science é utilizado no cotidiano:
Você recebeu sugestões personalizadas na Netflix, Spotify ou YouTube? Isso só é possível graças à ciência de dados.
Os algoritmos analisam seu histórico de uso, preferências e o comportamento de milhões de outros usuários para recomendar filmes, séries, músicas ou vídeos com maior chance de te agradar. Tudo isso acontece em tempo real e de forma automatizada.
Você pode utilizar modelos de regressão logística, por exemplo, para analisar o comportamento dos usuários de um site e identificar padrões de comportamentos.
Com base nesses dados, você consegue prever ações como compras, cliques em anúncios ou abandono de carrinho, tudo com base no histórico de navegação dos visitantes.
Instituições financeiras também utilizam a ciência de dados para facilitar a detecção de fraudes. Nesse caso, os algoritmos analisam padrões de comportamento de cada cliente e comparam com novas transações.
Se algo foge do comum, como uma compra fora do país ou um valor muito alto, o sistema pode bloquear temporariamente a transação e notificar o usuário. Isso ajuda a prevenir fraudes e a proteger os dados bancários dos clientes.
A ciência de dados pode ser usada para prever com precisão o valor de venda ou aluguel de um imóvel. Por exemplo, no projeto abaixo, estimamos o valor justo do aluguel de imóveis em São Paulo com base em dados reais extraídos de uma base pública:
Grandes redes de supermercados e lojas virtuais utilizam ciência de dados para prever a demanda por produtos em diferentes períodos. Essas previsões ajudam a planejar estoques, evitar rupturas de prateleira e reduzir perdas com excesso de mercadoria, otimizando toda a cadeia de suprimentos.
Empresas que vendem em marketplaces também podem se beneficiar da ciência de dados. Com uma análise detalhada das vendas, é possível identificar padrões de consumo, preferências dos clientes e tendências de mercado.
Essas informações ajudam a definir estratégias de marketing mais eficientes, melhorar o posicionamento de produtos e aumentar as vendas.
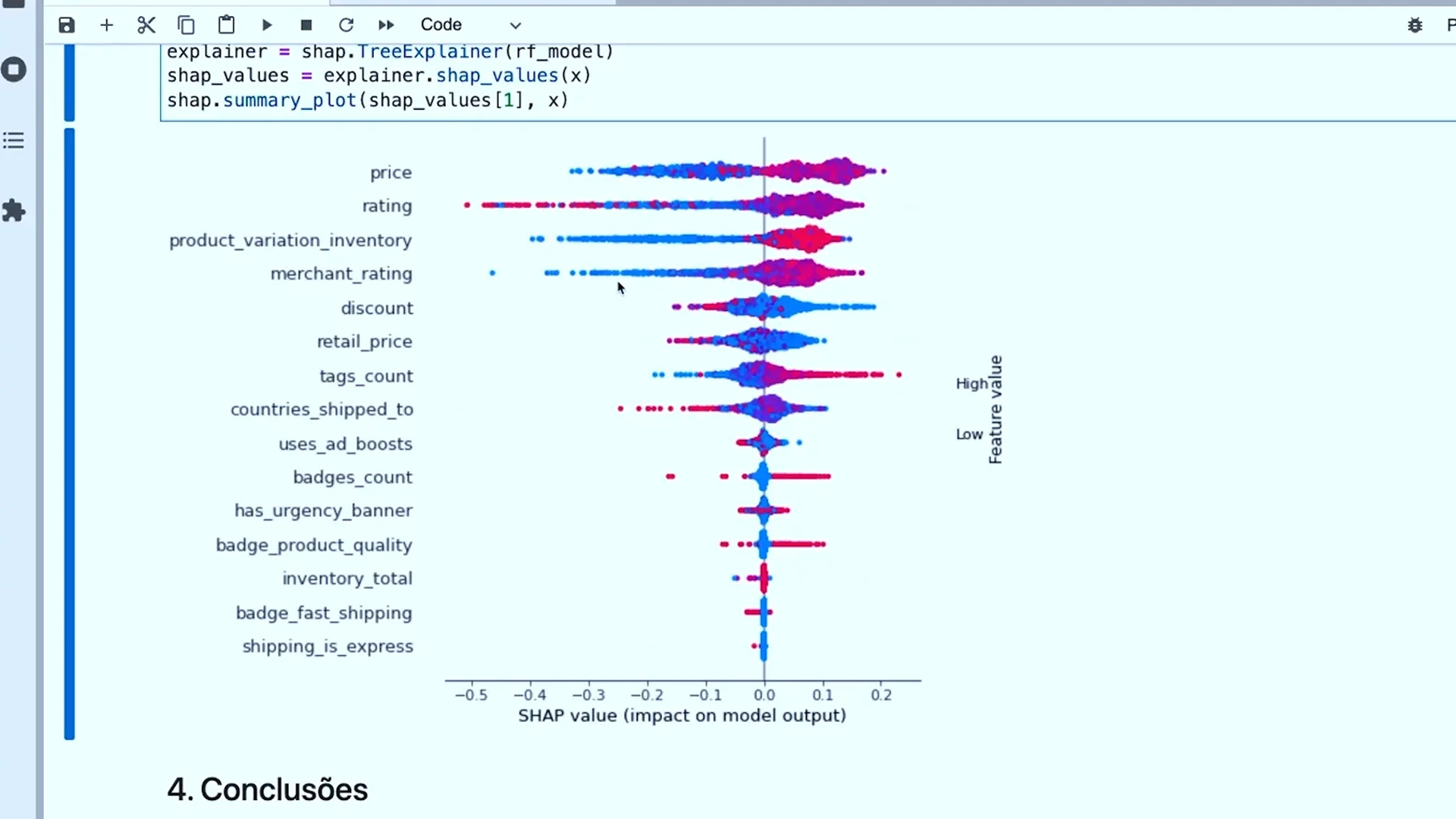
No mercado financeiro, a ciência de dados pode ser usada para analisar grandes volumes de informações e detectar padrões que podem orientar decisões de investimento.
Com técnicas avançadas de machine learning, por exemplo, você consegue analisar grandes volumes de dados financeiros e identificar tendências e padrões que ajudam na tomada de decisões de investimento na Bolsa de Valores.
Os aplicativos como Uber, iFood, Rappi e Amazon também usam sistemas de ciência de dados para traçar as melhores rotas, calcular o tempo estimado de entrega e distribuir pedidos de forma mais eficiente. Isso melhora a experiência do usuário e reduz custos operacionais para as empresas.
Os algoritmos de Data Science também podem ser utilizados na medicina preventiva. Eles podem analisar dados médicos e históricos de pacientes para identificar padrões e prever o risco de doenças, permitindo intervenções preventivas mais eficazes.
Por exemplo, você pode utilizar o Random Forest para prever doenças cardíacas em um determinado grupo de pessoas, como ensinamos no vídeo abaixo.
A ciência de dados pode ser utilizada de várias formas porque combina diferentes linguagens de programação, bibliotecas, plataformas e frameworks para analisar dados, construir modelos e apresentar resultados de forma eficiente.
Conheça abaixo quais as principais ferramentas utilizadas por profissionais da área:
As duas linguagens mais utilizadas em Data Science são Python e R. Ambas são gratuitas, de código aberto e contam com um vasto ecossistema de bibliotecas voltadas para análise estatística, machine learning e visualização de dados.

Cientistas de dados geralmente usam ambientes interativos como Jupyter Notebook e Google Colab para programar, testar e documentar suas análises. Eles também costumam usar o GitHub para compartilhar projetos e acompanhar alterações no código com a equipe.
Quando o volume de dados é muito alto, o ideal é utilizar ferramentas de big data como Apache Hadoop e Apache Spark. Elas permitem armazenar e processar dados em escala, sendo ideais para análises em tempo real ou com grandes conjuntos de dados.
O domínio de bancos de dados é uma habilidade básica para qualquer profissional da área. A linguagem SQL é padrão para consultar bancos relacionais.
Já bancos NoSQL, como o MongoDB, são recomendados quando os dados não seguem uma estrutura rígida ou exigem mais flexibilidade para escalar.

Para construir modelos inteligentes, os cientistas normalmente usam ferramentas como Scikit-learn, TensorFlow e PyTorch. Esses frameworks permitem implementar algoritmos de aprendizado de máquina, desde os mais simples até modelos complexos, como redes neurais profundas.
Com o avanço da tecnologia, o uso de plataformas em nuvem, como Microsoft Azure, Google Cloud Platform e AWS, se tornou essencial para escalar projetos de ciência de dados de forma rápida e integrada.
Afinal, essas plataformas permitem armazenar dados, treinar modelos e realizar o deploy de soluções em um único ambiente.

Você não precisa ter uma formação específica para se tornar um cientista de dados. O importante é desenvolver uma base sólida em três áreas principais: ciência da computação, matemática e conhecimento de negócios.
Cursos superiores como Ciência de Dados, Engenharia, Matemática, Estatística ou Ciência da Computação oferecem essa base. Mas você também pode ingressar na área por meio de cursos livres e trilhas práticas.
Veja por onde começar:
A estatística é a base da ciência de dados. Por isso, é importante entender conceitos como média, mediana, desvio padrão, distribuição normal, correlação, entre outros.
Esses conhecimentos vão te ajudar a interpretar dados com mais precisão e construir modelos preditivos mais confiáveis.
O Python é a linguagem mais usada em Data Science. É simples, fácil de aprender e tem uma comunidade ativa gigante. Você consegue aprender sozinho e de graça. Mas não se esqueça de estudar lógica de programação. Ela fará toda a diferença no seu processo de aprendizado e na aplicação prática da linguagem.
Com a base consolidada, comece a estudar os algoritmos de machine learning. O ideal é começar aprendendo os mais simples, como regressão linear, árvore de decisão e k-means. Somente depois disso, você deve avançar para os mais complexos, como Random Forest, SVM e redes neurais.
A melhor forma de fixar o aprendizado é colocando a mão na massa. Por isso, aplique o que aprendeu em projetos simples. Isso vai te ajudar a entender como aplicar as ferramentas de ciência de dados no mundo real e ainda servem como material para seu criar seu portfólio.
E, se você quiser aprender Data Science de forma prática, didática e orientada para o mercado, a Trilha Data Science e Machine Learning da Asimov Academy é o melhor caminho.
Com aulas práticas, projetos reais e mentoria especializada, essa trilha vai guiar seus estudos desde os fundamentos até as técnicas mais avançadas de ciência de dados.
Comece hoje mesmo seus estudos e mude o seu futuro!

Explore dados, desenvolva modelos preditivos e extraia insights valiosos para impulsionar a tomada de decisões.
Comece agoraData Science, ou ciência de dados, é a área que estuda e analisa grandes volumes de dados para extrair informações importantes e apoiar a tomada de decisões. Ela combina estatística, programação, IA e conhecimento de negócio para entender o passado, explicar o presente e prever o futuro.
O cientista de dados é o profissional que coleta, organiza e analisa grandes volumes de dados para extrair informações que ajudam empresas a tomar decisões mais inteligentes. Para isso, ele usa estatística, programação e técnicas de machine learning para identificar padrões, prever comportamentos e automatizar processos.
Você deve estudar estatística, programação, análise de dados, visualização de dados, machine learning e, com o tempo, ferramentas de big data e cloud computing. Também é importante desenvolver raciocínio analítico e curiosidade para resolver problemas com base em dados.
Profissionais como cientistas de dados, analistas de dados, engenheiros de dados, engenheiros de machine learning e analistas de negócios.
Depende. Se você já tem uma boa base em lógica de programação ou matemática, fica mais fácil. Não importa por onde você começa, o importante é organizar uma rotina de estudos que envolva os fundamentos da área, projetos práticos e acesso a bons materiais.
Data Science é um campo mais amplo que inclui coleta, análise, visualização e interpretação de dados. Já machine learning é uma área dentro da ciência de dados focada em ensinar máquinas a reconhecer padrões e fazer previsões com base nesses dados.
Segundo dados da Glassdoor, o salário base de um cientista de dados varia entre R$ 5.000 e R$ 10.000 por mês. Esse valor varia conforme a experiência do profissional e o porte da empresa. Cientistas sêniores, por exemplo, podem ganhar mais de R$ 15.000 por mês.
Aprenda sobre variáveis, loops e funções e crie seu primeiro projeto Python em apenas 2 horas!
Saia do zero e analise dados com Python e Pandas neste curso gratuito com certificado!
Aprenda a programar com Python e explore a inteligência artificial! Crie um chatbot prático que interage com seus próprios dados. Comece agora!
O que é IA no futebol? IA no futebol é o uso de sistemas inteligentes para analisar dados do jogo, reconhecer padrões, gerar previsões,…
Se você está pesquisando agentes de IA mais avançados do que um chatbot comum, provavelmente já encontrou dois nomes: OpenClaw e Hermes Agent. Os…
A IA generativa popularizou o uso de chatbots capazes de responder perguntas, escrever textos, resumir documentos e gerar código. Mas uma nova etapa da…
Comente e participe da conversa
Crie sua conta gratuita e compartilhe sua opinião nos comentários.
Entre para a Asimov