
Leia também:


A engenharia de dados é a área da tecnologia responsável por projetar, construir e manter a infraestrutura que coleta, armazena, organiza e distribui dados dentro de uma empresa.
Para entender melhor esse conceito, considere que os dados são um recurso natural, como a água. Nesse cenário, o engenheiro de dados seria o responsável por projetar os canos, filtros e reservatórios. Ou seja, ele cria todo o caminho para que a informação “flua” de forma limpa, organizada e acessível.
Seu trabalho permite que empresas de diversos setores, de e-commerces a hospitais, transformem informações dispersas em bases estruturadas e prontas para análise.
E isso vai muito além do big data. Qualquer negócio que deseja usar dados de forma estratégica depende dessa base sólida, como explica Daniel Alves, professor de engenharia de dados na Asimov Academy:
“A engenharia de dados desempenha uma função crucial nos ecossistemas empresariais modernos, facilitando a coleta, o armazenamento e a análise eficientes dos dados. Ela é essencial para a tomada de decisões informadas. A engenharia de dados não apenas otimiza os processos internos, mas também impulsiona a inovação e a competitividade no mercado.“
Por isso, em vez de lidar com planilhas manuais e dados desorganizados, as empresas recorrem a esses profissionais para desenvolver sistemas inteligentes que garantem que as informações certas cheguem, no momento ideal, para quem precisa.
Isso explica por que a procura por engenheiros de dados qualificados cresceu rapidamente, atraindo muitos profissionais interessados em migrar para a área. Mas será que essa é a carreira certa para você?
Para responder essa pergunta, neste artigo, você vai entender exatamente o que faz um engenheiro de dados, qual a formação desse profissional e como entrar nessa área, mesmo começando do zero.
O engenheiro de dados é o profissional responsável por criar e manter a infraestrutura que permite que as informações “circulem” de forma confiável e segura dentro de uma organização.
Na prática, isso significa desenhar pipelines de dados, escolher as ferramentas adequadas, garantir a qualidade da informação e manter tudo funcionando em larga escala.
Mas essa é apenas uma visão geral do seu trabalho. Conheça abaixo uma visão mais detalhada sobre as responsabilidades desse profissional:
Uma das principais funções desse engenheiro é automatizar a entrada de dados coletados por APIs, sistemas internos, bancos de dados, entre outras fontes. Além de automatizar esse fluxo, ele também precisa estruturar os dados de forma que possam ser armazenados com segurança e escalabilidade.
O DataOps ajuda nesse processo, facilitando o acesso às informações e garantindo a integridade dos dados mesmo com o crescimento do volume e complexidade.
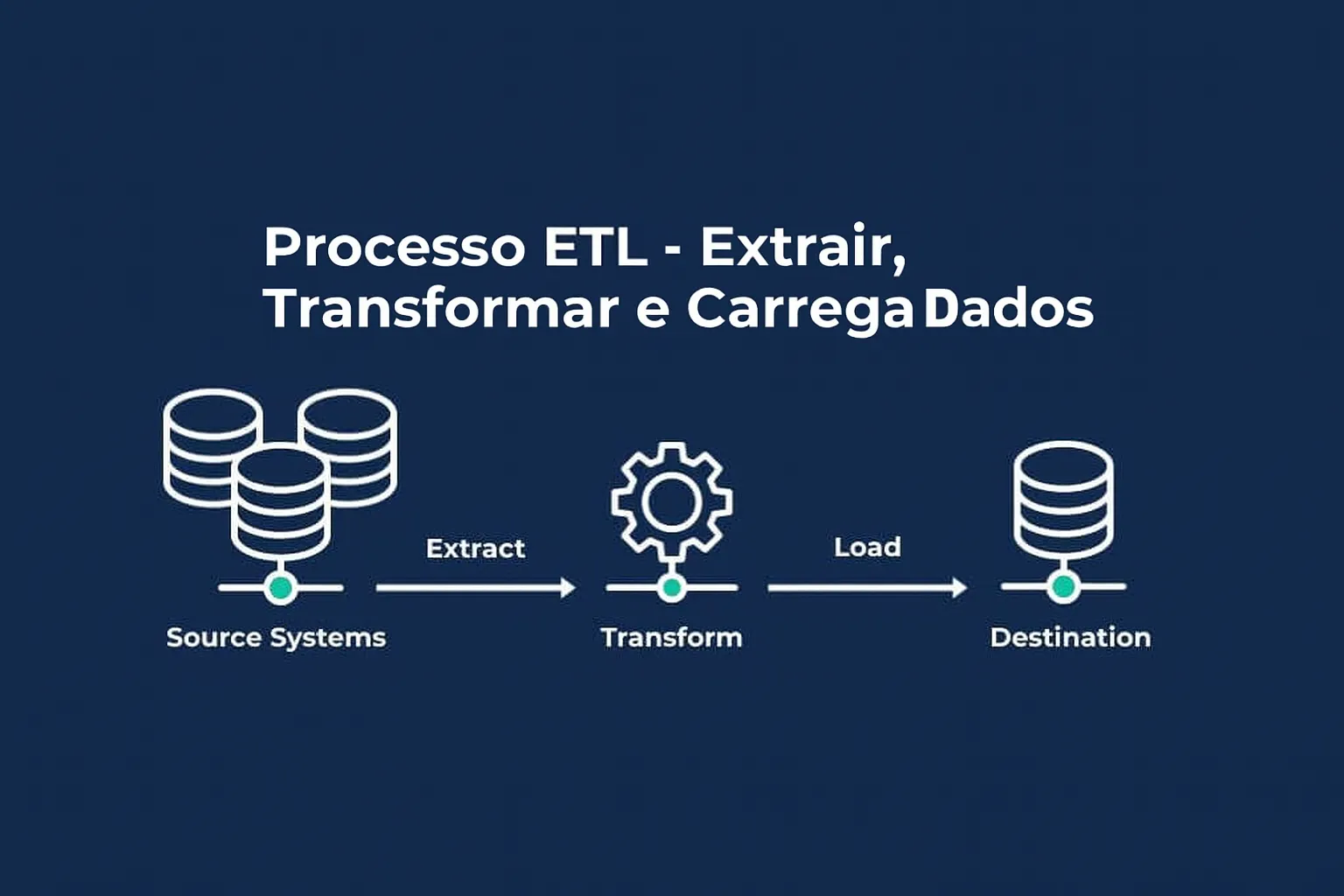
Os pipelines são fluxos automatizados que transportam dados de suas fontes originais até os sistemas onde serão armazenados e analisados. Esse processo envolve três etapas principais:
Dependendo da ordem em que essas etapas são executadas, o processo recebe o nome de ETL (Extract, Transform, Load) ou ELT (Extract, Load, Transform).
Projetar esses fluxos é uma das tarefas mais criativas e desafiadoras da engenharia de dados. Afinal, é nesse momento que se define como as informações vão circular com segurança, eficiência e escalabilidade dentro da empresa.
O engenheiro também prepara e estrutura os conjuntos de dados que alimentam os modelos de inteligência artificial (IA), garantindo que cheguem aos cientistas de dados no formato ideal para treinamento, validação e ajustes de projetos de machine learning.
Sem uma boa engenharia de dados, os sistemas de IA tendem a apresentar falhas ou resultados imprecisos. Afinal, a qualidade dos modelos depende diretamente da qualidade dos dados utilizados.
Pipelines de dados eficientes permitem a atualização e análise das informações praticamente em tempo real.
Os engenheiros de dados são os responsáveis por criar e manter esses sistemas que alimentam dashboards de business intelligence (BI), painéis operacionais e modelos analíticos com dados atualizados e confiáveis. Tudo isso, muitas vezes, com apenas alguns segundos de latência.
Na prática, esse trabalho torna possível analisar dados no momento em que são gerados. Essa capacidade é importante para aplicações como monitoramento de transações financeiras, em que a detecção instantânea de fraudes pode prevenir prejuízos.
Veja também: Análise exploratória de dados: descobrindo padrões e tendências

Não adianta ter uma grande quantidade de dados se eles estiverem cheios de erros, duplicações ou inconsistências. Por isso, o engenheiro deve garantir a qualidade dessas informações, implementando validações automáticas que detectam e corrigem problemas ao longo de todo o pipeline.
Esse processo deve continuar mesmo com o crescimento no volume de dados. Nesse cenário, esses profissionais devem otimizar processos, identificar gargalos, melhorar o tempo de resposta e garantir estabilidade, mesmo em ambientes com milhões de registros diários.
Também faz parte da rotina do engenheiro monitorar os pipelines e resolver falhas quando elas ocorrem. Isso inclui configurar alertas, acompanhar painéis de controle e atuar proativamente na resolução de incidentes.
Em muitas equipes, esse trabalho envolve plantões e suporte contínuo, já que a saúde dos sistemas de dados é essencial para o funcionamento da empresa como um todo.
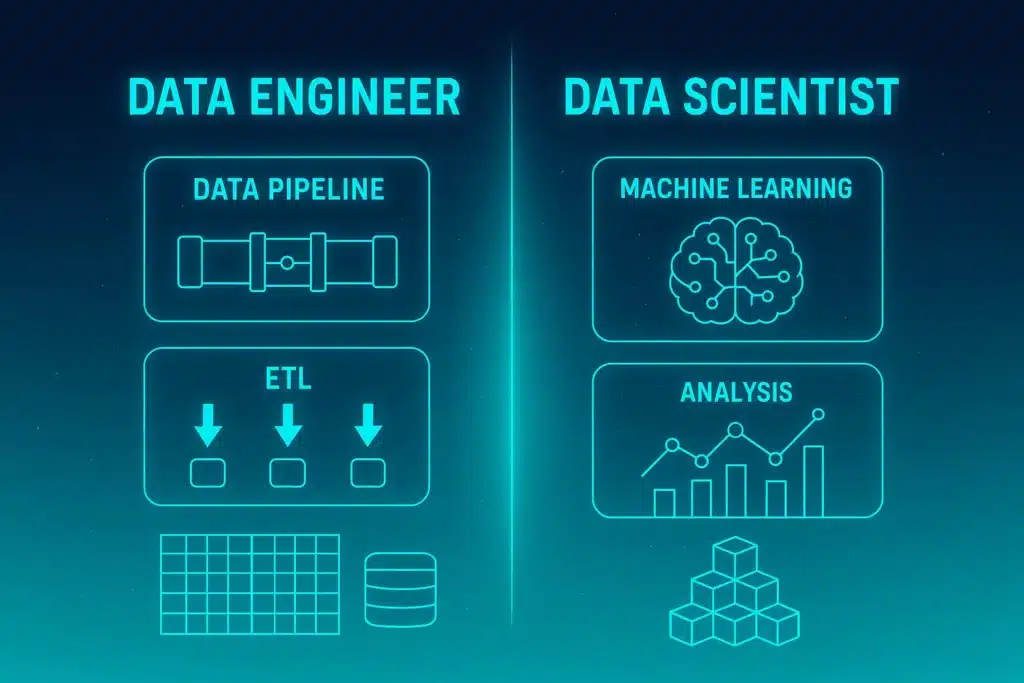
O cientista de dados é o profissional que analisa os dados em busca de padrões, tendências e respostas para problemas do negócio. Ele desenvolve modelos preditivos com machine learning, testa hipóteses, limpa e transforma os dados para gerar insights que apoiam a tomada de decisão.
Por isso, quem atua nessa área costuma ter um perfil mais voltado para pesquisa, matemática, estatística e inteligência artificial. Ou seja, a ciência de dados é ideal para quem gosta de explorar informações em profundidade e criar soluções baseadas nelas.
Já o engenheiro de dados é quem constrói toda a infraestrutura que torna esse trabalho possível. Ele projeta os sistemas responsáveis por coletar, armazenar, organizar e entregar os dados de forma confiável e em escala. Seu foco está na performance, segurança e escalabilidade dos pipelines.
Ou seja, é ele quem garante que o cientista de dados tenha acesso às informações corretas, no formato adequado e no momento certo.
Na prática, engenheiros e cientistas de dados trabalham em conjunto, com objetivos complementares. Um depende do outro e, juntos, constroem soluções completas.

A engenharia de dados é uma das áreas mais promissoras da tecnologia, combinando habilidades técnicas avançadas com impacto direto nos negócios. Se você quiser seguir essa carreira, confira estas dicas:
Não existe uma formação obrigatória para se tornar engenheiro de dados. Embora muitos profissionais tenham formação em ciência da computação, engenharia da computação, sistemas de informação ou áreas afins, esse não é um pré-requisito.
O que realmente importa é dominar as ferramentas, linguagens e conceitos técnicos exigidos pela função. Esse conhecimento pode ser adquirido por meio de cursos práticos, bootcamps, certificações ou formações específicas voltadas para a área, como a Trilha de Engenharia de Dados, da Asimov Academy.
O engenheiro de dados precisa dominar tanto os fundamentos da computação quanto as ferramentas modernas que compõem o ecossistema de dados.
Isso significa entender desde como funciona um banco de dados até como orquestrar pipelines complexos em nuvem. Para isso, esse profissional precisa desenvolver habilidades como:
Além do domínio técnico, o sucesso na engenharia de dados também depende de um conjunto de soft skills (habilidades comportamentais) que ajudam o profissional a lidar com os desafios do dia a dia.
Uma das mais importantes é o raciocínio lógico aliado ao pensamento estruturado. Essa combinação é importante para construir pipelines eficientes e resolver problemas em sistemas complexos.
Também é fundamental saber trabalhar em equipe e se comunicar com clareza, inclusive com pessoas que não são da área de dados. Afinal, o engenheiro precisa atuar em conjunto com cientistas de dados, analistas de BI, engenheiros de software e gestores de produto.
Lidar com falhas, bugs, dados inconsistentes ou pipelines interrompidos também faz parte da rotina. Por isso, é importante ter proatividade para investigar e resolver problemas rapidamente. Ser uma pessoa organizada e atenta aos detalhes faz toda a diferença nesse processo.
E não dá para falar em carreira em tecnologia sem mencionar o aprendizado contínuo. O ecossistema de dados está em constante evolução, com novas ferramentas, padrões e linguagens surgindo o tempo todo.
Por isso, se você realmente deseja seguir carreira como engenheiro de dados, precisa estar disposto a se atualizar, estudar e testar novas soluções. Esse espírito de aprendizado constante é o que permite crescer na profissão e acompanhar a velocidade do mercado.


A carreira em engenharia de dados está entre as mais promissoras do setor de tecnologia, o que também se reflete nos salários.
Segundo o Guia Salarial 2024, da Robert Half, esse profissional está entre os mais procurados pelas empresas e, ao mesmo tempo, entre os mais difíceis de encontrar, o que valoriza ainda mais sua remuneração.
De acordo com o levantamento, a média salarial para engenheiros de dados com experiência intermediária gira em torno de R$ 24,1 mil por mês.
Já os profissionais mais experientes, com certificações e especializações, podem ultrapassar essa faixa, chegando a salários semelhantes aos de cargos de liderança, como gerentes de dados, que ganham entre R$ 21,6 mil e R$ 36,1 mil mensais.
No entanto, esses valores variam bastante conforme o nível de experiência. Profissionais em início de carreira ou em cargos de entrada, como analista de dados ou engenheiro júnior, costumam ganhar entre R$ 5 mil e R$ 7 mil, segundo dados da plataforma Glassdoor.
Ou seja, você pode começar com salários mais modestos, mas à medida que adquire prática, domínio técnico e experiência com projetos em escala, sua remuneração tende a crescer junto com a sua carreira.
Vale lembrar que, com o avanço da IA, do machine learning e do uso estratégico de dados nos negócios, a tendência é que a demanda por engenheiros de dados continue aumentando.
Isso deve elevar o número de oportunidades de crescimento profissional e financeiro para quem seguir nessa área.
Como vimos, a engenharia de dados é uma das áreas mais promissoras da atualidade. E dominar Python é o primeiro passo para construir uma carreira sólida nesse campo.
Além de ser uma das linguagens mais utilizadas por engenheiros, Python é fácil de aprender, tem uma comunidade ativa e oferece diversas bibliotecas para criar pipelines, automatizar processos ETL e integrar ferramentas.
A boa notícia é que você não precisa de uma formação tradicional para começar a estudar. Na Trilha Engenharia de Dados com Python, da Asimov Academy, você aprende praticando com projetos reais e uma estrutura de ensino com foco total no mercado de trabalho
Nela, você vai dominar as principais ferramentas, entender como funcionam os pipelines de dados, aprender a trabalhar com SQL, Python, cloud e muito mais. Tudo isso de forma prática, acessível e orientada para resultados!
Comece hoje mesmo e dê o primeiro passo para mudar o seu futuro!

Domine os fundamentos da Engenharia de Dados e construa seu primeiro pipeline com Python, ETL, Airflow e deploy na nuvem.
Comece agora
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:



Comentários
30xpExcelente artigo. Acredito que seguirei essa profissão em breve, se Deus quiser. Vou seguir a trilha de aprendizado da Asimov. Valeu demais. Sucesso a todos !
Show! Obrigado pelo feedback, sucesso! 👏