


Se você está iniciando seus estudos em análise de dados, provavelmente já ouviu falar sobre “pandas”. Essa biblioteca de Python é essencial para manipulação e análise de dados. Pandas possibilita fazer tudo o que você faria no Excel, mas com muito mais flexibilidade e poder graças à linguagem de programação Python.
Neste artigo, vamos explorar o uso dessa ferramenta incrível para a análise de dados. Começaremos entendendo o que é a biblioteca pandas e como instalá-la no seu computador. Em seguida, abordaremos os conceitos-chave, como DataFrames (tabelas) e Series (colunas). Por fim, entenderemos como realizar diversas operações de manipulação de dados com o pandas e Python. Vamos lá!
Curso Gratuito

Seu primeiro projeto Python – curso grátis com certificado!
Vá do zero ao primeiro projeto em apenas 2 horas com o curso Python para Iniciantes.
Comece agoraO que é pandas em Python?
Pandas é uma biblioteca de manipulação e análise de dados em Python. Ela permite que você trabalhe com dados de forma eficiente e intuitiva, similar ao que você faria no Excel, mas com muito mais flexibilidade e poder.
Para que o pandas é usado?
Pandas é usado para analisar e manipular dados em tabelas, como aqueles que você encontra em planilhas ou bancos de dados. Ele facilita a exploração, limpeza e processamento de dados e suas tabelas recebem o nome de DataFrame.
Quando usar a biblioteca pandas em Python?
Você deve usar pandas sempre que precisar manipular e analisar dados em tabelas. Esta biblioteca é ideal para tarefas como:
- Leitura e escrita de dados: Pandas pode ler dados de diversos formatos, como CSV, Excel, JSON, SQL, entre outros.
- Limpeza de dados: Pandas oferece diversas funções para tratar dados ausentes, duplicados e inconsistentes.
- Análise exploratória de dados: Pandas facilita a análise exploratória de dados, permitindo agrupar, filtrar e resumir dados de forma eficiente.
Na Asimov Academy, temos um curso completo de pandas para ensinar você a fazer tudo isso e muito mais!
Onde encontrar a documentação do pandas?
A documentação oficial do pandas é um recurso valioso para aprender mais sobre a biblioteca e suas funcionalidades. Você pode encontrar a documentação completa no site oficial do pandas.
Como instalar a biblioteca pandas em Python?
A instalação da biblioteca pandas é bem simples e pode ser feita de diversas maneiras. Vamos ver as principais delas.
Como instalar o pandas pelo pip?
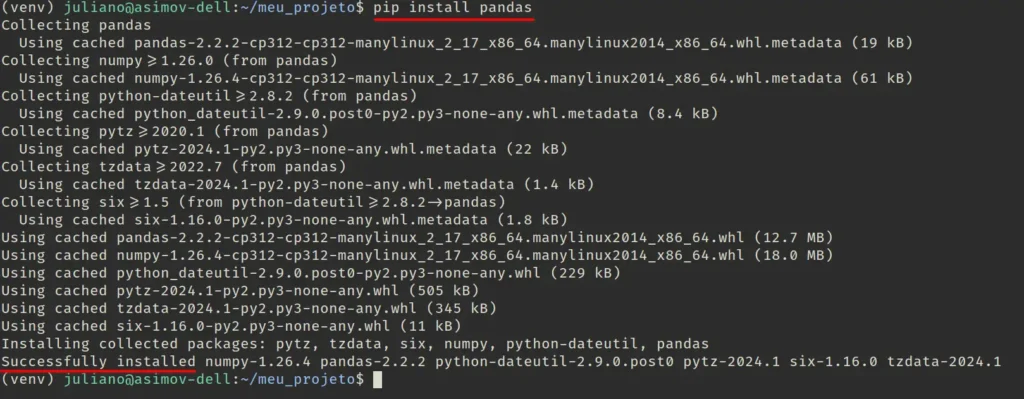
A maneira mais comum e direta de instalar a biblioteca pandas é usando o gerenciador de pacotes pip. Basta abrir seu terminal ou CMD e digitar o comando pip install pandas. Se tudo der certo, você deverá ver mensagens informando que a instalação foi bem-sucedida:
Como instalar o pandas pelo Anaconda?
Outra maneira popular de instalar o pandas é usando o Anaconda, uma distribuição de Python que vem com muitas bibliotecas úteis para ciência de dados e análise de dados. Ao baixar e instalar o Anaconda, você terá acesso automático à biblioteca pandas, uma vez que ela vem pré-instalada nesse ambiente.
Como usar a biblioteca pandas no Python?
Depois de instalar o pandas, você pode começar a utilizá-lo para manipular e analisar dados. A convenção é importar a biblioteca pela forma encurtada pd: import pandas as pd.
Vamos ver um exemplo básico de como carregar e visualizar dados usando pandas:
# Importar a biblioteca pandas
import pandas as pd
# Criar dados manualmente
dados = {
'Nome': ['Ana', 'Bruno', 'Carlos'],
'Idade': [23, 35, 45],
'Cidade': ['São Paulo', 'Rio de Janeiro', 'Curitiba']
}
# Criar um DataFrame (tabela) com os dados
df = pd.DataFrame(dados)
# Visualizar as duas primeiras linhas do DataFrame
print(df.head(2))Outras formas de usar a biblioteca pandas em Python
A biblioteca pandas também está disponível em outras plataformas, como o Google Colab e o Compilador de Python Online da Asimov Academy. Isso torna o pandas ainda mais acessível e prático para a análise de dados.
Acessando a biblioteca pandas no Google Colab
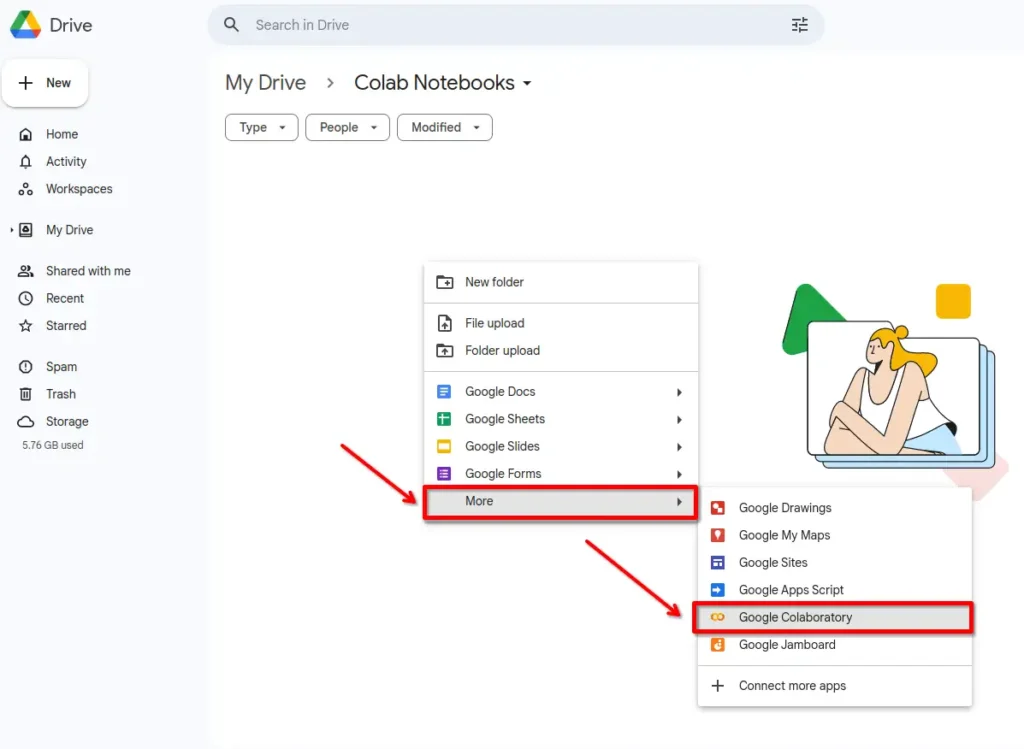
No Google Colab, você pode importar o pandas e começar a trabalhar com ele sem precisar instalar nada localmente. Para isso, acesse seu Google Drive, clique com o botão direito para abrir o menu e selecione a opção “Google Colaboratory”. Então, você será direcionado para um novo Notebook do Jupyter rodando no Google Colab, com acesso à biblioteca:
Usando a biblioteca pandas no Compilador de Python Online da Asimov Academy
Você também pode usar o pandas no Compilador de Python Online da Asimov Academy. Basta acessar o link e começar a escrever seu código – simples assim!
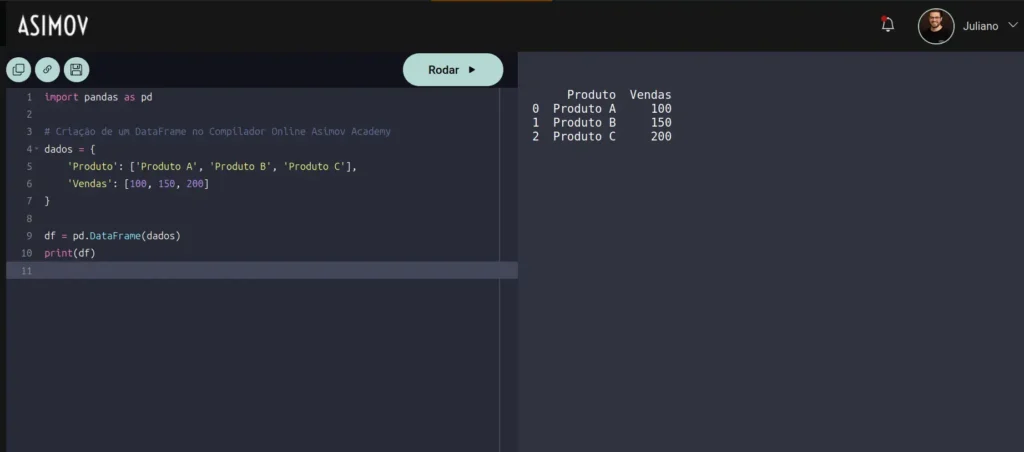
Os códigos criados podem facilmente ser compartilhados pelo link. Além disso, alunos da Asimov Academy podem salvar e editar seus códigos dentro do seu perfil, simplificando sua organização.
Experimente rodar o código abaixo clicando no botão Testar:
import pandas as pd
# Criação de um DataFrame no Compilador Online Asimov Academy
dados = {
'Produto': ['Produto A', 'Produto B', 'Produto C'],
'Vendas': [100, 150, 200]
}
df = pd.DataFrame(dados)
print(df)Conceitos fundamentais da biblioteca pandas
Agora que já sabemos o que é a biblioteca pandas e como instalá-la, vamos abordar alguns conceitos fundamentais que formam a base da biblioteca.
O que é um DataFrame do pandas?
Um DataFrame do pandas é uma estrutura de dados de duas dimensões – linhas e colunas – que formam uma tabela. Cada coluna de um DataFrame possui um tipo de dado específico.
Assim como em uma planilha do Excel, um DataFrame pode ter diversas colunas de diferentes tipos de dados, como texto, números e datas. No entanto, o DataFrame oferece muito mais flexibilidade e funcionalidade.
Veja o exemplo abaixo, onde usamos a biblioteca numpy para criar um DataFrame com valores aleatórios:
import pandas as pd
import numpy as np
dados = np.random.randn(5, 4)
df = pd.DataFrame(dados, columns=['A', 'B', 'C', 'D'])
print(df)Por que isso importa: fica mais fácil de trabalhar com DataFrames quando entendemos que eles representam tabelas.
O que é uma Series do pandas?
Uma Series do pandas é uma estrutura de dados de uma dimensão, análoga a uma coluna em uma tabela. Cada elemento em uma Series possui um índice, o que facilita sua manipulação. Por padrão, os índices são números inteiros crescentes, partindo do zero, mas podemos indicar valores para o índice usando listas
Acompanhe no exemplo de código abaixo:
import pandas as pd
dados = [10, 20, 30, 40, 50]
series = pd.Series(dados, index=['a', 'b', 'c', 'd', 'e'])
print(series)Por que isso importa: em pandas, todo DataFrame (tabela) é composto de Series (colunas) organizadas em diferentes entradas de dados (linhas).
O que é dtype em pandas?
O dtype em pandas refere-se ao tipo de dado armazenado em uma Series. Os tipos de dados comuns incluem int64 (números inteiros), float64 (números fracionados), datetime (datas e horas) e object (texto ou outros objetos).
import pandas as pd
import numpy as np
# DataFrame de exemplo
dados = np.random.randint(0, 100, size=(5,4))
df = pd.DataFrame(dados, columns=list("ABCD"))
# Verificando os tipos de dados das colunas
print(df.dtypes)Por que isso importa: o dtype de uma coluna determina o tipo de operação que é possível realizar com ela.
O que é uma série booleana em pandas?
Uma série booleana em pandas é uma Series que contém apenas valores booleanos (True ou False). Elas são frequentemente usadas para filtrar dados em um DataFrame.
Veja o exemplo abaixo, onde filtramos linhas do DataFrame de acordo com valores da coluna A:
import pandas as pd
# Criando um DataFrame de exemplo
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10],
})
# FILTRO: valores maiores que 3 na coluna 'A'
serie_booleana = df['A'] > 3
print(serie_booleana)
# Aplicando o filtro no DataFrame
df_filtrado = df[serie_booleana]
print(df_filtrado)Por que isso importa: séries booleanas são a principal forma de criar filtros em pandas. Como muitas operações de pandas naturalmente resultam em séries booleanas, o fluxo de criar e aplicar um filtro se torna bastante comum.
O que é uma operação vetorizada em pandas?
Uma operação vetorizada em pandas é uma operação que é aplicada a todos os elementos de uma Series ou DataFrame de uma só vez, sem a necessidade de loops de Python. Isso não só torna o código mais conciso, mas também acelera a operação significativamente. Operações que levariam horas em um conjunto de dados grande podem ser realizadas em minutos quando vetorizadas.
No exemplo abaixo, multiplicamos os valores da coluna A por 2 sem precisar de nenhum tipo de loop em Python:
import pandas as pd
# Criando um DataFrame de exemplo
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]})
# Multiplicando todos os valores da coluna 'A' por 2
df['A'] = df['A'] * 2
print(df)Por que isso importa: operações vetorizadas aceleram a execução de um código de forma dramática. Entender como vetorizar operações é um requisito para se tornar um analista de dados experiente.
O que é uma operação inplace no pandas?
Uma operação inplace no pandas é uma operação que modifica o DataFrame ou Series original, em vez de retornar uma nova cópia. Como nenhum dado é copiado em memória, menos espaço da memória RAM é utilizado.
No exemplo abaixo, a coluna C é removida do DataFrame df. O argumento inplace=True faz com que essa alteração aconteça no DataFrame original em vez de retornar uma cópia com a alteração:
import pandas as pd
# Criando um DataFrame de exemplo
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
# Removendo a coluna 'C' do DataFrame original
df.drop('C', axis=1, inplace=True)
print(df)Por que isso importa: operações inplace reduzem drasticamente o consumo de memória RAM durante a manipulação dos dados.
As principais funções da biblioteca pandas em Python
Agora que entendemos as bases da biblioteca pandas, vamos explorar algumas de suas principais funcionalidades.
Como criar um DataFrame novo no pandas?
Para criar um DataFrame “do zero” no pandas, você pode utilizar diferentes objetos, como listas, dicionários ou até mesmo arquivos externos.
O exemplo abaixo utiliza um dicionário como fonte de dados. No dicionário, cada chave representa o nome da coluna, enquanto o valor representa os dados da coluna respectiva:
import pandas as pd
# Criando um DataFrame a partir de um dicionário de listas
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
print(df)Como ler planilhas de Excel com pandas em Python?
Para ler planilhas de Excel com pandas, basta utilizar a função pd.read_excel() e passar o caminho para o arquivo Excel. Caso o arquivo esteja no formato CSV, há também a função pd.read_csv(), que funciona de forma semelhante:
import pandas as pd
# Lendo uma planilha Excel
df_excel = pd.read_excel('exemplo.xlsx')
print(df_excel.head())
# Lendo um arquivo CSV
df_csv = pd.read_csv('exemplo.csv')
print(df_csv.head())A documentação da função pd.read_excel() apresenta todos os outros argumentos que a função aceita. É possível selecionar a aba da planilha para ler ou então ignorar as primeiras linhas na tabela, por exemplo.
Como ler uma planilha do Google Sheets no pandas?
Se você utiliza as planilhas do Google Sheets como fonte de dados, também conseguirá acessar suas informações sem precisar baixar sua planilha e importá-la em seu script toda vez.
Para isso, gere um link de compartilhamento da planilha em Arquivo → Compartilhar → Publicar na Web. Atenção: isso fará com que os dados da planilha fiquem disponíveis para qualquer pessoa com o link!
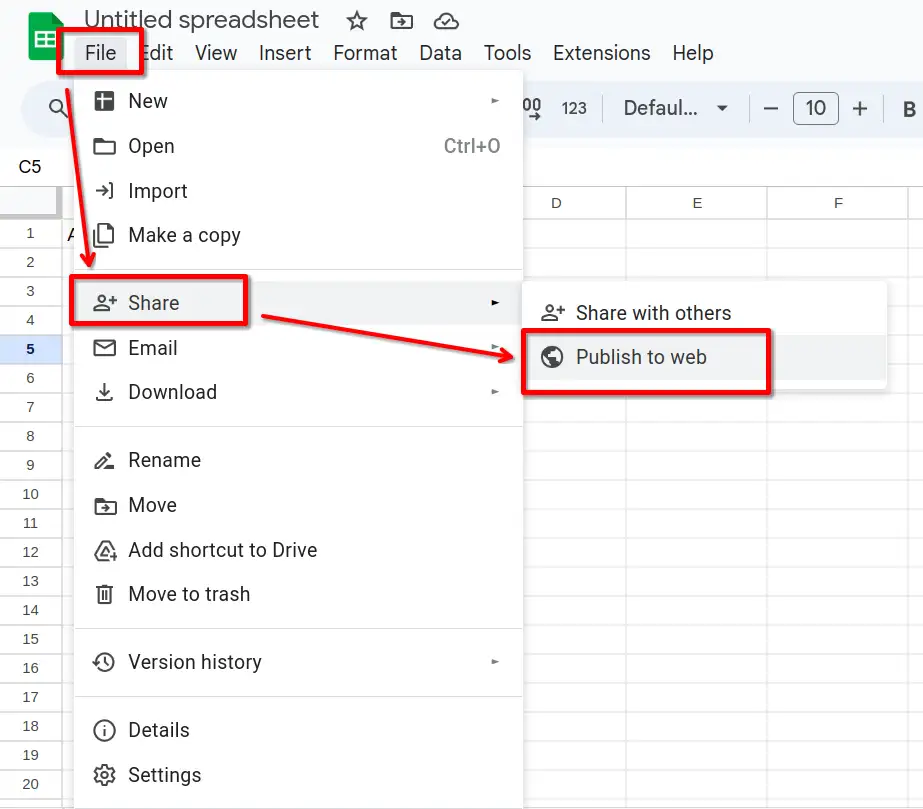
Em seguida, na janela Publicar na Web, escolha o formato CSV e clique em Publicar:
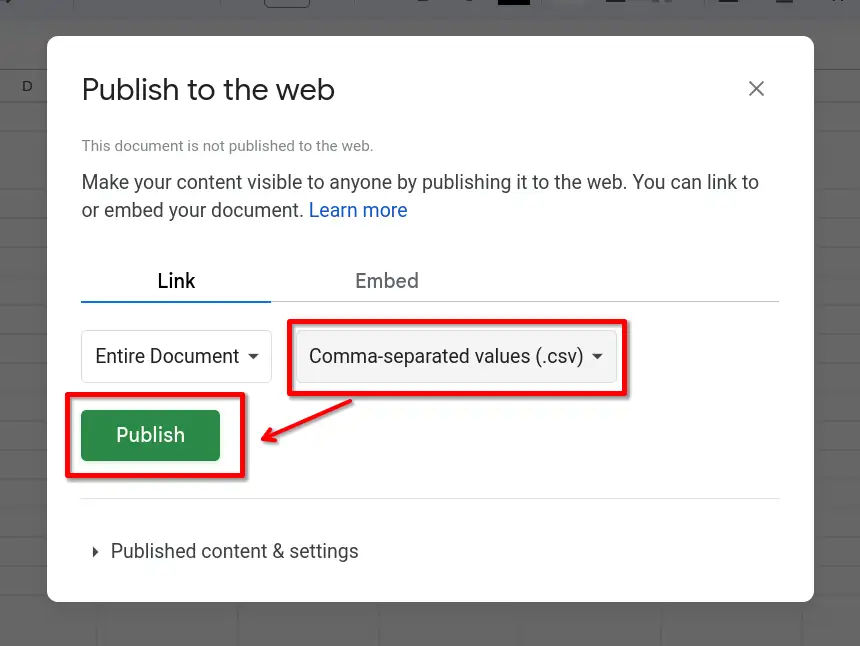
Um link será gerado com o compartilhamento direto para a planilha. Agora, basta referenciar este link dentro do seu código para baixar a planilha diretamente no pandas:
import pandas as pd
link_planilha = "https:// ... " # Link completo vai aqui
df = pd.read_csv(link_planilha)
print(df)Como obter informações descritivas do DataFrame?
Usamos o método de DataFrame df.describe() para obter informações descritivas de um DataFrame, como média, desvio padrão, valores mínimos e máximos. Já o método df.info() retorna informações gerais da tabela, como tipos de dados e número de entradas não nulas:
import pandas as pd
data = {
'Idade': [25, 30, 35, 40],
'Salário': [50000, 60000, 70000, 80000]
}
df = pd.DataFrame(data)
info_descritiva = df.describe()
print(info_descritiva)
info_geral = df.info()
print(info_geral)Também podemos acessar os atributos df.shape, df.index e df.columns para encontrar o número e valores das linhas e colunas do DataFrame:
import pandas as pd
data = {
'Idade': [25, 30, 35, 40],
'Salário': [50000, 60000, 70000, 80000]
}
df = pd.DataFrame(data)
# Obtendo formato, índice e colunas do DataFrame
print("Formato do DataFrame: ", df.shape)
print("Índice do DataFrame: ", df.index)
print("Colunas do DataFrame: ", df.columns)Como exibir os dados de uma tabela em pandas?
Para exibir os dados de um DataFrame, podemos usar os métodos df.head() e df.tail(), que mostram as primeiras e últimas linhas do DataFrame, respectivamente. Usar print(df) também é uma opção, mas algumas linhas ou colunas podem ser omitidas dependendo do tamanho do seu DataFrame:
import pandas as pd
# Criando um DataFrame de exemplo
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
# Exibindo todas as linhas do DataFrame
print(df)
# Exibindo as duas primeiras linhas do DataFrame
print(df.head(2))
# Exibindo as duas últimas linhas do DataFrame
print(df.tail(2))Como filtrar linhas e colunas de um DataFrame pelo nome?
Para filtrar linhas e colunas de um DataFrame pelo nome, podemos usar o método df.loc[]. Este é um método especial da biblioteca pandas, que funciona com base em uma sintaxe própria. Podemos passar dois argumentos em colchetes para o df.loc[], representando as linhas e colunas a serem filtradas, respectivamente.
No exemplo abaixo, note que uma série booleana é usada para selecionar as linhas a serem filtradas:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle'],
'Idade': [25, 30, 35, 40]
}
df = pd.DataFrame(data)
filtro_linhas = df['Nome'] == 'Rodrigo' # Série booleana
filtro_colunas = ['Sobrenome', 'Idade']
# Filtrando linhas e colunas pelo nome
df_filtrado = df.loc[filtro_linhas, filtro_colunas]
print(df_filtrado)Como selecionar linhas e colunas de um DataFrame pelo seu índice?
Para selecionar linhas e colunas de um DataFrame pelo seu índice, podemos usar o método df.iloc[]. Este método funciona de forma idêntica ao df.loc[], porém aceita apenas os índices (posições) dos dados para aplicar como filtro e não seus valores:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle'],
'Idade': [25, 30, 35, 40]
}
df = pd.DataFrame(data)
filtro_linhas = [0, 1, 3]
filtro_colunas = [0, 1]
# Filtrando linhas e colunas pelo índice (posição)
filtro = df.iloc[filtro_linhas, filtro_colunas]
print(filtro)Como remover uma linha ou coluna de um DataFrame do pandas?
Utilize o método df.drop() para remover linhas ou colunas de um DataFrame. Para remover uma linha, indique o índice da linha a ser removida. Para remover uma coluna, você deve especificar o nome da coluna e passar também o parâmetro axis=1.
O exemplo abaixo demonstra como remover a linha de índice 2 e a coluna Sobrenome:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
# Removendo a linha de índice 2
df_sem_linha = df.drop(2)
print(df_sem_linha)
# Removendo a coluna "Sobrenome"
df_sem_coluna = df.drop('Sobrenome', axis=1)
print(df_sem_coluna)Como criar uma nova coluna em um DataFrame do pandas?
Para criar uma nova coluna em um DataFrame do pandas, você pode utilizar colchetes ( [ ] ) ou o método df.assign().
A sintaxe com colchetes é direta: você define o nome da nova coluna e atribui os valores desejados, como em df["nome coluna"] = valores. Já o método df.assign() é útil para adicionar várias colunas de uma vez e pode ser combinado com outras operações.
O exemplo abaixo demonstra ambas as abordagens:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
# Criando uma nova coluna "Idade" usando colchetes
df['Idade'] = [25, 30, 22, 28]
print("DataFrame com a nova coluna 'Idade':")
print(df)
# Criando uma nova coluna "Cidade" usando o método assign()
df = df.assign(Cidade=['São Paulo', 'Rio de Janeiro', 'Porto Alegre', 'Curitiba'])
print("DataFrame com a nova coluna 'Cidade':")
print(df)Como adicionar uma nova linha a um DataFrame do pandas?
Para adicionar uma nova linha a um DataFrame do pandas, você pode utilizar a função pd.concat(). Esta função concatena dois DataFrames, portanto é preciso que a nova linha seja um DataFrame com colunas de mesmo nome do DataFrame original:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
# Nova linha a ser adicionada
nova_linha = pd.DataFrame({'Nome': ['Carlos'], 'Sobrenome': ['Silva']})
# Adicionando uma nova linha usando pd.concat()
df_concat = pd.concat([df, nova_linha], ignore_index=True)
print(df_concat)Outra forma comum é usar o método df.loc[] e passar o próprio tamanho do DataFrame (número de linhas) como argumento. Isso faz com que a linha seja sempre inserida no índice ao final do DataFrame:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
# Nova linha a ser adicionada
nova_linha = ['Carlos', 'Silva']
# Adicionando uma nova linha usando o método loc
df.loc[len(df)] = nova_linha
print(df)Note que esta abordagem só funciona se o DataFrame possuir índices numéricos, crescentes e partindo do zero.
Como ordenar dados de um DataFrame por uma coluna?
Para ordenar os dados de um DataFrame por uma coluna, você pode utilizar o método df.sort_values(). Esse método permite especificar a coluna pela qual os dados devem ser ordenados e se a ordenação deve ser crescente ou decrescente.
O exemplo abaixo demonstra como ordenar um DataFrame pela coluna Nome em ordem crescente e decrescente:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
# Ordenando os dados pela coluna 'Nome' em ordem crescente
df_ordenado_crescente = df.sort_values(by='Nome')
print(df_ordenado_crescente)
# Ordenando os dados pela coluna 'Nome' em ordem decrescente
df_ordenado_decrescente = df.sort_values(by='Nome', ascending=False)
print(df_ordenado_decrescente)Como agregar dados e realizar operações agrupadas?
Para agregar dados e realizar operações agrupadas em um DataFrame, você pode utilizar o método df.groupby(). Esse método permite agrupar os dados por uma ou mais colunas e aplicar funções de agregação, como soma, média, contagem, entre outras.
O exemplo abaixo demonstra como usar df.groupby() para agrupar os dados pela coluna Departamento e calcular a média e a soma dos valores nas colunas Salário e Bônus para cada grupo:
import pandas as pd
data = {
'Departamento': ['Vendas', 'RH', 'Vendas', 'RH', 'Vendas'],
'Salário': [5000, 6000, 7000, 8000, 9000],
'Bônus': [500, 600, 700, 800, 900]
}
df = pd.DataFrame(data)
# Agrupando os dados pela coluna 'Departamento' e calculando a média dos valores
df_agrupado_media = df.groupby('Departamento').mean().reset_index()
print(df_agrupado_media)
# Agrupando os dados pela coluna 'Departamento' e calculando a soma dos valores
df_agrupado_soma = df.groupby('Departamento').sum().reset_index()
print(df_agrupado_soma)Como escrever um DataFrame de pandas em uma planilha?
Para escrever um DataFrame do pandas em uma planilha, você pode utilizar os métodos df.to_excel(), passando o nome do arquivo Excel de destino como um argumento. Se preferir, pode também usar o método df.to_csv()para salvar em um arquivo CSV.
O exemplo abaixo demonstra como salvar um DataFrame em ambos os formatos:
import pandas as pd
data = {
'Nome': ['Adriano', 'Rodrigo', 'Juliano', 'Mateus'],
'Sobrenome': ['Soares', 'Tadewald', 'Faccioni', 'Kienzle']
}
df = pd.DataFrame(data)
# Salvando o DataFrame em um arquivo Excel
df.to_excel('dados.xlsx', index=False)
print("DataFrame salvo na planilha Excel 'dados.xlsx'")
# Salvando o DataFrame em um arquivo CSV
df.to_csv('dados.csv', index=False)
print("DataFrame salvo no arquivo CSV 'dados.csv'")Como aprender mais sobre a biblioteca Pandas em Python?
O Pandas é uma das ferramentas mais importantes para quem tem vontade de ingressar na carreira de dados, pois é muito útil tanto para visualização quanto para análise de dados. Neste artigo, aprendemos a instalar a biblioteca pandas em Python, entendemos os seus conceitos principais, como DataFrames e Series, e abordamos diversas manipulações de dados que podemos fazer com ela.
Para aprimorar ainda mais suas habilidades em análise de dados, confira nossa Trilha de Análise e Visualização de Dados, que oferece uma jornada completa de aprendizado para dominar o Pandas e outras ferramentas essenciais, como as bibliotecas Matplotlib e Seaborn, o uso de bancos de dados SQL, e a análise exploratória de dados.
Mas, se você ainda está iniciando em Python, inscreva-se agora no nosso curso gratuito, Python para iniciantes: do zero ao primeiro projeto, onde você aprende a criar um dashboard interativo com Pandas e Streamlit em menos de 2 horas.
Invista em seu desenvolvimento profissional hoje mesmo e leve suas habilidades em análise de dados para o próximo nível!
Você também pode gostar:







Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp