


Se você já pesquisou algo no Google e recebeu uma resposta incrivelmente precisa, pode apostar que o BERT teve um papel nisso. Esse modelo revolucionário de Processamento de Linguagem Natural (NLP) mudou a forma como as máquinas entendem o nosso idioma, tornando-se indispensável para buscas, chatbots e até assistentes virtuais. Mas o que exatamente é o BERT? Como ele funciona? E o melhor: como você pode usá-lo no seu próprio código com Python?
Neste guia, vamos mergulhar fundo nessa tecnologia e mostrar como ela pode transformar a maneira como interagimos com a inteligência artificial. Preparado? Então, vamos lá!
O que é o BERT?
O BERT (Bidirectional Encoder Representations from Transformers) é um modelo de inteligência artificial desenvolvido pelo Google que mudou completamente a forma como as máquinas interpretam a linguagem humana. Diferentemente de modelos anteriores, que analisavam palavras de maneira isolada ou apenas em uma direção do texto, o BERT entende o significado das palavras com base no contexto ao redor delas, tanto antes quanto depois. Isso faz com que o processamento de linguagem natural (NLP) fique muito mais próximo da maneira como os humanos realmente entendem um texto.
Pense, por exemplo, na palavra “banco”. Dependendo da frase, ela pode se referir a uma instituição financeira ou a um assento. Modelos antigos tratavam essa palavra sempre da mesma forma, sem levar em conta o contexto. Já o BERT consegue interpretar o significado correto analisando todo o entorno da palavra na frase. Essa capacidade revolucionou mecanismos de busca, assistentes virtuais e uma série de outras aplicações que dependem de interpretação precisa da linguagem.
O segredo do BERT está na arquitetura Transformer, uma rede neural que permite entender padrões complexos no texto. E o melhor? Ele é um modelo de código aberto! Ou seja, qualquer pessoa ou empresa pode usá-lo para melhorar sistemas de atendimento ao cliente, tradutores automáticos, chatbots e muito mais.
Além disso, desde seu lançamento em 2018, o BERT passa por aprimoramentos constantes. Graças ao treinamento em um enorme volume de textos, com mais de 33 milhões de documentos, ele se destaca pela alta eficácia em diversas tarefas de linguagem natural. Como consequência, sua implementação ajudou o Google a melhorar significativamente os resultados das pesquisas, tornando-as mais precisas e contextuais.
História do BERT
O BERT surgiu em 2018, desenvolvido por uma equipe de pesquisadores do Google, e logo se estabeleceu como um ponto de virada no campo do Processamento de Linguagem Natural (NLP). Seu lançamento em código aberto permitiu que desenvolvedores e pesquisadores de diversas partes do mundo explorassem, adaptassem e aprimorassem o modelo, tornando-o uma ferramenta indispensável para a compreensão de textos complexos.
Pouco tempo após sua introdução, o Google começou a aplicar o BERT em suas pesquisas, o que passou a influenciar cerca de 10% das consultas em inglês, demonstrando seu impacto direto na qualidade dos resultados de busca. Além disso, essa integração marcou um avanço significativo na maneira como os sistemas interpretam e respondem às perguntas dos usuários.
O modelo também passou por importantes atualizações. Em dezembro de 2019, o BERT foi expandido para suportar mais de 70 idiomas, incluindo o português. Essa evolução não só ampliou seu alcance global, mas também melhorou a qualidade das buscas e da compreensão da linguagem em contextos diversos, beneficiando usuários ao redor do mundo.
Como o BERT funciona?
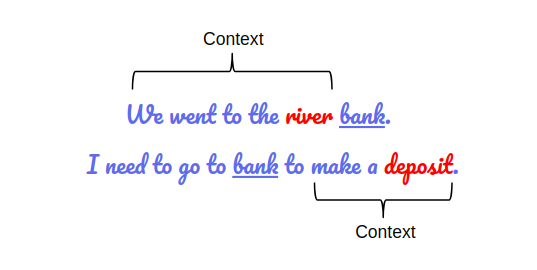
O BERT funciona de forma muito diferente dos modelos tradicionais de NLP ao analisar o contexto de uma palavra. Enquanto os métodos anteriores consideravam apenas as palavras à esquerda ou à direita (ou seja, de maneira unidirecional), o BERT adota uma abordagem bidirecional, examinando simultaneamente o que vem antes e depois da palavra em questão. Essa estratégia permite que o modelo compreenda melhor as relações e nuances presentes nas frases.
Durante o treinamento, o BERT utiliza um corpus de texto como a Wikipédia para aprender as representações contextuais das palavras. Em seguida, ele passa por uma etapa de “fine-tuning”, onde é ajustado para executar tarefas específicas, como responder perguntas ou analisar sentimentos. Essa adaptação permite que o modelo se especialize em diferentes demandas, mantendo a mesma base de entendimento da linguagem.
No contexto do buscador do Google, o BERT é responsável por captar as intenções por trás das consultas dos usuários, interpretando palavras e frases em seu contexto completo. Embora o BERT seja apenas uma parte do sistema, sua habilidade de mapear o significado de uma frase de forma abrangente colabora para que o algoritmo geral escolha e classifique os melhores resultados de pesquisa.
Aplicações do BERT em processamento de linguagem natural
O BERT tem sido amplamente aplicado em diversas áreas do Processamento de Linguagem Natural, trazendo benefícios práticos para uma variedade de tarefas. Seu impacto se estende desde a criação de chatbots e sistemas de perguntas e respostas até a personalização de recomendações e a análise de sentimentos.
Em sistemas de perguntas e respostas, por exemplo, o BERT permite que a máquina entenda a intenção do usuário e, com base nisso, forneça respostas mais precisas e contextualmente relevantes. Essa aplicação tem sido utilizada para melhorar a interação em plataformas de atendimento ao cliente e em assistentes de voz, onde compreender o contexto de uma consulta é essencial para gerar respostas úteis.
Além disso, o BERT é empregado em tarefas que envolvem a correspondência e a detecção de semelhanças entre frases, o que pode ser útil para identificar plágio ou sugerir conteúdos relacionados. Em plataformas de mídia social, ele também pode ser ajustado para detectar conteúdos ofensivos, ajudando a manter um ambiente mais seguro e agradável para os usuários.
O modelo não se limita a essas aplicações. Ele contribui para a melhoria das buscas no Google em SEO, permitindo uma compreensão mais refinada das consultas dos usuários, especialmente em casos de buscas complexas. No setor de e-commerce, o BERT pode personalizar recomendações de produtos ao entender o comportamento e as preferências dos clientes, enquanto na área da saúde, pode ajudar a extrair informações relevantes de prontuários médicos para suportar decisões clínicas.
Prevendo risco de doenças cardíacas com Machine Learning
Esses exemplos demonstram como o BERT se tornou uma ferramenta versátil no universo do PLN, contribuindo para que máquinas compreendam e respondam às interações humanas de maneira mais precisa e eficiente.
Implementando o BERT com Python
A biblioteca Hugging Face Transformers tem se tornado uma ferramenta indispensável para trabalhar com modelos de linguagem, incluindo o BERT. Ela simplifica o processo de carregar modelos pré-treinados e permite que você os utilize com apenas algumas linhas de código.
Para começar, é necessário instalar a biblioteca usando o comando:
pip install transformersExemplo prático: implementando um modelo BERT para análise de sentimentos
Depois disso, você pode importar os componentes essenciais do BERT em seu script Python. Por exemplo, para análise de sentimentos, o modelo se adapta para classificar textos em categorias como positivo, negativo ou neutro, auxiliando empresas a entender o feedback de clientes e a monitorar a reputação de marcas em tempo real. Você pode importar o tokenizer e o modelo pré-treinado da seguinte forma:
from transformers import BertTokenizer, BertForSequenceClassificationA seguir, carregue o tokenizer e o modelo. No exemplo abaixo, usamos a versão “bert-base-uncased”, uma das variantes mais comuns do BERT:
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')Agora, vamos preparar um texto para análise. O tokenizer converte o texto em uma forma que o modelo pode entender, gerando tensores que representam a entrada:
text = "I love using BERT for natural language processing!"
inputs = tokenizer(text, return_tensors='pt')Com o texto preparado, é hora de fazer a previsão. Ao executar o modelo com os inputs, você obterá os logits, que são as pontuações para cada classe:
outputs = model(**inputs)
logits = outputs.logitsPara identificar a classe prevista, encontre o índice com a maior pontuação usando o método argmax:
predicted_class = logits.argmax().item()Esse exemplo prático demonstra como utilizar o BERT para tarefas de análise de sentimentos. Em uma implementação real, você pode adaptar esse fluxo para diferentes aplicações, como classificação de textos ou respostas a perguntas.
Além disso, se você desejar treinar ou ajustar o modelo para um conjunto de dados específico, será necessário um dataset rotulado. O processo envolve definir um otimizador, configurar um loop de treinamento e avaliar o desempenho do modelo em um conjunto de validação. A biblioteca Hugging Face oferece tutoriais e exemplos detalhados para auxiliar nesse processo, tornando o ajuste fino do modelo mais acessível para desenvolvedores.
Dicas e melhores práticas para trabalhar com o BERT
Ao trabalhar com PLN e estratégias de SEO, é essencial combinar práticas técnicas com uma abordagem centrada no usuário. A seguir, apresentamos dicas e melhores práticas para cada uma dessas áreas, garantindo que seus modelos de linguagem aprendam com dados de alta qualidade e que seu conteúdo alcance a audiência desejada de forma clara e eficaz.
Dicas e melhores práticas para PLN
Para obter resultados consistentes em PLN, comece com a seleção de dados. Opte por conjuntos de dados relevantes e de alta qualidade que reflitam o tipo de linguagem e os contextos em que seu modelo será aplicado. Essa escolha contribui para que o modelo aprenda padrões significativos e reduza possíveis vieses.
Uma vez definido o conjunto de dados, utilize o pré-treinamento para construir representações gerais da linguagem. Em seguida, ajuste o modelo para tarefas específicas, como análise de sentimentos ou respostas a perguntas, por meio de fine-tuning. Esse processo garante que o modelo se torne mais preciso ao se concentrar nas demandas da aplicação.
A otimização dos hiperparâmetros é outro passo importante. Teste diferentes configurações para encontrar a combinação que maximize o desempenho na tarefa em questão. Para avaliar o sucesso do modelo, utilize métricas apropriadas como precisão, F1-score ou ROUGE que permitam mensurar a eficácia de forma clara. Por fim, busque sempre interpretar os resultados do modelo. Compreender como ele toma decisões pode revelar áreas de melhoria e ajudar a ajustar sua abordagem para evitar erros e aumentar a confiabilidade.
Dicas e melhores práticas para SEO
Quando se trata de SEO, a qualidade e relevância do conteúdo devem ser a prioridade. Produza material que seja útil e interessante para o seu público, em vez de focar exclusivamente na otimização para palavras-chave. O uso de palavras-chave e frases de cauda longa pode ajudar a capturar buscas mais específicas, mas isso deve ser feito de forma natural, sem forçar a inclusão de termos que comprometam a fluidez do texto.
A estrutura do conteúdo também desempenha um papel fundamental. Organize suas ideias com títulos e subtítulos claros, além de parágrafos bem definidos, para que a leitura seja mais agradável e a informação seja facilmente absorvida. Escrever de forma natural, com a gramática correta e evitando erros de grafia, é importante, pois o próprio BERT e outros sistemas modernos de busca conseguem entender a linguagem como ela é falada, valorizando um estilo autêntico e bem escrito.
Além disso, ofereça uma experiência de leitura enriquecedora. Isso pode incluir o uso de links relevantes, imagens que complementem o texto e recursos que mantenham o leitor engajado ao longo do conteúdo. Assim, seu site não só se destaca nos motores de busca, mas também proporciona valor real aos usuários.
Erros comuns a evitar
- Ignorar o pré-processamento: o pré-processamento adequado dos dados é crucial para o desempenho do modelo;
- Subestimar a necessidade de dados: o BERT é um modelo complexo que geralmente requer grandes quantidades de dados para treinar efetivamente;
- Não considerar o contexto: lembre-se de que o BERT é projetado para entender o contexto, então evite simplificações excessivas em seus dados.
4 tendências para futuro do BERT
O futuro do BERT e das tecnologias de NLP aponta para inovações que tornarão a compreensão de linguagem ainda mais precisa e eficiente. Com a incorporação de técnicas de aprendizado não supervisionado e transfer learning, futuras versões do BERT poderão atingir níveis superiores de performance usando menos dados. Essa evolução promete otimizar o uso de recursos computacionais, facilitando o acesso a tecnologias de ponta para desenvolvedores com restrições orçamentárias ou de infraestrutura.
1. Multimodalidade e multilinguismo
Uma das direções mais empolgantes é a integração de múltiplos tipos de dados. Modelos multimodais combinam texto, imagem, áudio e vídeo, permitindo que os sistemas capturem o contexto de forma mais abrangente. Além disso, o suporte a múltiplos idiomas está se expandindo, tornando essas tecnologias mais inclusivas e acessíveis para comunidades que falam línguas menos difundidas, o que abre novas oportunidades para aplicações globais.
2. Integração com outras tecnologias de IA
A convergência entre NLP e outras áreas da inteligência artificial, como visão computacional e machine learning, está impulsionando o desenvolvimento de sistemas mais inteligentes e versáteis. Essa integração permite que modelos de linguagem avancem não só na compreensão textual, mas também na interpretação de sinais visuais e comportamentais, abrindo caminho para aplicações inovadoras em automação robótica e assistentes inteligentes.

Controlando o Volume com Visão Computacional
Analisador de Saques no Tênis com Visão Computacional
3. Interpretação de nuances humanas
Apesar dos avanços, interpretar as sutilezas da comunicação humana como ironia, sarcasmo e implicações contextuais continua sendo um desafio. A busca por modelos que consigam captar essas nuances é fundamental para tornar as interações com máquinas mais naturais e eficazes. Melhorar essa capacidade ajudará a refinar sistemas de atendimento ao cliente, assistentes de voz e outras aplicações que dependem de uma compreensão profunda do discurso humano.

LIVE | Criando um Personal Trainer com Inteligência Artificial
4.Inclusão digital e aplicações em escala global
O avanço em NLP não se limita à melhoria técnica dos modelos, mas também tem um impacto significativo na inclusão digital. À medida que os modelos se tornam mais acessíveis e adaptados a diferentes idiomas e contextos culturais, eles podem beneficiar comunidades globalmente, facilitando o acesso a ferramentas e serviços avançados. Isso permite que empresas de diversos setores de saúde a e-commerce implementem soluções inteligentes que atendam às necessidades de uma audiência diversa, promovendo uma transformação digital abrangente.
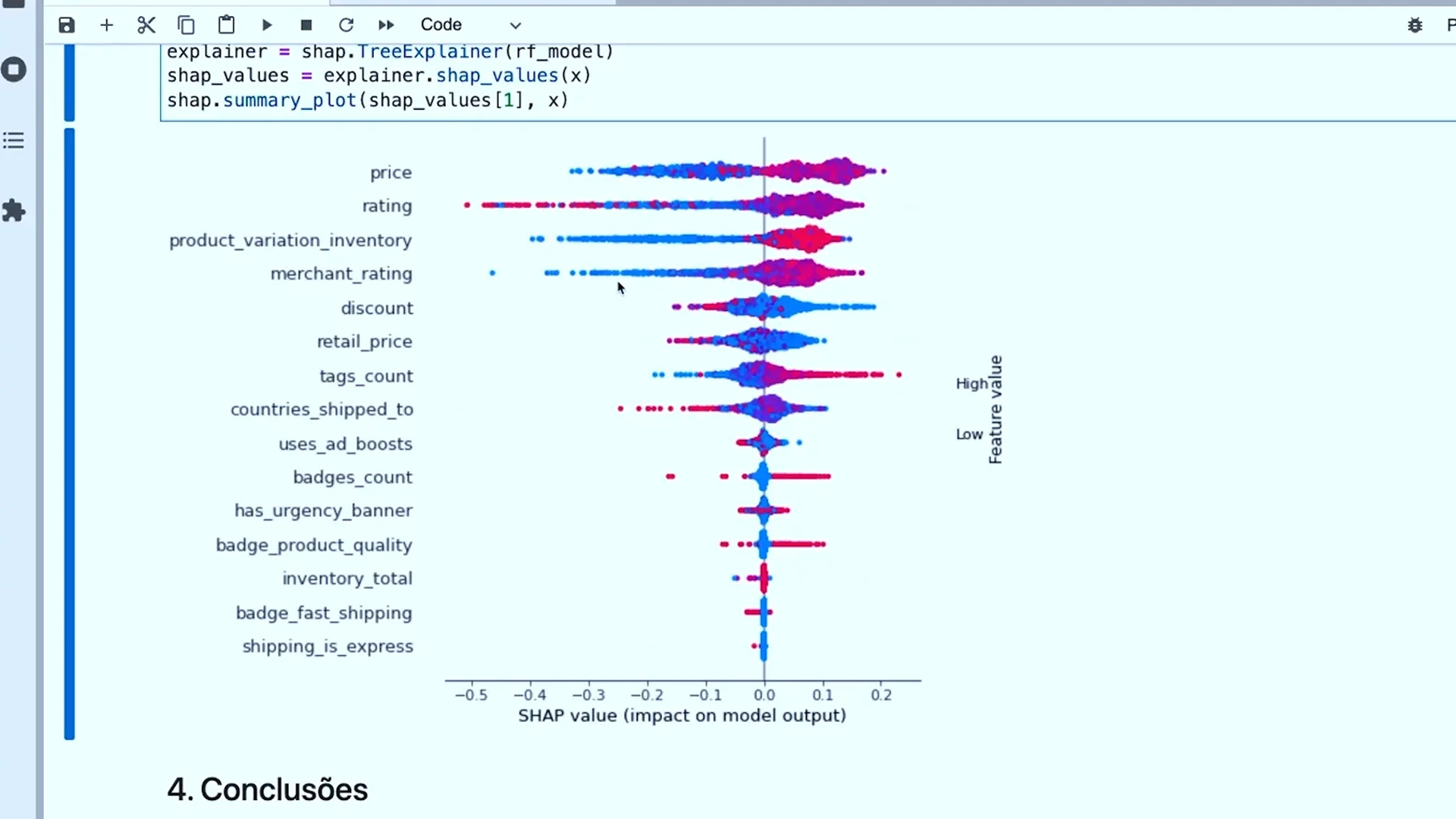
Análise de vendas do marketplace Wish
Curso gratuito de Python para IA para você!
Neste guia, você aprendeu sobre o BERT, sua importância no processamento de linguagem natural, como ele funciona e como implementá-lo usando Python. Se você está animado para continuar sua jornada em NLP, considere explorar mais sobre o universo da inteligência artificial no curso Python para IA da Asimov Academy. Nele,você aprenderá do zero como programar e explorar o poder da IA na prática. Com o professor Adriano como seu guia, você vai descobrir:
- Construção de hábitos de aprendizado eficazes;
- Fundamentos de programação com Python;
- Técnicas para automatizar processos e interagir com dados;
- Criação de um ChatBot funcional usando a biblioteca LangChain;
- Integração de dados de sites, vídeos, PDFs e muito mais.
Não importa se você nunca escreveu uma linha de código, nosso curso foi feito especialmente para você! Dê o primeiro passo rumo a uma nova forma de trabalhar com dados, otimize sua rotina pessoal e profissional e abra portas para oportunidades infinitas no mundo da IA.
Curso Gratuito

Seu primeiro projeto de IA com Python – curso grátis com certificado
Aprenda a programar com Python e explore a inteligência artificial! Crie um chatbot prático que interage com seus próprios dados.
Comece agoraVocê também pode gostar:







Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp