
Leia também:


O Databricks é uma plataforma em nuvem que une engenharia de dados, análise avançada e inteligência artificial (IA) em um único ambiente colaborativo.
Criado em 2013 por pesquisadores de Berkeley, os mesmos responsáveis pelo Apache Spark, a ferramenta nasceu para simplificar a execução do Spark em notebooks. Com o tempo, evoluiu para o modelo Lakehouse, que combina o melhor dos Data Lakes e Data Warehouses.
Na prática, o Databricks é uma plataforma unificada de dados e IA que reúne SQL, Apache Spark, workflows, dashboards, APIs e recursos de IA. Com ela, você pode coletar, transformar, analisar e operacionalizar dados em larga escala, sem se preocupar com a infraestrutura.
O Databricks funciona por meio de clusters, conjuntos de máquinas virtuais responsáveis por processar dados em larga escala. Por isso, o usuário não precisa configurar a infraestrutura manualmente.
A própria plataforma gerencia e ajusta os recursos de computação conforme a carga de trabalho. E tudo isso acontece em uma interface simples e acessível pelo navegador, o que torna o trabalho com dados muito mais prático.
Vale lembrar que o Databricks é usado principalmente por meio de notebooks interativos, que permitem escrever e executar código em linguagens como Python, SQL, R e Scala.
Nesses notebooks, é possível realizar desde tarefas simples de limpeza e transformação de dados até treinar modelos de machine learning. Por conta disso, essa plataforma é indicada para engenheiros de dados, cientistas de dados e analistas de BI que buscam produtividade e colaboração em um só lugar.

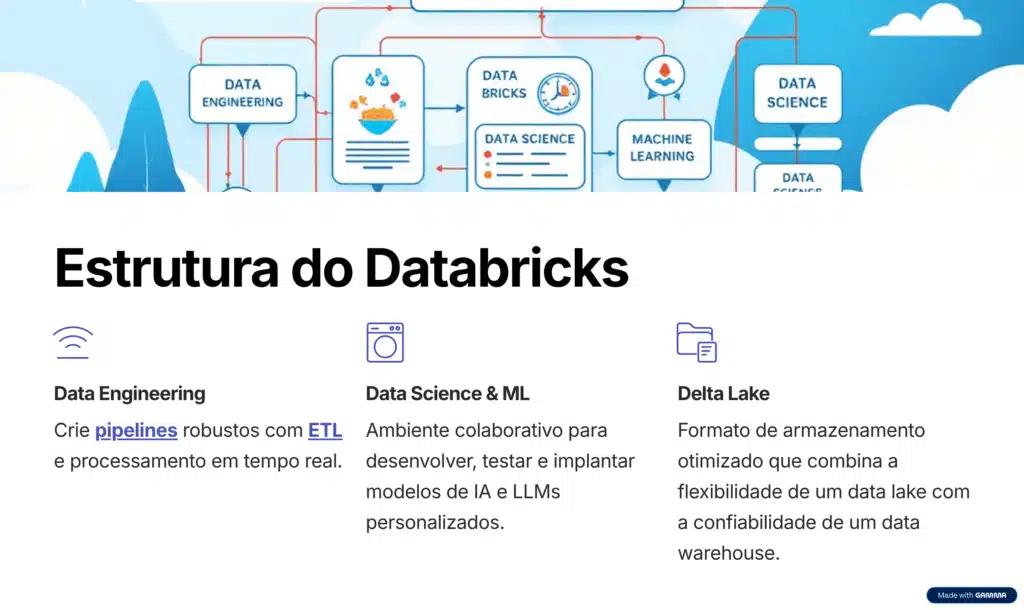
A estrutura do Databricks é composta por módulos que cobrem todo o ciclo de vida dos dados, desde coleta e transformação ao deploy de modelos de IA. Conheça seus principais módulos a seguir:

Escolher a ferramenta certa para trabalhar com dados nem sempre é simples. Afinal, existem muitas opções no mercado, sendo que cada uma tem suas vantagens, limitações e casos de uso específicos.
Veja a seguir como o Databricks se compara a outras soluções populares de plataformas em nuvem:
O Snowflake é uma plataforma de dados em nuvem voltada para armazenamento, consulta e análise de grandes volumes de dados, sem necessidade de gerenciar infraestrutura.
Ele funciona como um data warehouse totalmente gerenciado, com escalabilidade automática e suporte a dados estruturados e semiestruturados.
Já o Databricks é uma solução mais completa e avançada, voltada para quem precisa processar e transformar dados em escala, modelar com Apache Spark, criar pipelines complexos e aplicar modelos de machine learning.
Compare as duas ferramentas abaixo:
| Recurso / Foco | Databricks | Snowflake |
|---|---|---|
| Tipo de plataforma | Lakehouse (dados + IA) | Data warehouse em nuvem |
| Linguagens | Python, SQL, Scala, R | SQL |
| Casos de uso principais | Engenharia de dados, IA, Machine Learning, streaming | BI, relatórios, dashboards, consultas ad hoc |
| Processamento | Distribuído com Apache Spark | Armazenamento e consulta otimizados |
| Nível técnico exigido | Médio a alto (engenharia e ciência de dados) | Baixo a médio (análise e BI) |
| Integrações | APIs, notebooks, pipelines e MLflow | Power BI, Tableau, Looker |
| Melhor para | Processar e transformar dados em escala | Consultar e visualizar dados com rapidez |
O Azure Data Factory (ADF) é uma ferramenta de ETL em nuvem que ajuda empresas a mover e transformar dados entre diferentes fontes de forma automática e organizada. Em comparação, o Databricks tem um foco diferente. Ele é voltado para processamento pesado de dados, análises avançadas e IA.
Na prática, o ADF cuida da movimentação e integração dos dados (extração, transformação simples e carga). Já o Databricks é utilizado para trabalhar com grandes volumes de dados, realizar análises complexas e criar modelos de machine learning. Por isso, muitas empresas utilizam ADF e Databricks em conjunto.
Compare as duas ferramentas a seguir:
| Característica | Azure Data Factory (ADF) | Databricks |
|---|---|---|
| Tipo de ferramenta | ETL visual em nuvem | Plataforma de dados e IA |
| Foco principal | Mover, transformar e orquestrar dados | Processar, analisar e modelar dados |
| Nível técnico | Baixo a médio (pouco código) | Médio a alto (código em Python, SQL, Spark) |
| Casos de uso | Integração de fontes e automação de pipelines | Análises complexas, IA e ML em escala |
| Melhor para | Equipes que querem praticidade e automação | Times que precisam de performance e flexibilidade |
O primeiro passo para começar a usar o Databricks é criar um workspace, que funciona como o seu ambiente central de trabalho dentro da plataforma. É nele que você organiza projetos, colabora com o time e executa notebooks, pipelines e dashboards.
E a maneira mais simples de criar seu primeiro workspace é usando o AWS Quick Start, um processo automatizado que configura todos os recursos necessários na AWS.
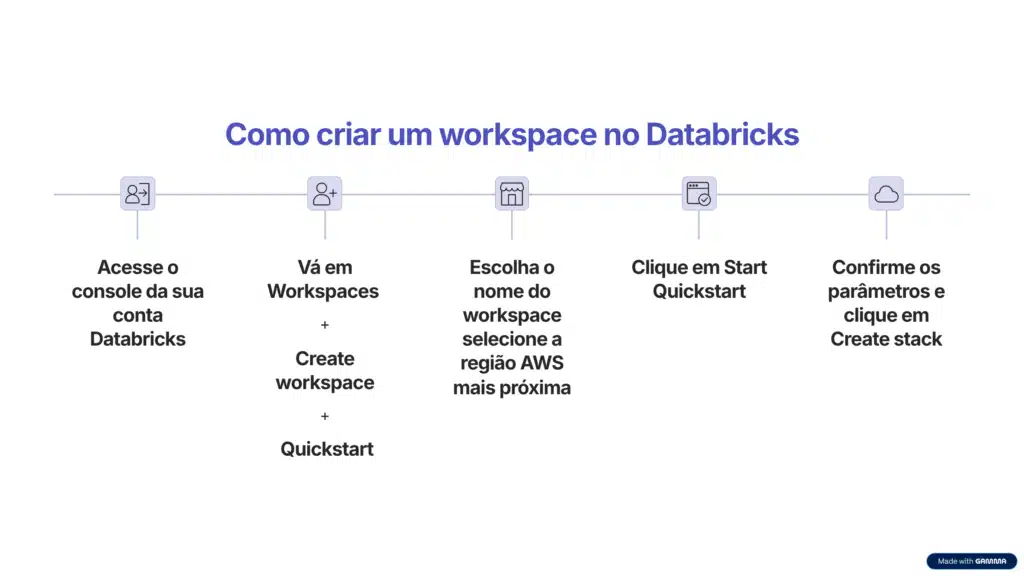
Em poucos minutos, você receberá um e-mail com o link de acesso ao workspace já configurado.
Lembrando que o ideal é habilitar o Unity Catalog durante a criação do workspace. Isso porque ele garante governança centralizada e controle de acesso unificado. Caso não ative nesse momento, pode configurá-lo depois.
Com o workspace pronto, a melhor forma de aprender é seguindo os Getting Started Tutorials disponíveis na documentação do Databricks. Eles são ideais para aprender de forma guiada, colocando em prática os principais recursos da plataforma.
Confira alguns exemplos:
As certificações Databricks comprovam que você domina o uso da plataforma unificada para trabalhar com dados em escala, incluindo SQL, Spark, Delta Lake, workflows e machine learning.
Essas credenciais validam habilidades em ETL/ELT, modelagem, governança e IA, exatamente o que o mercado busca em profissionais de engenharia de dados e analytics hoje.
Confira a seguir um resumo das principais certificações da Databricks (todas com validade de 2 anos):
| Certificação | Indicado para | O que aborda | Preço* |
|---|---|---|---|
| Data Analyst Associate | Analistas de dados | SQL no Databricks, análise e visualização | US$ 200 |
| Data Engineer Associate | Iniciantes em engenharia de dados | ETL/ELT, Spark + Delta, pipelines básicos | US$ 200 |
| Data Engineer Professional | Engenheiros de dados experientes | Pipelines avançados, performance e boas práticas | US$ 200 |
| Machine Learning Associate | Iniciantes em ML | Fundamentos de ML, treino/avaliação, uso de MLflow | US$ 200 |
| Machine Learning Professional | Engenheiros de ML experientes | ML avançado, implantação e otimização | US$ 200 |
| Generative AI Engineer | Engenheiros de IA e cientistas de dados | Modelos generativos (RAG, fine-tuning), apps de IA | US$ 200 |
| Apache Spark Developer Associate | Desenvolvedores e engenheiros | Programação com Spark e processamento distribuído | US$ 200 |
O Databricks abre um mundo de oportunidades para quem domina a stack moderna de dados. Mas aprender a usar essa ferramenta não é suficiente para construir uma carreira sólida na área.
Quem pula etapas pode acabar travando no primeiro projeto real porque faltou base em engenharia de dados. Isso significa que, para dominar o Databricks de verdade, você precisa primeiro dominar os fundamentos dessa ciência.
E o caminho mais simples e estruturado para isso é a Trilha Engenharia de Dados, da Asimov Academy.
Nela, você vai:
Inscreva-se agora e construa a base que vai te levar mais longe na carreira de dados!

Domine os fundamentos da Engenharia de Dados e construa seu primeiro pipeline com Python, ETL, Airflow e deploy na nuvem.
Comece agoraO Databricks oferece uma plataforma de Data Intelligence baseada na arquitetura Lakehouse. Ela unifica dados e inteligência artificial em um só lugar, o que permite coletar, transformar, consultar (SQL), criar pipelines (Workflows), treinar e servir modelos (MLflow) e publicar dashboards.
Não. O Databricks é uma empresa independente, fundada pelos criadores do Apache Spark. Porém, ela mantém uma parceria estratégica com a Microsoft, que resultou no serviço Azure Databricks, uma versão integrada ao ecossistema Azure. Além disso, o Databricks também opera em AWS e Google Cloud Platform (GCP).
Não totalmente. A plataforma possui um plano gratuito, o Databricks for free, voltado para estudantes, educadores e quem quer aprender ou testar recursos de dados e IA.
No entanto, o uso profissional é cobrado conforme os recursos da plataforma são utilizados.
O Databricks utiliza o Databricks SQL, uma variação baseada no Spark SQL. Essa linguagem segue o padrão ANSI SQL, mas traz extensões e otimizações próprias para trabalhar com grandes volumes de dados e formatos semiestruturados, aproveitando toda a performance do Apache Spark e do Delta Lake.
A plataforma é usada por empresas de diversos setores, como finanças, varejo, e-commerce, mídia, indústria, saúde e telecomunicações. Ela é utilizada principalmente por times que precisam integrar engenharia de dados, BI e IA, em aplicações como lakehouses corporativos, analytics em escala, streaming e machine learning generativo (GenAI).

Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:



Comentários
30xp