
Leia também:
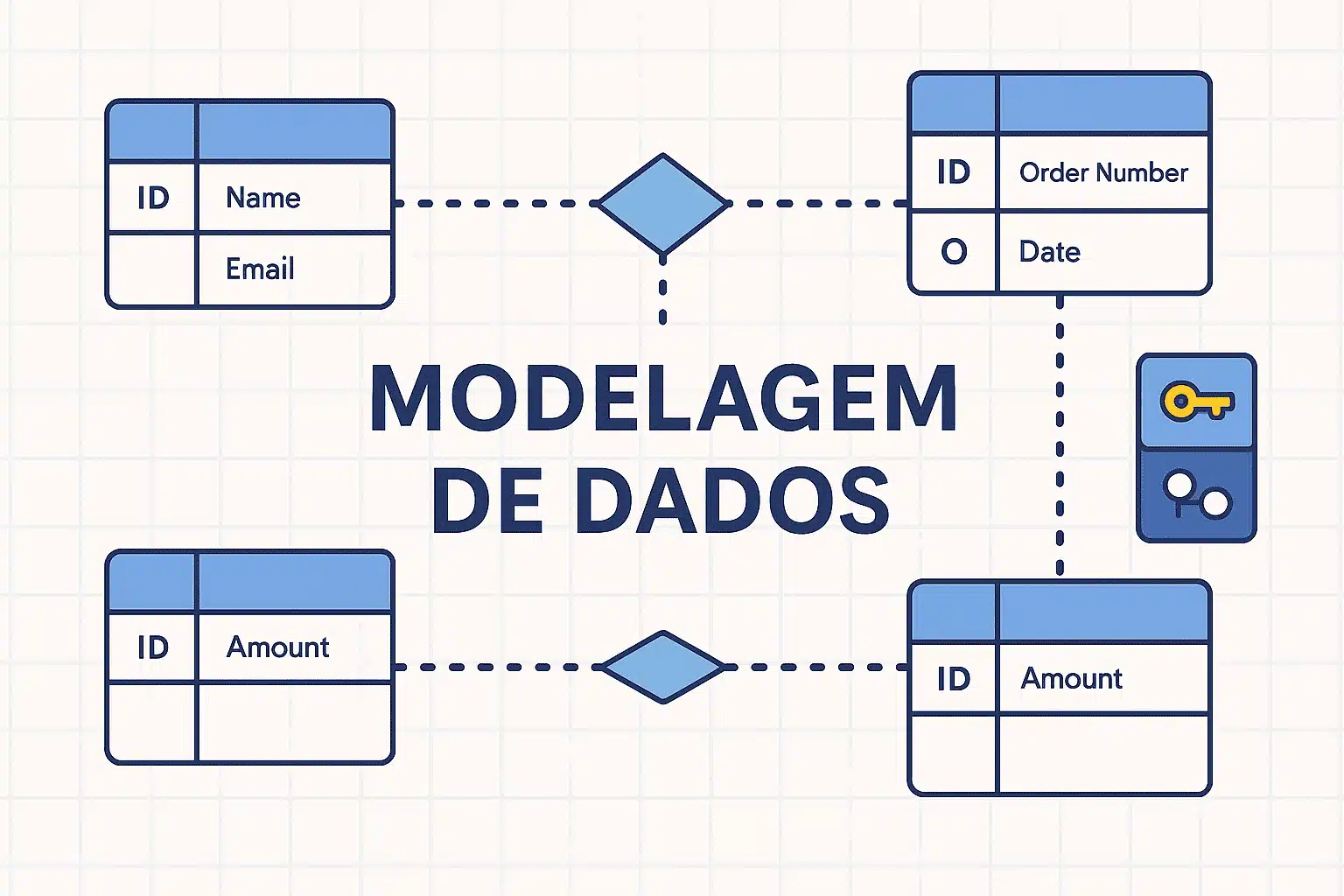

A modelagem de dados é o processo de planejar e representar visualmente como as informações de um sistema se conectam e são armazenadas. Pense nela como um mapa da informação. Antes de criar o banco de dados, você define o caminho que cada dado vai seguir, como eles se relacionam e onde serão guardados. Isso é modelagem.
A modelagem atua como um sistema de freios e contrapesos, evitando que informações incorretas ou inconsistentes entrem na base de dados. Na prática, ela define regras que garantem que, por exemplo:
Essas validações automáticas preservam a integridade do sistema e reduzem erros que podem comprometer a operação.
Quantas vezes você já viu “SP”, “S.Paulo”, “São Paulo” e “sao paulo” no mesmo sistema?
A modelagem resolve isso ao criar padrões claros para que todos usem os mesmos formatos e termos.
Assim, os times passam a falar a mesma língua, o que reduz retrabalho, falhas de comunicação e inconsistências nas análises.
Uma boa modelagem permite que o sistema cresça sem problemas que prejudiquem seu funcionamento. Por isso, você pode adicionar novas tabelas, dados ou funcionalidades sem prejudicar o que já existe.
Dados bem estruturados são mais fáceis de consultar, cruzar e transformar em insights. Essa base sólida sustenta o trabalho de analistas, engenheiros e cientistas de dados, permitindo decisões baseadas em fatos, não em achismos.
A modelagem de dados também acontece em três etapas, as quais garantem que o projeto saia do papel sem surpresas: modelagem conceitual, lógica e física.
Cada uma delas resulta em um modelo (o produto final da etapa), que pode ser um diagrama, um esquema ou um documento que mostra como os dados estão organizados.
Esses modelos funcionam como um mapa visual para quem vai implementar ou consultar o banco de dados.
Veja o que acontece em cada etapa:

Esta é a primeira fase da modelagem. Ela consiste na construção de um modelo que representa o que o sistema precisa conter, como os dados se relacionam e quais regras de negócio precisam ser respeitadas.
Nesta etapa, ainda não é necessário pensar na tecnologia aplicada ao processo. Em vez disso, é importante responder perguntas como:
Nesta fase, o modelo começa a ganhar detalhes técnicos. A modelagem lógica define atributos, tipos de dados, chaves primárias e estrangeiras e os relacionamentos formais entre as entidades.
Ainda não é o momento de escolher o sistema que será utilizado (como MySQL ou MongoDB). O objetivo aqui é deixar os dados organizados e coerentes, de forma que o modelo possa ser implementado em qualquer tecnologia de banco de dados.
A etapa física é onde o projeto se torna real. Tudo o que foi planejado antes é implementado no banco de dados, com tabelas, colunas, tipos específicos de dados e índices de performance.
É nessa fase que os engenheiros de dados definem como e onde os dados serão armazenados, considerando o tipo de banco (SQL ou NoSQL) e otimizando o desempenho do sistema.
| Etapa | Objetivo principal | Quem participa | Material entregue |
|---|---|---|---|
| Conceitual | Regras e necessidades do negócio | Analistas e stakeholders | Diagrama simples de entidades e relacionamentos |
| Lógica | Estrutura e relacionamentos técnicos | Analistas e engenheiros de dados | Esquema detalhado com chaves e tipos de dados |
| Física | Implementação no banco de dados | Engenheiros e desenvolvedores | Script SQL ou estrutura NoSQL implementada |

As técnicas de modelagem de dados são diferentes maneiras de representar como as informações se conectam dentro de um sistema. E cada uma delas atende a uma necessidade específica.
Conheça as principais abordagens e quando utilizá-las.
Criada na década de 1960, a modelagem hierárquica foi uma das primeiras formas de representar dados. Ela organiza as informações em uma estrutura de árvore. Cada registro “pai” pode ter vários “filhos”, mas cada filho pertence apenas a um pai, ou seja, o relacionamento é sempre do tipo um-para-muitos.
Por ser simples e direta, ela é indicada para a construção de estruturas previsíveis, como:
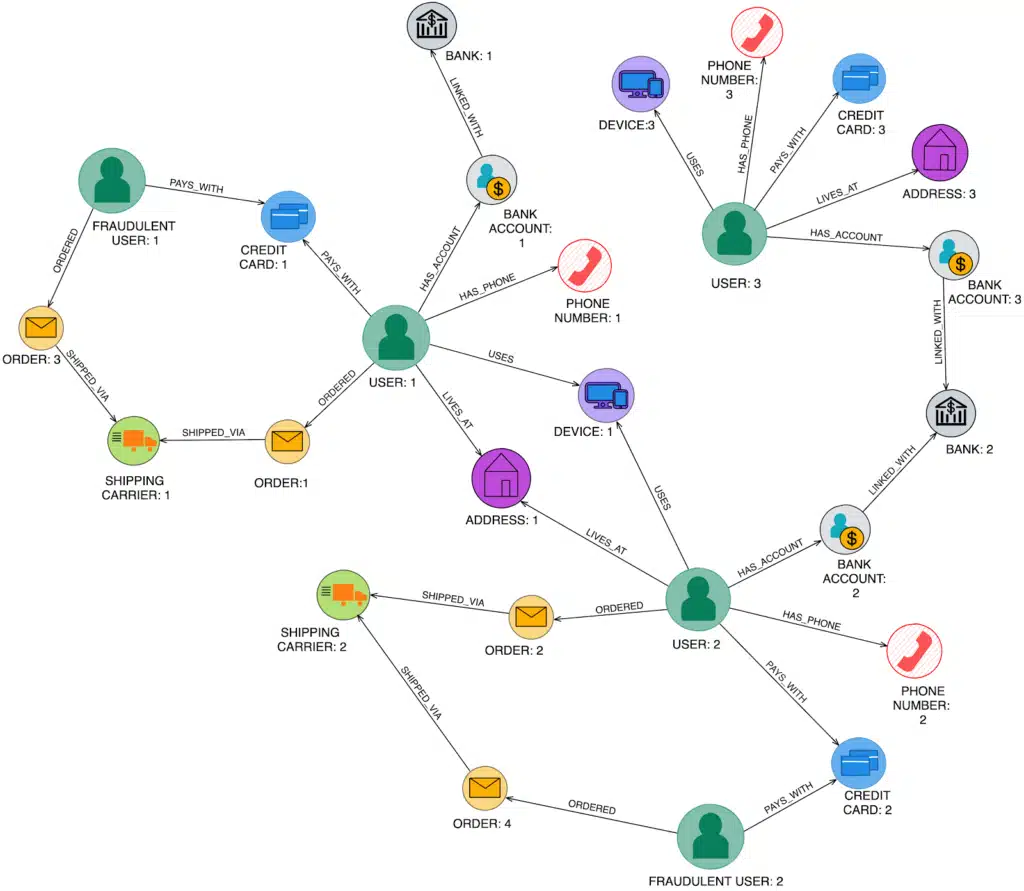
A modelagem de grafos foi criada para superar as limitações do modelo hierárquico. Nesse formato, todas as entidades são tratadas de forma igualitária, como nós conectados por arestas que representam os relacionamentos entre elas.
Assim, os dados formam uma rede de conexões, estrutura ideal para representar relações complexas e dinâmicas. Afinal, um nó pode se conectar a quantos outros forem necessários. Por isso, esse modelo é muito utilizado na construção de sistemas como:

A modelagem Entidade-Relacionamento (ER) é a técnica mais conhecida e usada na área de dados. Ela serve de base para os bancos SQL e se concentra em três elementos principais:
Esses três elementos formam diagramas visuais que ajudam a entender como os dados se encaixam no sistema. Na prática:
Por garantir estrutura clara, eliminar redundâncias e assegurar a integridade dos dados, o modelo ER é o ponto de partida da maioria dos bancos de dados corporativos, usados em ERPs, CRMs, plataformas financeiras e e-commerces.
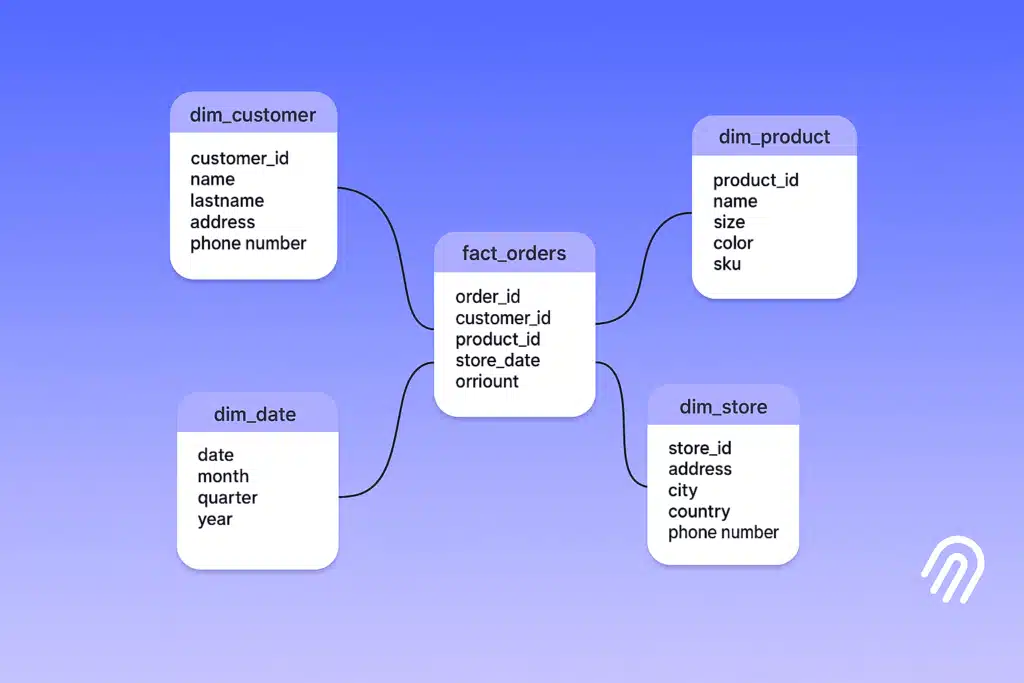
A modelagem dimensional é voltada para analisar tendências e extrair insights estratégicos. Por isso, ela é considerada a análise de dados e do Business Intelligence (BI).
Nesta técnica, as informações são divididas em duas categorias:
Normalmente, quem usa essa técnica gera um esquema em estrela, em que a tabela de fatos fica no centro e as dimensões se conectam a ela. Essa organização facilita a criação de relatórios e dashboards em ferramentas como Power BI e Tableau, tornando as consultas mais rápidas e intuitivas.
Por ser simples e otimizada para leitura, a modelagem dimensional é muito utilizada em:
Ela também é a base de várias ferramentas modernas de análise, como dbt, Power BI e Snowflake, que ajudam empresas a transformar dados em conhecimento estratégico.

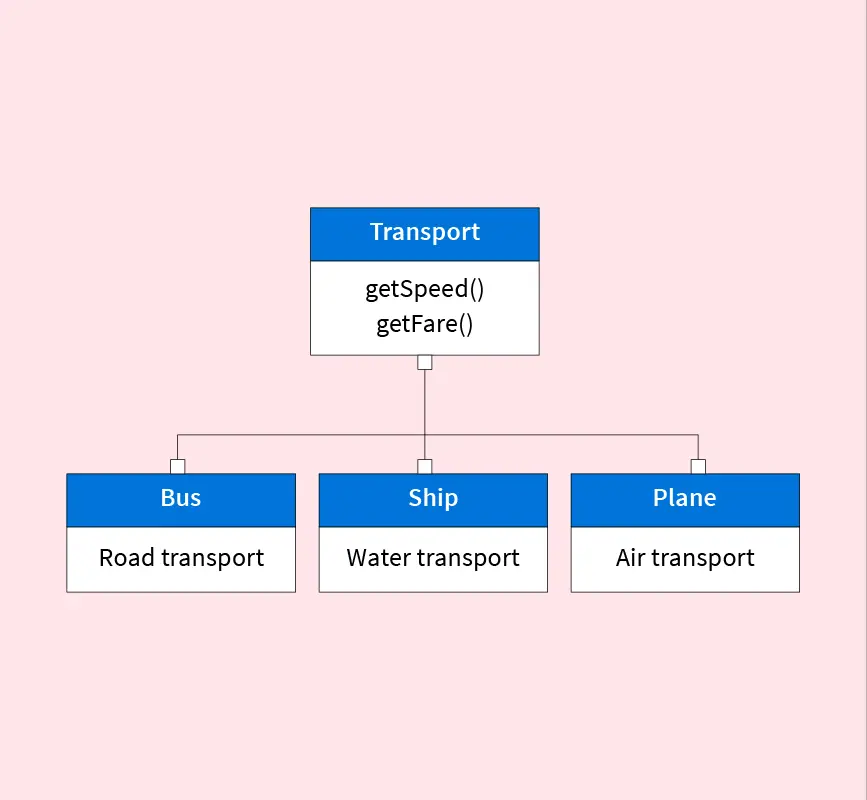
A modelagem orientada a objetos combina os princípios da programação orientada a objetos com a estrutura dos bancos de dados, criando uma forma mais natural de representar informações em sistemas complexos.
Nessa abordagem, cada objeto reúne tanto os dados quanto os comportamentos que atuam sobre eles:
Ela é muito usada em softwares de engenharia, simulações científicas, jogos e sistemas industriais, especialmente em linguagens como Python, Java e C++.
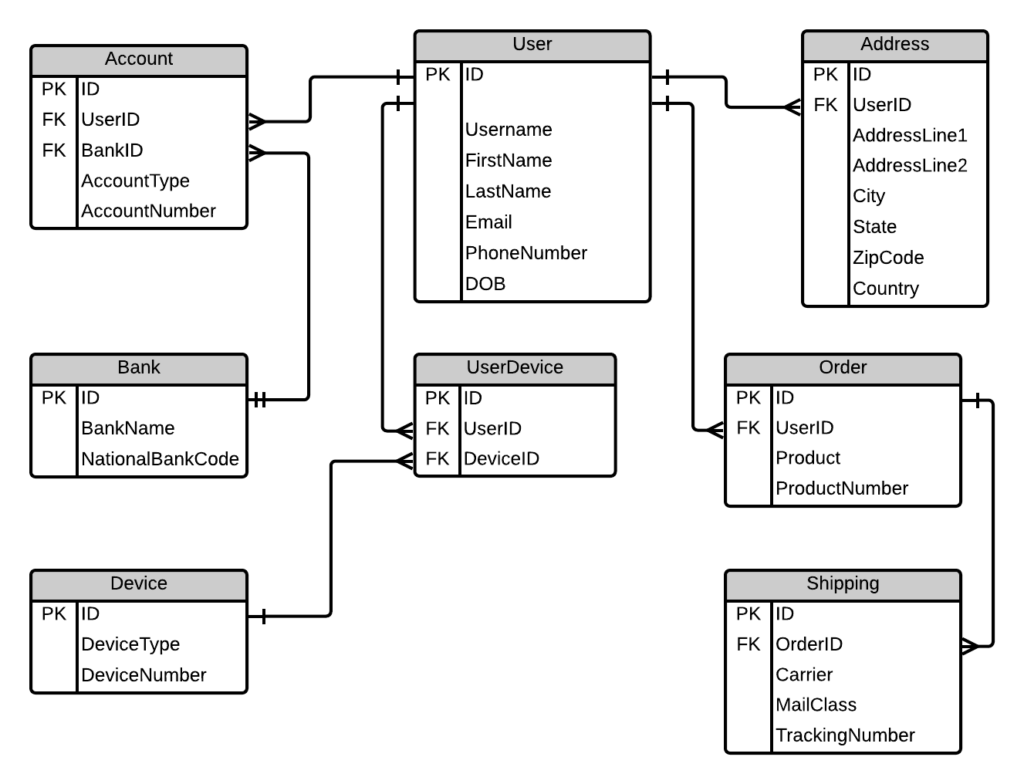
A modelagem relacional é a base dos bancos de dados SQL modernos e uma das mais utilizadas para organizar informações estruturadas.
Nesse tipo de modelagem:
Cada tabela representa uma entidade do mundo real e as conexões entre elas refletem seus relacionamentos. Essa abordagem é muito utilizada em sistemas corporativos e aplicações de grande porte, como bancos, ERPs, CRMs e plataformas web.
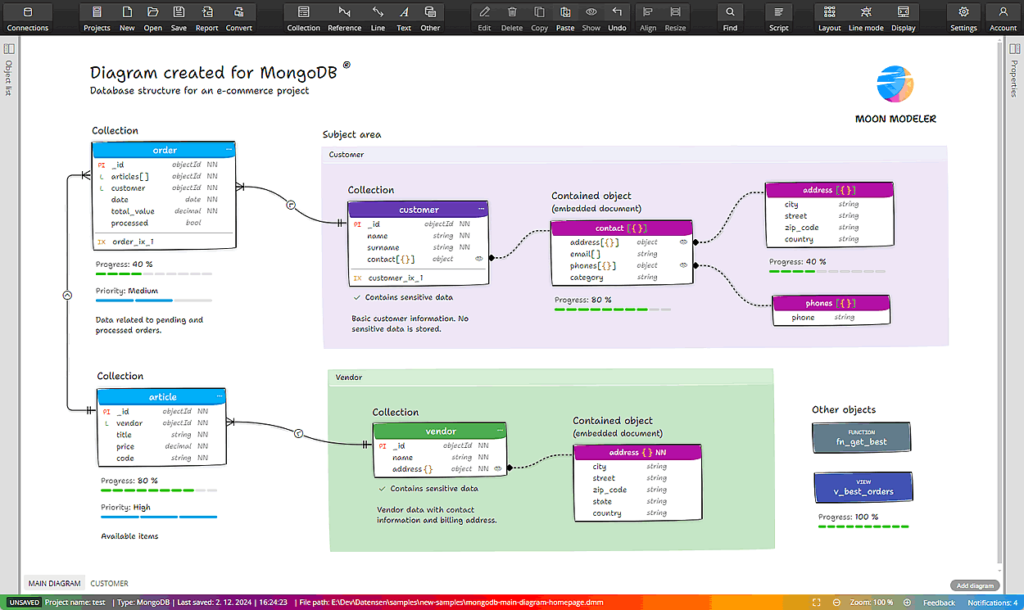
Com o avanço do Big Data e da computação em nuvem, surgiu a modelagem NoSQL, uma abordagem mais flexível, sem a necessidade de um esquema fixo.
Diferentemente dos bancos relacionais, os bancos NoSQL trabalham com formatos dinâmicos, como documentos, pares chave-valor, colunas ou grafos. Isso permite lidar com dados que mudam constantemente ou que não seguem um padrão rígido, algo comum em aplicações modernas.
Por isso, em vez de tabelas, os dados são armazenados em documentos JSON, como pequenos pacotes de informação. Cada documento pode ter campos diferentes, oferecendo liberdade para adaptar a estrutura conforme o projeto evolui.
Essa técnica é indicada para projetos que exigem agilidade, escalabilidade e integração com APIs, como:
O processo varia conforme a técnica usada (relacional, dimensional, NoSQL etc.). Apesar disso, em geral, ele segue uma sequência lógica que vai do entendimento do negócio até a validação do modelo final. Veja como esse processo funciona na prática:
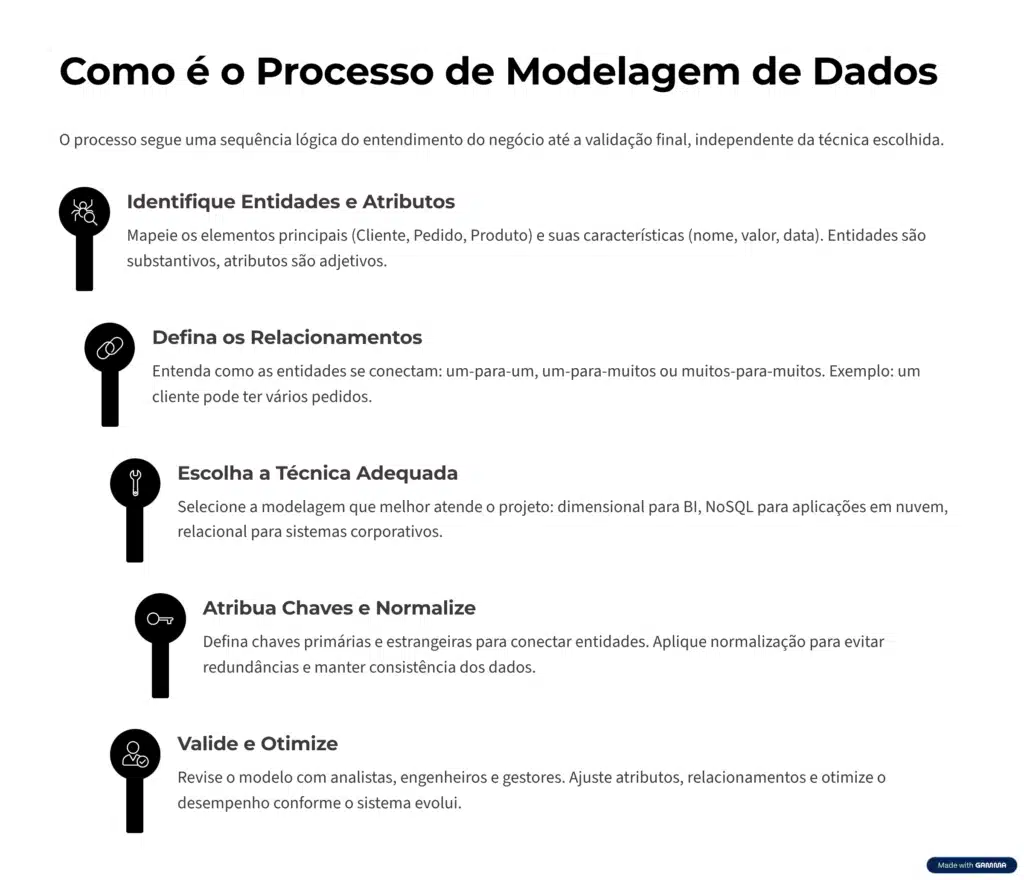
Tudo começa pela identificação das entidades, os elementos principais do sistema, como pessoas, produtos, locais, eventos ou conceitos. Cada entidade deve ser única e representar algo importante para o negócio.
Em seguida, defina os atributos, que são as características que descrevem cada entidade.
Por exemplo:
Pense nas entidades como substantivos (Cliente, Pedido, Produto) e nos atributos como adjetivos (nome, valor, data).
Com as entidades mapeadas, o próximo passo é entender como elas se relacionam.
Esses relacionamentos representam as regras de negócio e podem ser:
Exemplos:
Lembrando que essas conexões são a base dos diagramas Entidade-Relacionamento (ER), que ajudam a visualizar o modelo de dados de forma clara e colaborativa.
Depois de entender as entidades e os relacionamentos, é hora de decidir qual técnica de modelagem faz mais sentido para o projeto.
Por exemplo, se o seu objetivo é criar um sistema de relatórios de vendas no Power BI, a técnica dimensional é a mais indicada. Porém, se você está construindo um aplicativo em nuvem com dados que mudam constantemente, a modelagem NoSQL pode ser a melhor escolha.
Nesta etapa, defina as chaves primárias e estrangeiras, responsáveis por identificar e conectar as entidades entre si. Você também deve fazer a normalização, técnica usada para evitar redundâncias e manter a consistência dos dados.
Por exemplo, em vez de repetir o nome do cliente em várias tabelas, crie uma chave única (id_cliente) que conecta a tabela Clientes à tabela Pedidos.
Por fim, o modelo deve ser revisado e validado junto às partes interessadas, ou seja, analistas, engenheiros e gestores de negócio. Esta é uma etapa iterativa, repetida sempre que o sistema evolui ou surgem novas necessidades.
Durante a validação, é importante ajustar os atributos, revisar relacionamentos e otimizar o desempenho de acordo com o banco de dados escolhido.
Existem várias ferramentas que ajudam a criar, visualizar e testar modelos de dados, sejam eles conceituais, lógicos ou físicos. Conheça cinco das mais usadas no mercado e como cada uma pode te ajudar a colocar seus projetos em prática:
Uma das melhores formas de entender modelagem de dados é ver o conceito funcionando na prática.
Neste exemplo, vamos criar um modelo simples de e-commerce, com três entidades principais:
Antes de escrever qualquer linha de código, pense nas relações entre essas entidades:
Visualmente, essas relações podem ser representadas assim:
Clientes 1 → N Pedidos N → N Produtos
Para representar a relação muitos-para-muitos entre Pedidos e Produtos, criamos uma tabela intermediária chamada ItensPedido.
Agora vamos transformar o modelo em tabelas no SQL. O código abaixo cria as tabelas e define os relacionamentos entre elas:
-- Criar tabela de clientes
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nome VARCHAR(100),
email VARCHAR(100)
);
-- Criar tabela de produtos
CREATE TABLE produtos (
id_produto INT PRIMARY KEY,
nome VARCHAR(100),
preco DECIMAL(10,2)
);
-- Criar tabela de pedidos
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT,
data_pedido DATE,
FOREIGN KEY (id_cliente) REFERENCES clientes(id_cliente)
);
-- Criar tabela intermediária (itens do pedido)
CREATE TABLE itens_pedido (
id_pedido INT,
id_produto INT,
quantidade INT,
FOREIGN KEY (id_pedido) REFERENCES pedidos(id_pedido),
FOREIGN KEY (id_produto) REFERENCES produtos(id_produto)
);Entenda o que diz esse código:
FOREIGN KEY id_cliente);Com o banco criado, podemos interagir com ele usando Python. Neste exemplo, usaremos o SQLite (banco leve embutido no Python) e o Pandas para ler e analisar os dados:
import sqlite3
import pandas as pd
# Cria o banco em memória
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
# Cria as tabelas
cursor.executescript("""
CREATE TABLE clientes (id_cliente INT PRIMARY KEY, nome TEXT, email TEXT);
CREATE TABLE produtos (id_produto INT PRIMARY KEY, nome TEXT, preco REAL);
CREATE TABLE pedidos (id_pedido INT PRIMARY KEY, id_cliente INT, data_pedido DATE, FOREIGN KEY (id_cliente) REFERENCES clientes(id_cliente));
CREATE TABLE itens_pedido (id_pedido INT, id_produto INT, quantidade INT, FOREIGN KEY (id_pedido) REFERENCES pedidos(id_pedido), FOREIGN KEY (id_produto) REFERENCES produtos(id_produto));
""")
# Insere dados de exemplo
cursor.executemany("INSERT INTO clientes VALUES (?, ?, ?)", [
(1, "João Silva", "[email protected]"),
(2, "Maria Santos", "[email protected]")
])
cursor.executemany("INSERT INTO produtos VALUES (?, ?, ?)", [
(1, "Notebook", 3500.00),
(2, "Mouse", 120.00),
(3, "Teclado", 250.00)
])
cursor.executemany("INSERT INTO pedidos VALUES (?, ?, ?)", [
(1, 1, "2025-10-20"),
(2, 2, "2025-10-21")
])
cursor.executemany("INSERT INTO itens_pedido VALUES (?, ?, ?)", [
(1, 1, 1),
(1, 2, 2),
(2, 3, 1)
])
conn.commit()Com tudo pronto, podemos cruzar as informações e gerar análises rápidas com o Pandas:
# Consulta SQL
query = """
SELECT c.nome AS cliente, p.data_pedido, pr.nome AS produto, pr.preco, i.quantidade,
pr.preco * i.quantidade AS total
FROM pedidos p
JOIN clientes c ON p.id_cliente = c.id_cliente
JOIN itens_pedido i ON p.id_pedido = i.id_pedido
JOIN produtos pr ON i.id_produto = pr.id_produto
"""
# Carrega o resultado em um DataFrame
df = pd.read_sql_query(query, conn)
print(df)Saída:
| cliente | data_pedido | produto | preco | quantidade | total |
|---|---|---|---|---|---|
| João Silva | 2025-10-20 | Notebook | 3500.0 | 1 | 3500.0 |
| João Silva | 2025-10-20 | Mouse | 120.0 | 2 | 240.0 |
| Maria Santos | 2025-10-21 | Teclado | 250.0 | 1 | 250.0 |
Agora você tem uma visão clara de quem comprou o quê, quando e quanto gastou, tudo a partir de um modelo de dados bem estruturado e aplicado com Python e SQL.
E se você ainda tem dúvidas sobre como usar o Pandas na análise de dados, recomendamos que assista a esta aula gratuita do Professor Juliano Faccioni sobre o assunto:
A modelagem é o ponto de partida de tudo no mundo dos dados. Ela sustenta pipelines, análises, dashboards e até modelos de machine learning. Quando você entende como estruturar informações de forma lógica e escalável, consegue transformar dados brutos em decisões inteligentes e em automações reais.
Na Trilha Engenharia de Dados, da Asimov Academy, você aprende tudo isso na prática, com projetos reais, ferramentas modernas e uma metodologia pensada para quem quer evoluir rápido!
Comece hoje mesmo a construir as bases para uma carreira em Engenharia de Dados. Domine Python, SQL, Docker, Airflow e todas as ferramentas necessárias para criar pipelines profissionais e transformar dados em resultados.
Inscreva-se agora e transforme seu futuro!

Domine os fundamentos da Engenharia de Dados e construa seu primeiro pipeline com Python, ETL, Airflow e deploy na nuvem.
Comece agoraA modelagem de dados é dividida em três níveis:
Essas três etapas se complementam e garantem que o modelo evolua do entendimento do negócio à implementação real.
A modelagem serve para estruturar e conectar informações de modo que possam ser facilmente transformadas em relatórios, dashboards ou insights analíticos. Ela é importante para o funcionamento de bancos de dados, pipelines, automações e análises avançadas, do Business Intelligence (BI) à inteligência artificial (IA).
A modelagem relacional (SQL) organiza os dados em tabelas conectadas por chaves primárias e estrangeiras, garantindo consistência e estrutura rígida. Já a modelagem não relacional (NoSQL) usa formatos mais flexíveis, como documentos, grafos ou coleções, sendo ideal para dados dinâmicos e escaláveis.
A melhor forma de aprender é praticando. Comece criando um pequeno modelo com entidades como Clientes, Pedidos e Produtos, depois implemente em SQL e manipule com Python. Se quiser aprender de forma estruturada e prática, faça a Trilha Engenharia de Dados, da Asimov Academy.

Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:




Comentários
30xp