

A análise de dados com Python é uma prática essencial para transformar dados brutos em informações valiosas. Utilizando a linguagem Python, é possível explorar, limpar, processar e visualizar dados de maneira eficiente e intuitiva.
Neste artigo, vamos entender o que é análise de dados, o que é Python e por que essa linguagem é tão popular para essa finalidade.
O que é análise de dados em Python?
A análise de dados em Python envolve utilizar a linguagem de programação Python para entender os dados que você possui e extrair algum conhecimento novo a partir dele.
Exemplo prático: um gerente de vendas de uma empresa pode usar a biblioteca pandas de Python para calcular o total de vendas de cada vendedor no mês. Assim, o gerente descobre qual vendedor teve a melhor performance na sua equipe.
O que é análise de dados?
A análise de dados é o processo sistemático de inspecionar, corrigir, transformar e modelar dados para tirar conclusões e apoiar a tomada de decisão. Em outras palavras, é a prática de examinar conjuntos de dados para encontrar padrões, tendências e insights que possam guiar as ações futuras.
Imagine que você trabalha em uma empresa de e-commerce e quer entender melhor o comportamento de compra dos seus clientes. Nesse contexto, você pode ter perguntas como:
- Quais produtos têm mais vendas?
- Qual é o perfil dos clientes mais valiosos?
- Quais são os horários de pico nas vendas?
Para responder a essas perguntas, utilizamos a análise de dados. Ferramentas como Análise Exploratória de Dados (EDA), visualização de gráficos e estatísticas descritivas ou preditivas são comuns neste campo.
O que é Python?
Python é uma linguagem de programação de alto nível conhecida por sua versatilidade e sintaxe simples e legível. Dessa forma, Python é uma escolha excelente tanto para iniciantes quanto para desenvolvedores experientes.
Características do Python:
- Sintaxe simples: facilita a leitura e escrita de código.
- Bibliotecas ricas: conta com bibliotecas para diversas finalidades, como análise de dados, aprendizado de máquina, desenvolvimento web e desenvolvimento de aplicações com inteligência artificial.
- Comunidade ativa: por ser uma linguagem muito difundida, é bastante fácil buscar por ajuda, tutoriais e cursos de Python. Muitos recursos da linguagem são frequentemente atualizados.
Abaixo, há um exemplo de código em Python onde calculamos a média de uma lista de números:
# Definindo a lista de números
numeros = [10, 20, 30, 40, 50]
# Calculando a média
media = sum(numeros) / len(numeros)
# Exibindo a média calculada
print(f'A média é: {media}')Por que usar Python para análise de dados?
Python é amplamente utilizado para análise de dados pelos seguintes motivos:
- Facilidade de uso: a sintaxe simples de Python facilita a escrita e leitura de código e acelera o desenvolvimento e exploração dos dados.
- Bibliotecas poderosas: Python conta com bibliotecas especializadas para a análise e visualização de dados, como Pandas, NumPy, Matplotlib e Seaborn.
- Integração com outras ferramentas: Python pode ser facilmente integrado a outras ferramentas e tecnologias, como bancos de dados e APIs, permitindo assim a criação de automações diversas.
O exemplo demonstra o quão fácil é analisar dados com Python. Em poucas linhas de código, criamos um DataFrame (tabela) do Pandas, geramos estatísticas descritivas dos dados e usamos as bibliotecas Matplotlib e Seaborn para visualizá-los:
# Importando as bibliotecas
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Criando o DataFrame
data = {
'preco': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
'quantidade': [5, 7, 8, 6, 10, 12, 15, 14, 20, 22]
}
df = pd.DataFrame(data)
# Exibindo as primeiras linhas do DataFrame
print(df.head())
# Exibindo estatísticas descritivas
print(df.describe())
# Plotando um gráfico de dispersão
sns.scatterplot(data=df, x='preco', y='quantidade')
plt.show()O código acima gera o gráfico a seguir (você pode testar o código você mesmo no nosso Compilador Online de Python, clicando no botão Testar):

Como usar Python para a análise de dados?
Agora que entendemos o que é análise de dados com Python e por que ela é relevante, vamos entender mais a fundo de que formas podemos usar Python para analisar dados.
Principais bibliotecas de Python para análise de dados
Python possui várias bibliotecas que facilitam a análise de dados. Aqui estão algumas das principais:
- Pandas: utilizada para leitura, manipulação e análise de dados em tabelas.
- NumPy: utilizada para operações matemáticas e manipulação de vetores e matrizes.
- Matplotlib e Seaborn: utilizadas para visualização de dados.
- Scikit-learn: utilizada para aprendizado de máquina.
Vamos usar essas bibliotecas para ler um arquivo CSV de uma planilha do Google Sheets (a partir de uma URL de compartilhamento), exibir soma da coluna “valor” e plotar o valor por vendedor em um gráfico:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Lendo um arquivo CSV (link do Google Sheets)
url = 'https://docs.google.com/spreadsheets/d/e/2PACX-1vQK--NNvKEZXxIhTN4LfmvWtwpltuLdjuKprimSRYSapRaqmPntNE6lKXug1l1VV2n1xEKuCPydmRnf/pub?output=csv'
df = pd.read_csv(url)
# Exibindo as primeiras linhas do DataFrame
print(df.head())
# Calculando a média da coluna "valor"
media_coluna = df['preco'].mean()
print(f'Média da coluna "preco": {media_coluna}')
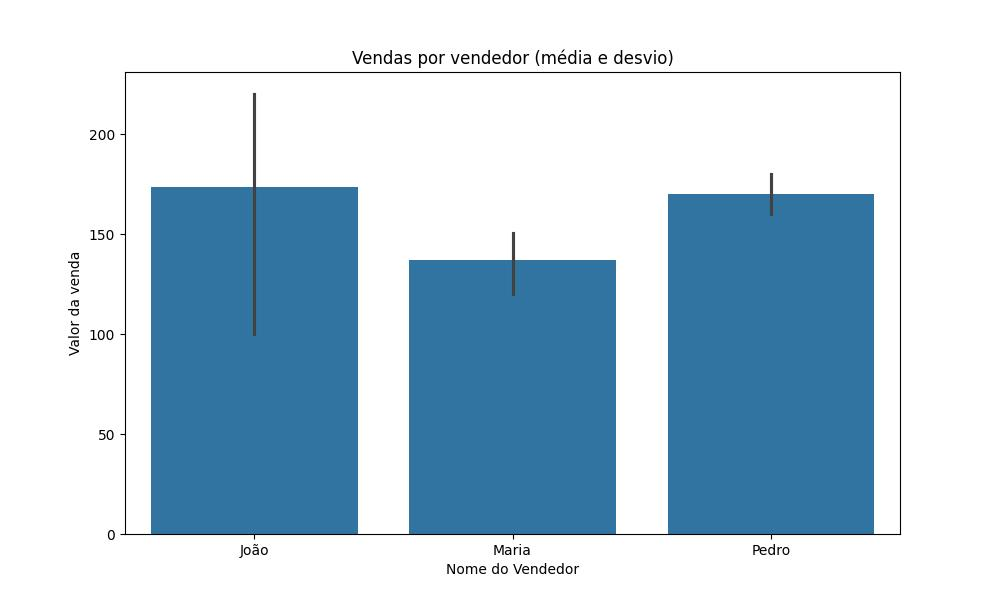
# Criando um gráfico de barras
plt.figure(figsize=(10, 6))
sns.barplot(x='vendedor', y='preco', data=df)
plt.title('Vendas por vendedor (média e desvio)')
plt.xlabel('Nome do Vendedor')
plt.ylabel('Valor da venda')
plt.show()Este código gera a imagem abaixo:
Python é bom para trabalhar com bancos de dados?
Sim! Python possui bibliotecas como sqlite3, Psycopg, PyMongo e diversas outras que permitem a conexão com diferentes bancos de dados SQL e NoSQL. Além disso, Python possui a biblioteca SQLAlchemy, que serve como um “coringa” para conectar com qualquer banco SQL.
Neste exemplo abaixo, usamos o SQLAlchemy para conectar a um banco de dados SQLite e realizar uma consulta:
from sqlalchemy import create_engine
import pandas as pd
# Criando uma conexão com o banco de dados SQLite
engine = create_engine('sqlite:///meu_banco_de_dados.db')
# Lendo dados de uma tabela do banco de dados
df = pd.read_sql('SELECT * FROM minha_tabela', engine)
# Exibindo as primeiras linhas do DataFrame
print(df.head())Dá para trabalhar com planilhas em Excel com Python?
Sim! É possível trabalhar com planilhas em Excel utilizando Python. Podemos fazer isso diretamente da biblioteca Pandas, com a função pd.read_excel. Se precisarmos de maior controle sobre a planilha (para formatar células e criar fórmulas, por exemplo), podemos usar a biblioteca Openpyxl para automatizar praticamente tudo dentro do Excel.
O exemplo abaixo lê uma planilha Excel chamada planilha.xlsx, cria uma coluna nova e salva o arquivo, tudo isso em poucas linhas com a biblioteca Pandas:
import pandas as pd
# Lendo a planilha Excel
df = pd.read_excel('planilha.xlsx')
# Exibindo as primeiras linhas do DataFrame
print(df.head())
# Adicionando uma nova coluna
df['nova_coluna'] = df['coluna_existente'] * 2
# Salvando o DataFrame em uma nova planilha Excel
df.to_excel('nova_planilha.xlsx', index=False)Dá para plotar um gráfico com Python?
Sim! É possível plotar gráficos com Python utilizando bibliotecas como Matplotlib, Seaborn e Plotly. Essas bibliotecas oferecem uma ampla gama de opções para criar gráficos e visualizações de dados altamente customizadas.
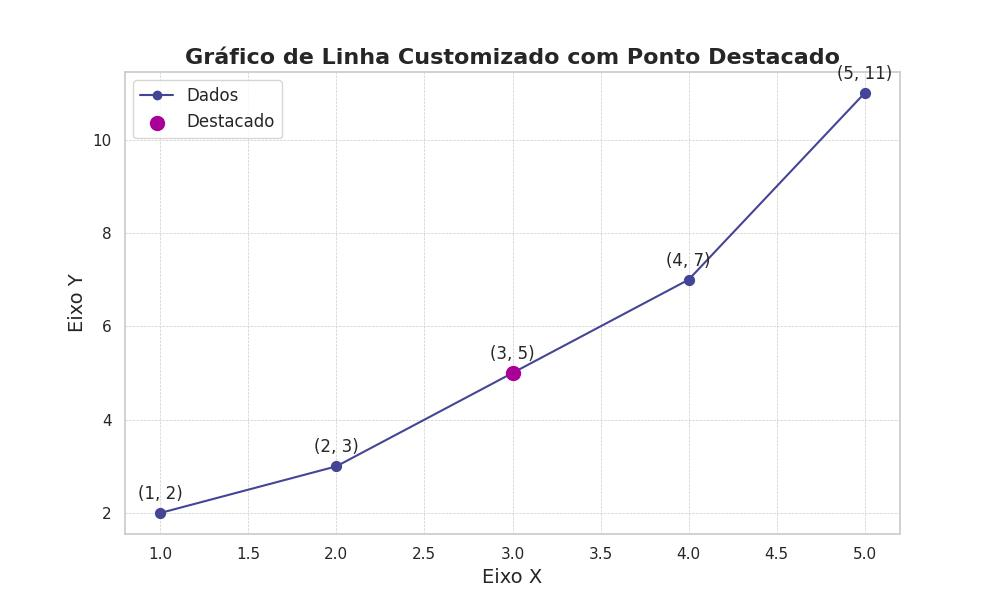
O código abaixo gera um gráfico bastante customizado, com legendas, destaques e estilização definidas através das utilidades das bibliotecas Matplotlib e Seaborn:
import matplotlib.pyplot as plt
import seaborn as sns
# Configuração do estilo do seaborn
sns.set(style="whitegrid")
# Dados para o gráfico
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# Criando o gráfico de linha com customizações
plt.figure(figsize=(10, 6))
plt.plot(x, y, marker='o', linestyle='-', color='#454598', label='Dados')
# Destacar um ponto específico (3, 5)
destaque = (3, 5)
# Adicionando todos os pontos, destacando um específico
for xi, yi in zip(x, y):
if (xi, yi) == destaque:
plt.scatter(xi, yi, color='#AA0098', s=100, zorder=5, label='Destacado')
else:
plt.scatter(xi, yi, color='#454598', s=50, zorder=3)
# Adicionando anotação a cada ponto
plt.annotate((xi, yi), (xi, yi), textcoords="offset points", xytext=(0,10), ha='center')
# Adicionando título e rótulos com customizações
plt.title('Gráfico de Linha Customizado com Ponto Destacado', fontsize=16, fontweight='bold')
plt.xlabel('Eixo X', fontsize=14)
plt.ylabel('Eixo Y', fontsize=14)
# Adicionando grade e legenda
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.legend(loc='upper left', fontsize=12)
# Exibindo o gráfico
plt.show()A figura abaixo representa o resultado do código:
Exemplos práticos de análise de dados em Python
Vamos agora passar por alguns exemplos práticos de análise de dados com Python. Todos os exemplos referenciam uma planilha no Google Sheets, portanto você pode testá-los no nosso Compilador de Python Online para ver a análise sendo feita em tempo real!
Como calcular a média de vendas por vendedor?
Para calcular a média de vendas por vendedor, utilizamos o método df.groupby() para agrupar por vendedor, selecionamos a coluna preco e usamos o método df.mean() nos dados agrupados:
# Importar as bibliotecas necessárias
import pandas as pd
# Carregar dados do Google Sheets
# Lendo um arquivo CSV (link do Google Sheets)
url = 'https://docs.google.com/spreadsheets/d/e/2PACX-1vQK--NNvKEZXxIhTN4LfmvWtwpltuLdjuKprimSRYSapRaqmPntNE6lKXug1l1VV2n1xEKuCPydmRnf/pub?output=csv'
df_vendas = pd.read_csv(url)
# Calcular a média de vendas por vendedor
# Agrupamos os dados por vendedor e calculamos a média dos preços dos produtos vendidos por cada vendedor
media_vendas_por_vendedor = df_vendas.groupby('vendedor')['preco'].mean()
# Imprimir a média de vendas por vendedor
print(media_vendas_por_vendedor)Com este código, obtemos a seguinte saída no terminal, demonstrando o valor médio de vendas por vendedor:
# vendedor
# João 173.583333
# Maria 136.833333
# Pedro 170.000000
# Name: preco, dtype: float64Como avaliar a distribuição de vendas ao longo das semanas?
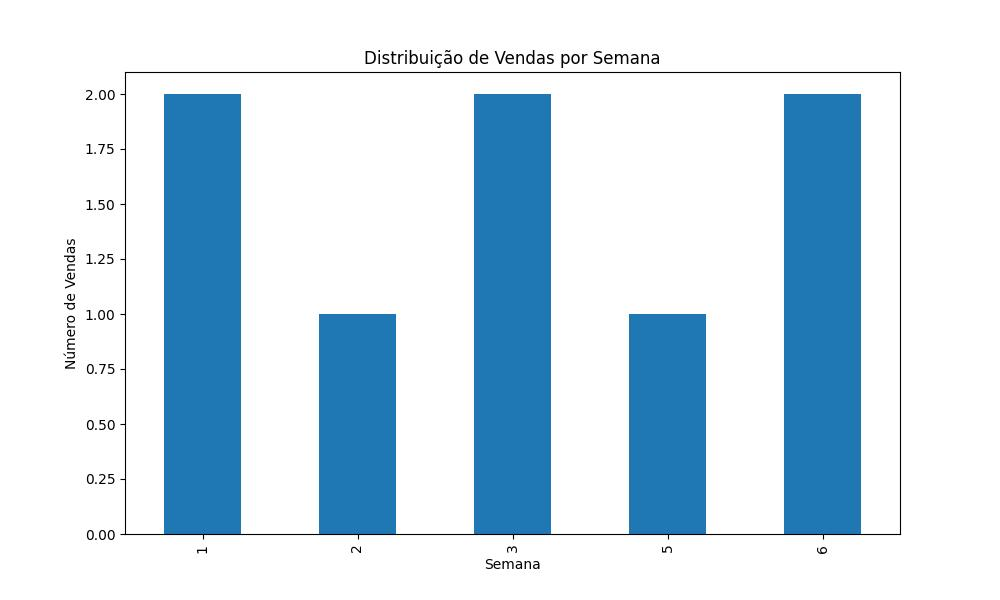
O código abaixo dá um número para cada semana nos dados e avalia quantas vendas foram feitas a cada semana:
import pandas as pd
import matplotlib.pyplot as plt
# Carregar dados do Google Sheets
url = 'https://docs.google.com/spreadsheets/d/e/2PACX-1vQK--NNvKEZXxIhTN4LfmvWtwpltuLdjuKprimSRYSapRaqmPntNE6lKXug1l1VV2n1xEKuCPydmRnf/pub?output=csv'
df_vendas = pd.read_csv(url, parse_dates=['data'])
# Adicionar uma coluna de semana
df_vendas['semana'] = df_vendas['data'].dt.strftime('%U').astype(int) # Extrair a semana do ano a partir da coluna de datas
# Ajustar a coluna 'semana' para lidar com o problema de semanas fora do intervalo típico
df_vendas['semana'] = df_vendas['semana'].apply(lambda x: x if x > 0 else 53)
# Agrupar e contar as vendas por semana
vendas_por_semana = df_vendas.groupby('semana').size() # Contar o número de vendas em cada semana
print(vendas_por_semana) # Imprimir o resultado do agrupamento
# Plotar a distribuição de vendas
plt.figure(figsize=(10, 6)) # Definir o tamanho da figura
vendas_por_semana.plot(kind='bar') # Criar um gráfico de barras
plt.title('Distribuição de Vendas por Semana') # Adicionar o título do gráfico
plt.xlabel('Semana') # Adicionar o rótulo do eixo x
plt.ylabel('Número de Vendas') # Adicionar o rótulo do eixo y
plt.show() # Mostrar o gráficoO código gera a seguinte figura, evidenciando o comportamento de vendas ao longo das semanas do ano:
Como plotar o volume mensal de vendas em um gráfico?
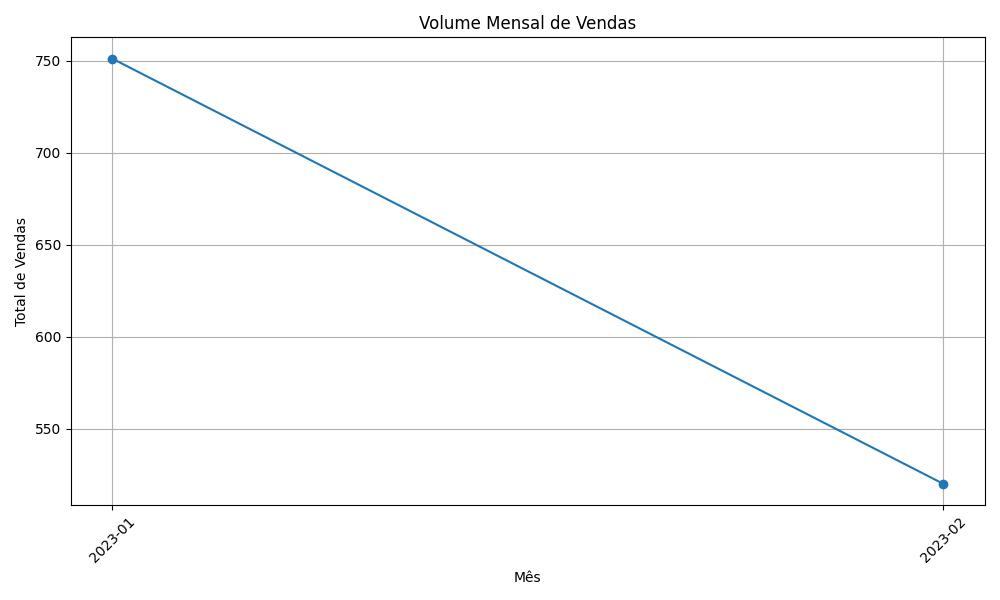
O código abaixo plota o volume mensal de vendas, o que ajuda a visualizar tendências e padrões ao longo do tempo:
# Importar as bibliotecas necessárias
import pandas as pd
import matplotlib.pyplot as plt
# Carregar dados do Google Sheets
url = 'https://docs.google.com/spreadsheets/d/e/2PACX-1vQK--NNvKEZXxIhTN4LfmvWtwpltuLdjuKprimSRYSapRaqmPntNE6lKXug1l1VV2n1xEKuCPydmRnf/pub?output=csv'
df_vendas = pd.read_csv(url, parse_dates=['data'])
# Adicionar uma coluna de mês
df_vendas['mes'] = df_vendas['data'].dt.to_period('M') # Extrair o mês a partir das datas
# Agrupar e somar as vendas por mês
vendas_por_mes = df_vendas.groupby('mes')['preco'].sum().reset_index() # Calcular o total de vendas por mês
# Plotar o volume mensal de vendas
plt.figure(figsize=(10, 6)) # Definir o tamanho da figura
plt.plot(vendas_por_mes['mes'].astype(str), vendas_por_mes['preco'], marker='o') # Criar um gráfico de linha com marcadores
plt.title('Volume Mensal de Vendas') # Adicionar o título do gráfico
plt.xlabel('Mês') # Adicionar o rótulo do eixo x
plt.ylabel('Total de Vendas') # Adicionar o rótulo do eixo y
plt.xticks(rotation=45) # Rotacionar os rótulos do eixo x para melhor leitura
plt.grid(True) # Adicionar grade ao gráfico
plt.tight_layout() # Ajustar layout para evitar sobreposição de elementos
plt.show() # Mostrar o gráficoE o gráfico gerado:
Conclusão
A análise de dados com Python é uma habilidade poderosa, que permite transformar dados brutos em informações valiosas. Vimos como Python é uma linguagem versátil e especialmente adequada para essa tarefa devido à sua sintaxe simples, bibliotecas especializadas e sua grande comunidade de suporte.
Além disso, exploramos vários conceitos e técnicas para trabalhar com dados em Python, sempre com exemplos de código completos. Mas, se você ficou com vontade de entender os códigos mais profundamente, recomendamos estudar pela nossa Trilha de Análise e Visualização de Dados, onde você aprende todo o conteúdo necessário para dominar as bibliotecas Pandas, Matplotlib, Seaborn e mais!
E, se você ainda está começando sua trajetória com Python, recomendamos assistir ao nosso curso gratuito, Python para iniciantes: do zero ao primeiro projeto, que te leva do zero absoluto ao primeiro dashboard em menos de duas horas. Bons estudos!
Comente e participe da conversa
Crie sua conta gratuita e compartilhe sua opinião nos comentários.
Entre para a Asimov