


Um pipeline de dados é uma série de etapas interligadas que processam dados desde a sua origem até um destino final para análise ou uso em aplicações. Ele começa com a ingestão dos dados brutos, que podem vir de várias fontes, como bancos de dados, sistemas, arquivos ou APIs, passa por uma sequência de transformações para limpar, organizar, padronizar e modificar esses dados, e termina com o armazenamento em locais como data lakes, data warehouses ou sistemas analíticos.
Além disso, pipelines de dados podem operar de duas formas principais:
- Processamento em lote: dados são coletados e processados em blocos em horários programados.
- Processamento em streaming: dados são processados em tempo real conforme são gerados, ideal para análises rápidas e detecção imediata de eventos (ex.: fraudes financeiras).
Os principais componentes de um pipeline de dados incluem:
- Fontes de dados: onde os dados são coletados (exemplo: APIs, bancos de dados, sensores);
- Processamento e transformação: limpeza, filtragem, agregações, validações e outras alterações para tornar os dados úteis;
- Destino: local onde os dados processados são armazenados, como um data warehouse, data lake ou sistemas de BI.
Como funciona um pipeline de dados?
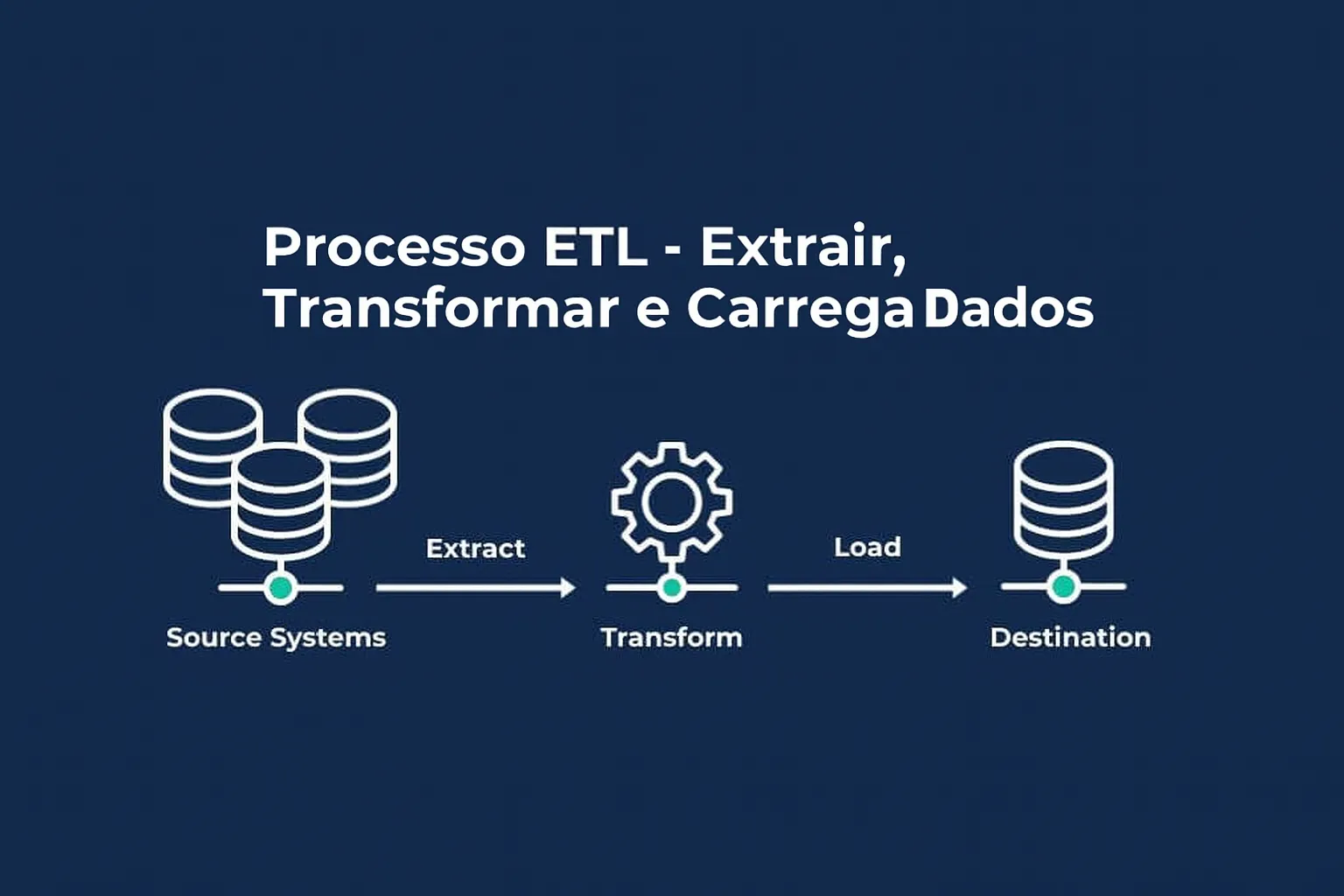
Um pipeline de dados funciona por meio de uma sequência organizada de etapas automatizadas que garantem que os dados sejam extraídos, transformados, carregados e orquestrados de forma eficiente para uso em análises ou aplicações. Cada etapa tem um papel específico:
Extração (Extract):
Nessa etapa, os dados são coletados de diversas fontes, que podem incluir bancos de dados, APIs, sistemas legados, dispositivos IoT, arquivos, entre outros. A extração pode ocorrer tanto em tempo real (streaming) quanto em lotes programados, dependendo da necessidade do projeto.
O objetivo é capturar os dados brutos, muitas vezes em formatos diversos e não padronizados, para que possam ser processados a seguir.
Transformação (Transform):
Após a extração, os dados passam por transformações que visam torná-los úteis e consistentes. Isso inclui limpeza (remoção de dados inválidos ou duplicados), filtragem, validação, agregações, normalização, reformatação e enriquecimento dos dados. Essa etapa garante a qualidade, integridade e padronização, preparando os dados para análise e armazenamento apropriado.
Técnicas comuns de transformação incluem:
- Limpeza de dados: remover dados incorretos ou irrelevantes.
- Normalização: ajustar os dados para um formato padrão.
- Agregação: resumir dados em um formato mais útil, como calcular médias ou totais.
Exemplo de transformação em Python:
import pandas as pd
# Dados mock simplificados
data = pd.DataFrame({
'valor': ['$1,000.50', '$2,500.75', '$3,000.00']
})
# Limpeza e conversão
data['valor'] = data['valor'].replace({'\$': '', ',': ''}, regex=True).astype(float)
print(data)Neste exemplo, estamos usando o método replace do Pandas, que aceita expressões regulares (regex=True), para remover o símbolo de dólar ($) e as vírgulas de uma coluna de valores, convertendo-a para tipo numérico (float).
É importante saber que a função replace das strings do Python é diferente e não aceita regex, por isso, esse tipo de substituição só funciona com objetos do Pandas (como uma coluna de um DataFrame).
Saída esperada:
valor
0 1000.50
1 2500.75
2 3000.00
Carga (Load):
Depois de transformados, os dados são carregados para um destino final, que pode ser um data warehouse, data lake, banco de dados analítico ou sistemas de BI. O carregamento pode ser incremental ou completo, e o destino escolhido vai depender do uso final dos dados.
Esta etapa assegura que os dados estejam disponíveis para consultas, análises e visualizações de forma acessível e eficiente.
Orquestração:
A orquestração é a coordenação e automação das diversas etapas do pipeline, garantindo que cada tarefa ocorra na ordem correta e no momento certo. Ela gerencia dependências (por exemplo, esperar a finalização da extração antes de iniciar a transformação), lida com falhas, escalonamento e monitoramento do processo completo.
Ferramentas de orquestração, como Apache Airflow, são frequentemente utilizadas para automatizar e monitorar esses processos, garantindo que os dados fluam de maneira eficiente e sem interrupções.
Ferramentas mais usadas para criar pipelines de dados
As ferramentas mais usadas para criar pipelines de dados em 2025 podem ser agrupadas conforme as etapas do pipeline: orquestração, transformação, armazenamento e extração.
Destaco as principais ferramentas recomendadas para cada categoria, com base em análises recentes do mercado:
Orquestração
Apache Airflow, Prefect e Dagster são referências para orquestração de pipelines, automatizando e controlando fluxos de trabalho. Também tem outras plataformas como AWS Glue e Azure Data Factory que oferecem um tipo de orquestração mais robusta.
Transformação
O dbt (data build tool) é usado para transformações declarativas focadas em modelagem e testes de dados. Bibliotecas como Pandas continuam populares para manipulação de dados em Python, especialmente em pipelines personalizados e análises exploratórias.
Armazenamento
Bancos de dados relacionais como PostgreSQL são comuns para armazenar dados estruturados. Para escalabilidade e análise de grandes volumes, soluções na nuvem como Google BigQuery, Amazon S3 e Azure Data Lake são as melhores adotadas por sua performance e integração com outras ferramentas.
Extração
A extração de dados pode acontecer por meio de APIs, que permitem o acesso a dados de aplicações externas, ou por meio de consultas SQL, usadas em bancos de dados relacionais — ambas são abordagens fundamentais em pipelines de dados modernos.
Tipos de pipeline: ETL x ELT
| Aspecto | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Ordem das etapas | Extrai os dados, transforma-os em um servidor intermediário, depois os carrega para o destino final. | Extrai os dados, carrega-os diretamente no destino final (data warehouse) e depois realiza a transformação nele. |
| Local da transformação | Servidor de processamento separado antes da carga. | Dentro do próprio data warehouse ou repositório de dados. |
| Velocidade | Geralmente mais lento na ingestão, pois transforma antes de carregar. | Mais rápido na ingestão, pois carrega dados brutos e transforma depois, podendo transformar em paralelo. |
| Armazenamento dos dados brutos | Normalmente não retém todos os dados brutos após a transformação. | Armazena dados brutos de forma permanente, permitindo reutilização e novas transformações. |
| Adequação de dados | Mais adequado para dados estruturados e processos predefinidos. | Lida bem com dados estruturados, semiestruturados e não estruturados. |
| Dependência técnica | Transformações são feitas por engenheiros de dados antes do carregamento. | Permite que analistas e cientistas de dados realizem transformações após o carregamento. |
| Uso típico | Tradicional, criado na década de 1970, ainda usado em muitos processos. | Mais moderno, comum em arquiteturas cloud e processamento em grande escala. |
| Complexidade | Pode exigir mais infraestrutura para o processamento intermediário. | Aproveita poder computacional dos data warehouses modernos, reduzindo infraestrutura. |
Por que pipelines de dados são fundamentais para a engenharia de dados?
Pipelines de dados são fundamentais porque automatizam o caminho que os dados percorrem — desde a coleta até a entrega final.
Eles ajudam o engenheiro de dados a economizar tempo com tarefas repetitivas e a focar no que realmente importa: gerar insights e soluções para o negócio.
Com os pipelines, os dados passam por validações que garantem qualidade, corrigem erros e evitam informações duplicadas ou fora do padrão.
Também são essenciais para juntar dados de várias fontes, acabando com os chamados “silos de dados”, e garantindo que tudo fique centralizado e padronizado.
Além disso, permitem que os dados cheguem com mais velocidade para análises, decisões em tempo real e uso em modelos de machine learning.
No fim das contas, os pipelines tornam as operações mais eficientes, reduzem erros e transformam dados em um recurso estratégico que ajuda a empresa a crescer e inovar e por isso que ela é fundamental para a engenharia de dados.
6 desafios na criação de pipelines de dados
Com o crescimento acelerado dos dados e a pressão por decisões rápidas e precisas, manter um pipeline de dados eficiente virou uma necessidade em muitas empresas. No entanto, esse processo ainda enfrenta vários desafios técnicos, operacionais e organizacionais.
Alguns dos principais pontos que exigem atenção são:
1. Falta de integração entre fontes diferentes
Um dos primeiros desafios é reunir dados que vêm de sistemas distintos, cada um com seu próprio formato. Por exemplo, um sistema pode usar “dd/mm/aaaa” para datas, outro pode usar “mm-dd-aaaa”, e isso já bagunça tudo.
Sem um processo de padronização automática dentro do pipeline, é impossível consolidar os dados corretamente.
2. Pipeline sem validação de dados
Se os dados entram com erro e não há uma etapa de verificação, o resultado final será incorreto. Um pipeline eficiente precisa ter uma validação constante, senão você pode tomar decisões com base em informações quebradas, como um valor de venda negativo ou um campo de e-mail vazio.
3. Escalabilidade limitada
Com o volume de dados alto, o pipeline precisa ser capaz de escalar.
Quando ele não é estruturado para rodar na nuvem, por exemplo, pode travar ou ficar lento. Isso acontece quando a arquitetura não foi pensada para ambientes distribuídos, o que pode ser um entrave para empresas que ainda operam com sistemas locais.
4. Falta de um bom gerenciamento de metadados
Sem um gerenciador de metadados, não dá pra saber de onde vieram os dados, quais transformações eles sofreram e quem acessou o quê.
Isso dificulta auditorias e coloca em risco o compliance com leis como a LGPD. Um pipeline robusto precisa de rastreabilidade clara.
5. Dados desatualizados
Muitos pipelines não foram construídos para processar dados em tempo real, eles só funcionam em lotes.
Isso é um problema para áreas como logística ou finanças, que precisam de decisões na hora, com base em dados que acabaram de chegar.
6. Pouco controle de regras de negócio
Quando o pipeline não possui uma camada clara para aplicar regras de negócio (como limites de crédito, por exemplo), tudo fica descentralizado e sujeito a erro.
O resultado? Gera inconsistência nos relatórios e nas análises, já que cada etapa pode aplicar regras diferentes sem padrão.
Como aprender a construir pipelines de dados com Python do zero
Se você chegou até aqui, já entendeu a importância dos pipelines de dados na Engenharia de Dados. Agora, é hora de aprender a construir os seus, do zero. Pensando nisso, criamos uma trilha completa e prática para quem quer entrar de verdade nesse universo e começar a atuar com dados de forma profissional.
O que é a Trilha Engenharia de Dados da Asimov?
É um caminho de aprendizado organizado, que vai te ensinar tudo o que você precisa, desde o básico da programação até a construção, automação e deploy de pipelines de dados em ambientes reais.
Tudo com foco na prática e na aplicação no dia a dia de quem trabalha com dados.
Para quem é essa trilha?
- Para quem está começando do zero;
- Para quem vem de outra área e quer migrar para dados;
- Para quem já programa, mas quer aprender a montar pipelines de verdade.
Comece agora mesmo a Trilha de Engenharia de Dados e transforme seu conhecimento em prática, e sua prática em carreira.

Trilha Engenharia de Dados
Domine os fundamentos da Engenharia de Dados e construa seu primeiro pipeline com Python, ETL, Airflow e deploy na nuvem.
Comece agoraPerguntas frequentes sobre pipelines de dados
Como os pipelines são utilizados em Big Data e ciência de dados?
Os pipelines de dados são fundamentais em projetos de Big Data, pois permitem que grandes volumes de dados sejam processados e analisados de maneira eficiente. Eles ajudam a garantir que os dados estejam sempre atualizados e prontos para análise, permitindo que cientistas de dados e analistas tomem decisões informadas.
Quais são os desafios comuns na implementação de pipelines?
Alguns dos desafios comuns incluem a integração de dados de diferentes fontes, a garantia da qualidade dos dados e a necessidade de monitoramento contínuo para identificar e corrigir problemas rapidamente.
Como garantir a qualidade e a segurança dos dados em um pipeline?
Para garantir a qualidade dos dados, é importante implementar etapas de validação e limpeza durante o processo de transformação. Além disso, a segurança dos dados pode ser garantida através de políticas de governança e controle de acesso.
Você também pode gostar:






Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xpComo seria mais ou meno um pipeline no setor Eólico, mais precisamente na área de automação industrial. O que poderia ser coletado com um pipeline e poderia prever falha nos equipamentos? Ou poderia ter um pipeline de gastos por setor ou algo do tipo, poderiam me explicar melhor onde seria mais bem aplicado?
Temos um desafio de Data-driven, mas não sei como começar em meu setor, onde conseguiria uma ajuda de vocês?
Bom dia, Igor!
Esse tipo de questão sobre aplicação de pipelines em setores específicos, como o eólico, foge um pouco do escopo das dúvidas que costumamos responder. Mas caso tenha dúvidas ligadas diretamente ao conteúdo do blog sem ser em casos específicos, pode contar comigo que vou te ajudar no que for preciso 🚀