BLOG

Bibliotecas Python para visualização de dados: aprenda a criar gráficos profissionais



Se você está começando na área de análise de dados e já tem alguma familiaridade com o Excel, provavelmente já se deparou com a necessidade de criar gráficos e visualizações para entender melhor os dados. A visualização de dados com Python é uma habilidade poderosa que pode levar suas análises a um novo patamar. Neste artigo, vamos explorar o que é visualização de dados, o conceito de dataviz, as principais ferramentas de visualização de dados e por que usar Python para essa tarefa.
Vamos começar entendendo o que é visualização de dados e o como podemos usá-la em Python.
A visualização de dados é o processo de transformar dados brutos em gráficos que simplifiquem a sua interpretação. É a diferença entre você olhar para uma planilha cheia de colunas e números e criar um gráfico intuitivo e visualmente atrativo, com o qual você facilmente identifica padrões e tendências.
O termo “dataviz” é uma abreviação de data visualization (visualização de dados, em inglês). Como área do conhecimento, a dataviz envolve o estudo de representações visuais de dados que transmitam uma mensagem clara e eficaz para os seus ouvintes (gestores, membros da equipe, analistas de dados e stakeholders em geral).
Qual é a melhor forma de apresentar os dados da nossa empresa? Gráfico de linha, de barras ou de pizza? A dataviz é a área que se aprofunda em questões como esta.
Existem várias ferramentas disponíveis para visualização de dados, cada uma com suas próprias vantagens e desvantagens. Algumas das mais populares incluem:
Python é uma das linguagens de programação mais populares para análise e visualização de dados. Aqui estão algumas razões pelas quais você deve usar Python para visualização de dados profissional:
Agora que entendemos a importância da visualização de dados e por que Python é uma excelente escolha para essa tarefa, vamos explorar como usar Python para criar gráficos e visualizações.
Caso você queira acompanhar os exemplos de código, lembre-se de instalar as bibliotecas em seu ambiente de Python. Para isso, utilize o gerenciador de pacotes pip, conforme o exemplo a seguir:
pip install matplotlib seaborn plotly pandas numpyPython possui diversas bibliotecas que facilitam a criação de gráficos e visualizações. A seguir, vamos conhecer as mais populares.
Matplotlib é uma das bibliotecas mais antigas e amplamente utilizadas para visualização de dados em Python. Ela permite criar gráficos estáticos, animados e interativos com uma grande variedade de estilos e personalizações.
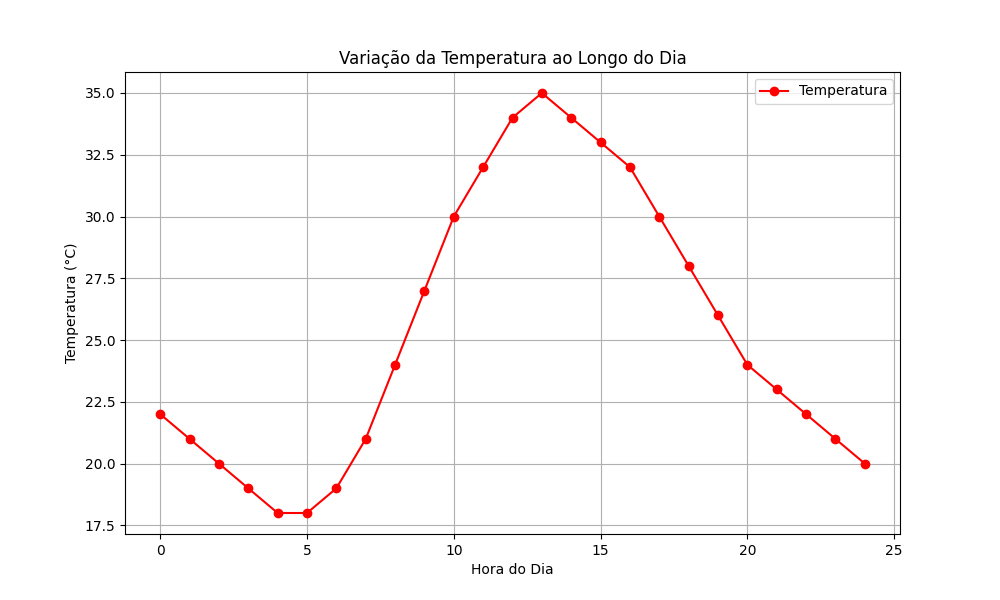
No exemplo abaixo, usamos o Matplotlib para plotar a temperatura ao longo de um dia em um gráfico. A função mais relevante para isto é a plt.plot(), que plota os dados de fato. As demais funções servem para configurar os eixos e estilizar a figura. Ao final, usamos plt.show() para exibir o gráfico gerado em tela:
import matplotlib.pyplot as plt
import numpy as np
# Dados de exemplo: horas do dia e temperaturas correspondentes
horas = range(25)
temperaturas = [
22, 21, 20, 19, 18, 18,
19, 21, 24, 27, 30, 32,
34, 35, 34, 33, 32, 30,
28, 26, 24, 23, 22, 21, 20,
]
# Criando o gráfico
plt.figure(figsize=(10, 6))
plt.plot(horas, temperaturas, color='red', linestyle='-', marker='o', label='Temperatura')
plt.title('Variação da Temperatura ao Longo do Dia')
plt.xlabel('Hora do Dia')
plt.ylabel('Temperatura (°C)')
plt.legend()
plt.grid(True)
plt.show()Esta é a figura resultante:
Seaborn é uma biblioteca baseada no Matplotlib capaz de criar gráficos estatísticos atraentes e informativos. Ela é especialmente útil para visualizações complexas e análise exploratória de dados.
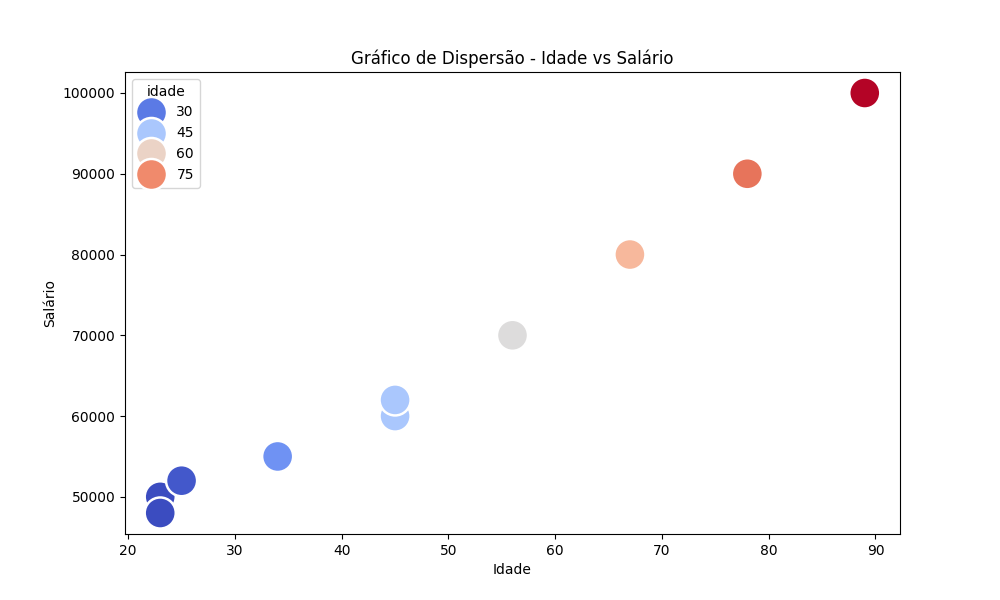
No exemplo de código abaixo, utilizamos Seaborn para plotar dados de salário e idade estruturados dentro de um DataFrame do Pandas. Note que o Seaborn é particularmente útil para plotar dados em DataFrames, pois podemos utilizar os nomes das colunas para configurarmos as séries de dados e grupamentos na figura resultante:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# Dados de exemplo
data = {
'idade': [23, 45, 56, 67, 34, 25, 78, 89, 45, 23],
'salario': [50000, 60000, 70000, 80000, 55000, 52000, 90000, 100000, 62000, 48000]
}
df = pd.DataFrame(data)
# Criando o gráfico
plt.figure(figsize=(10, 6))
sns.scatterplot(x='idade', y='salario', data=df, hue='idade', palette='coolwarm', s=100)
plt.title('Gráfico de Dispersão - Idade vs Salário')
plt.xlabel('Idade')
plt.ylabel('Salário')
plt.show()Segue a figura resultante do código acima:
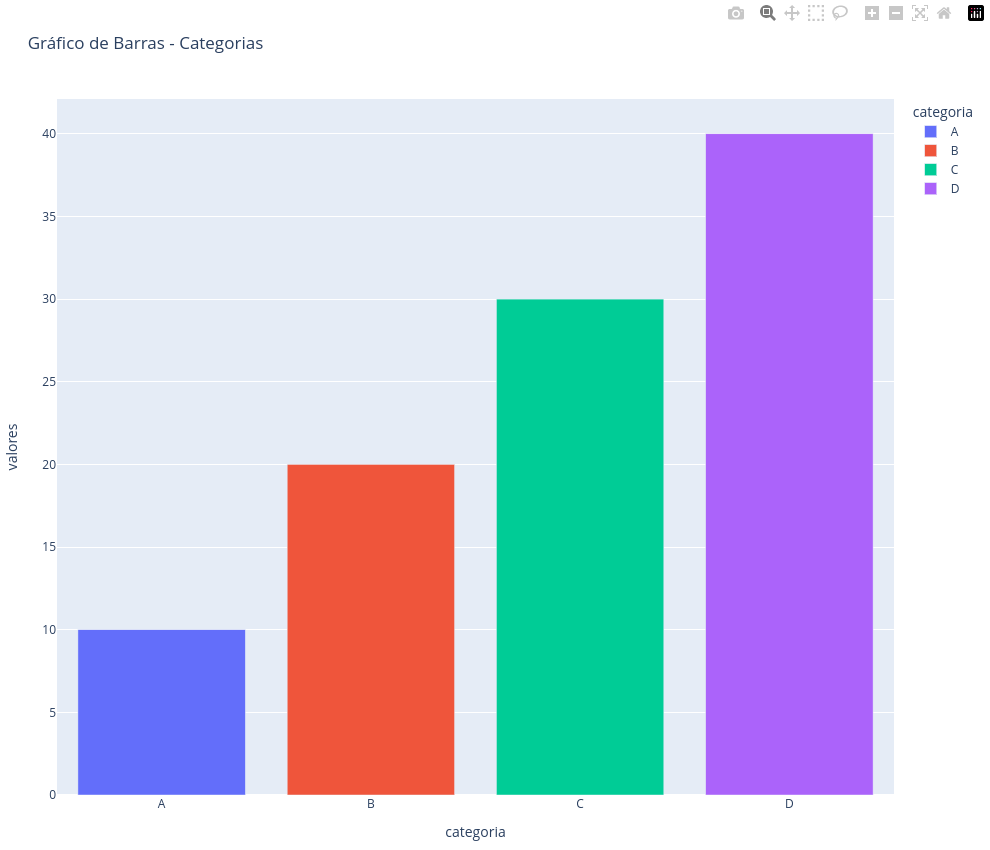
Plotly é uma biblioteca moderna que permite criar gráficos interativos e altamente personalizáveis, como os de um dashboard. É ideal para cenários onde a interatividade é um diferencial, como em web apps criados com a biblioteca Dash de Python.
No exemplo abaixo, criamos um gráfico de barras com alguns dados simples. Ao executar o método fig.show(), o gráfico abre em uma janela do seu navegador web, através da qual é possível clicar e interagir com os dados apresentados:
import plotly.express as px
import pandas as pd
# Dados de exemplo
data = {
'categoria': ['A', 'B', 'C', 'D'],
'valores': [10, 20, 30, 40]
}
df = pd.DataFrame(data)
# Criando o gráfico
fig = px.bar(df, x='categoria', y='valores', color='categoria', title='Gráfico de Barras - Categorias')
fig.show()Após rodar o código acima, a figura a seguir aparecerá no seu navegador:
Com Python, você pode criar uma ampla variedade de gráficos, desde os mais simples até os mais complexos! A seguir, vamos passar por alguns exemplos de diferentes tipos de gráficos que podemos gerar com Python.
Note que, nestes exemplos, estamos simulando dados (criando-os diretamente no código). Tipicamente, você usará dados lidos de uma planilha ou base de dados própria.
Os gráficos de linha são ideais para mostrar tendências ao longo do tempo.
import matplotlib.pyplot as plt
import numpy as np
# Dados de exemplo: anos e população global em bilhões
anos = np.arange(1950, 2021, 10)
populacao = [2.5, 3.0, 3.7, 4.5, 5.3, 6.1, 7.0, 7.8]
# Criando o gráfico
plt.figure(figsize=(10, 6))
plt.plot(anos, populacao, color='blue', linestyle='-', marker='o', label='População Global')
plt.title('Crescimento Populacional Global (1950-2020)')
plt.xlabel('Ano')
plt.ylabel('População (bilhões)')
plt.legend()
plt.grid(True)
plt.show()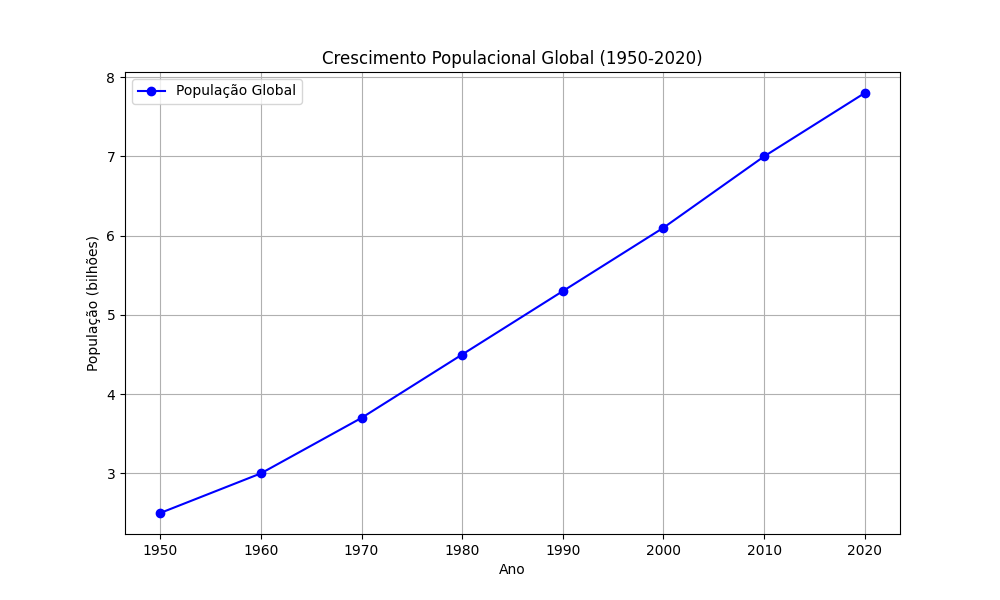
Os gráficos de barras são ótimos para comparar diferentes categorias.
import matplotlib.pyplot as plt
# Dados de exemplo
categorias = ['A', 'B', 'C', 'D']
valores = [5, 7, 3, 8]
# Criando o gráfico
plt.figure(figsize=(10, 6))
plt.bar(categorias, valores, color=['#FF9999', '#66B2FF', '#99FF99', '#FFCC99'])
plt.title('Gráfico de Barras - Categorias')
plt.xlabel('Categorias')
plt.ylabel('Valores')
plt.show()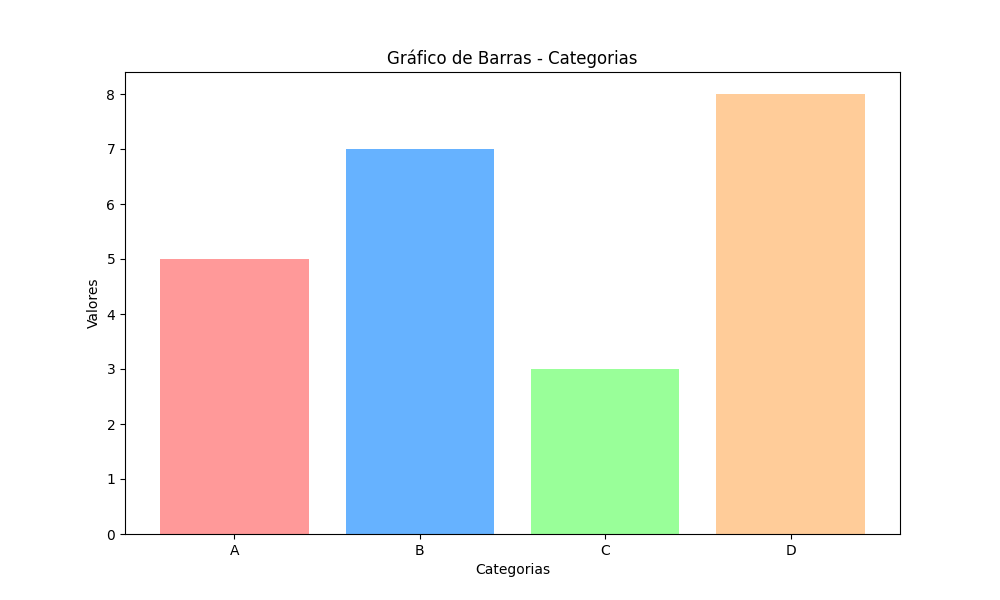
Os histogramas são usados para mostrar a distribuição de um conjunto de dados.
import matplotlib.pyplot as plt
import numpy as np
# Dados de exemplo
dados = np.random.randn(1000)
# Criando o histograma
plt.figure(figsize=(10, 6))
plt.hist(dados, bins=30, color='skyblue', edgecolor='black')
plt.title('Histograma - Distribuição de Dados')
plt.xlabel('Valor')
plt.ylabel('Frequência')
plt.show()
Os gráficos de dispersão são úteis para visualizar a relação entre duas variáveis.
import matplotlib.pyplot as plt
import pandas as pd
# Dados de exemplo: horas de estudo por semana e notas obtidas em um exame final
data = {
'horas_estudo': [5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100],
'nota_exame': [50, 55, 60, 65, 70, 75, 78, 80, 82, 85, 87, 88, 90, 92, 93, 95, 96, 98, 99, 100]
}
df = pd.DataFrame(data)
# Criando o gráfico
plt.figure(figsize=(10, 6))
plt.scatter(df['horas_estudo'], df['nota_exame'], color='green')
plt.title('Gráfico de Dispersão - Horas de Estudo vs Nota do Exame')
plt.xlabel('Horas de Estudo por Semana')
plt.ylabel('Nota do Exame')
plt.grid(True)
plt.show()
Os mapas de calor (heatmaps) são excelentes para mostrar a densidade de dados em uma matriz.
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Dados de exemplo: média mensal de temperatura (°C) em diferentes cidades ao longo de um ano
cidades = ['São Paulo', 'Rio de Janeiro', 'Belo Horizonte', 'Curitiba', 'Porto Alegre', 'Brasília']
meses = ['Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun', 'Jul', 'Ago', 'Set', 'Out', 'Nov', 'Dez']
temperaturas = np.array([
[25, 26, 25, 23, 20, 18, 17, 18, 20, 22, 24, 25], # São Paulo
[28, 30, 29, 27, 24, 22, 21, 22, 24, 26, 27, 28], # Rio de Janeiro
[27, 28, 27, 25, 22, 20, 19, 20, 23, 25, 26, 27], # Belo Horizonte
[22, 23, 22, 20, 17, 15, 14, 15, 17, 19, 21, 22], # Curitiba
[25, 26, 25, 23, 20, 18, 17, 18, 20, 22, 24, 25], # Porto Alegre
[26, 27, 26, 24, 21, 19, 18, 19, 21, 23, 24, 26], # Brasília
])
# Criando o mapa de calor
plt.figure(figsize=(12, 6))
sns.heatmap(temperaturas, annot=True, cmap='coolwarm', xticklabels=meses, yticklabels=cidades)
plt.title('Mapa de Calor - Média Mensal de Temperatura (°C)')
plt.xlabel('Mês')
plt.ylabel('Cidade')
plt.show()
Sim, Python é excelente para gerar gráficos bonitos e personalizados! As bibliotecas Matplotlib, Seaborn e Plotly são capazes de gerar figuras altamente customizáveis e esteticamente agradáveis.
A personalização é uma das grandes vantagens de usar Python para visualização de dados. Você pode ajustar cores, estilos de linha, fontes e muito mais para criar gráficos que destacam exatamente o que você precisa!
Sim, é totalmente possível fazer gráficos a partir de uma planilha com Python! A biblioteca Pandas facilita a leitura de arquivos Excel e CSV, permitindo que você manipule os dados e crie gráficos com facilidade.
No exemplo de código a seguir, utilizamos Pandas para ler os dados de uma planilha no Google Sheets (através de um link de compartilhamento público) e geramos um gráfico com Matplotlib:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Lendo os dados do Google Sheets
url = "https://docs.google.com/spreadsheets/d/e/2PACX-1vQK--NNvKEZXxIhTN4LfmvWtwpltuLdjuKprimSRYSapRaqmPntNE6lKXug1l1VV2n1xEKuCPydmRnf/pub?output=csv"
df = pd.read_csv(url)
# Convertendo a coluna de data para o tipo datetime
df['data'] = pd.to_datetime(df['data'])
# Receita total por vendedor
receita_por_vendedor = df.groupby('vendedor')['preco'].sum().reset_index()
# Renomear colunas
receita_por_vendedor.columns = ['Vendedor', 'Receita Total']
# Plotando a Receita Total por Vendedor
plt.figure(figsize=(10, 6))
sns.barplot(x='Vendedor', y='Receita Total', hue='Vendedor', data=receita_por_vendedor, palette='viridis')
plt.title('Receita Total por Vendedor')
plt.xlabel('Vendedor')
plt.ylabel('Receita Total')
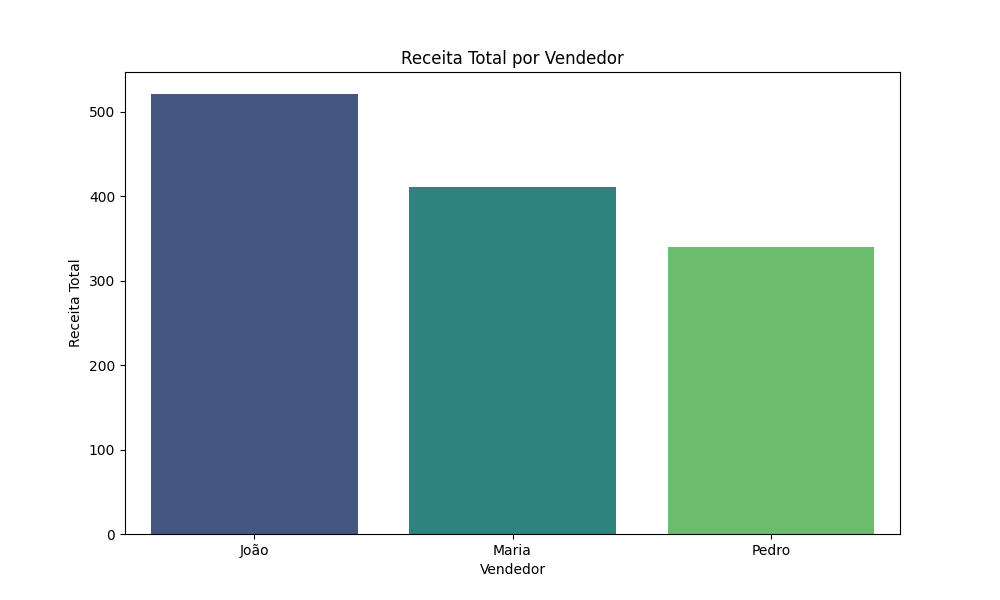
plt.show()O resultado está na imagem abaixo – você pode testá-lo em tempo real no nosso Compilador de Python Online:
Agora que você já conhece as principais bibliotecas e tipos de gráficos que pode criar com Python, vamos explorar alguns exemplos práticos de visualização de dados. Esses exemplos vão te ajudar a entender como aplicar esses conceitos em situações do mundo real.
Caso você ache os códigos muito complexos, recomendamos seguir os conhecimentos da nossa Trilha de Análise e Visualização de Dados com Python!
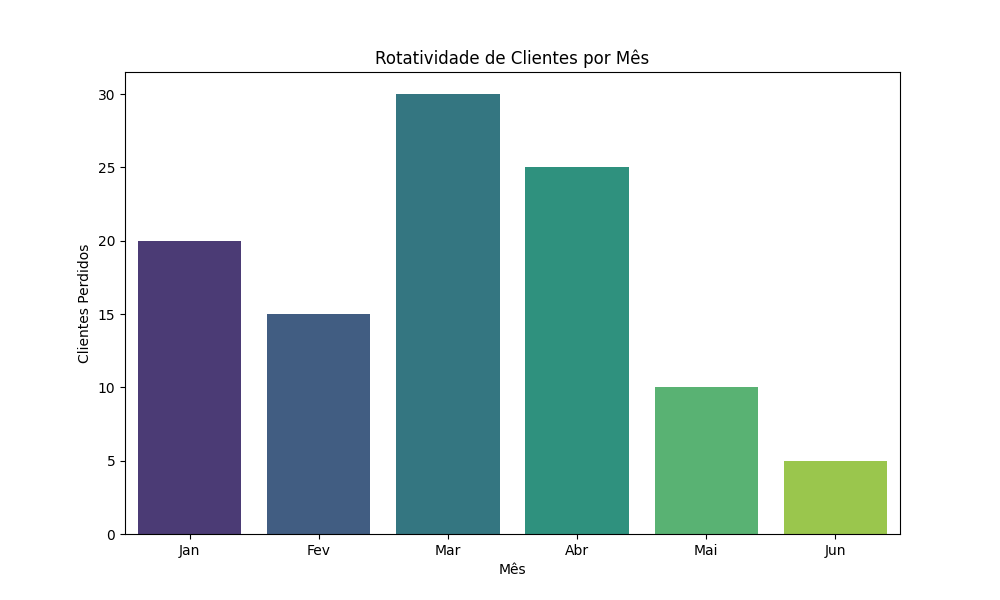
A rotatividade de clientes (churn rate) é uma métrica crucial para empresas que desejam entender a lealdade de seus clientes. Vamos criar um gráfico de barras para visualizar a rotatividade de clientes usando a biblioteca Seaborn:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Dados fictícios de rotatividade de clientes
data = {
'Mês': ['Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun'],
'Clientes Perdidos': [20, 15, 30, 25, 10, 5]
}
df = pd.DataFrame(data)
# Criando o gráfico de barras
plt.figure(figsize=(10, 6))
sns.barplot(x='Mês', y='Clientes Perdidos', data=df, palette='viridis')
plt.title('Rotatividade de Clientes por Mês')
plt.xlabel('Mês')
plt.ylabel('Clientes Perdidos')
plt.show()Com base no gráfico abaixo, podemos ver que março foi o pior mês em termos de churn rate. Contudo, esta métrica melhorou desde então e atingiu o seu mínimo em junho:
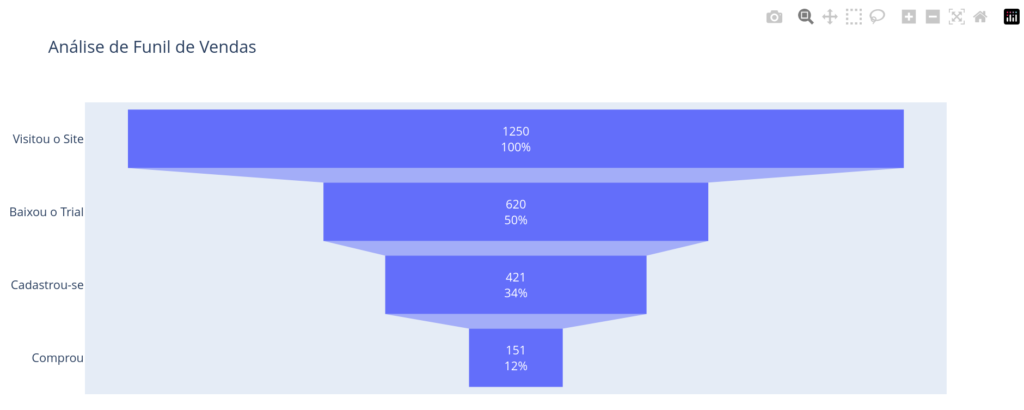
O funil de vendas é uma representação visual das etapas que um cliente percorre desde o primeiro contato até a compra. Vamos usar a biblioteca Plotly para criar um gráfico de funil interativo, utilizando para isso o objeto go.Funnel:
import plotly.graph_objects as go
# Dados de exemplo
estagios = ['Visitou o Site', 'Baixou o Trial', 'Cadastrou-se', 'Comprou']
valores = [1250, 620, 421, 151]
# Gráfico de funil
fig = go.Figure(go.Funnel(
y = estagios,
x = valores,
textinfo = "value+percent initial"))
fig.update_layout(title='Análise de Funil de Vendas')
fig.show()O gráfico gerado permite entender em quais etapas o maior número de clientes está sendo perdido – de modo que possamos melhorar nosso funil de vendas:
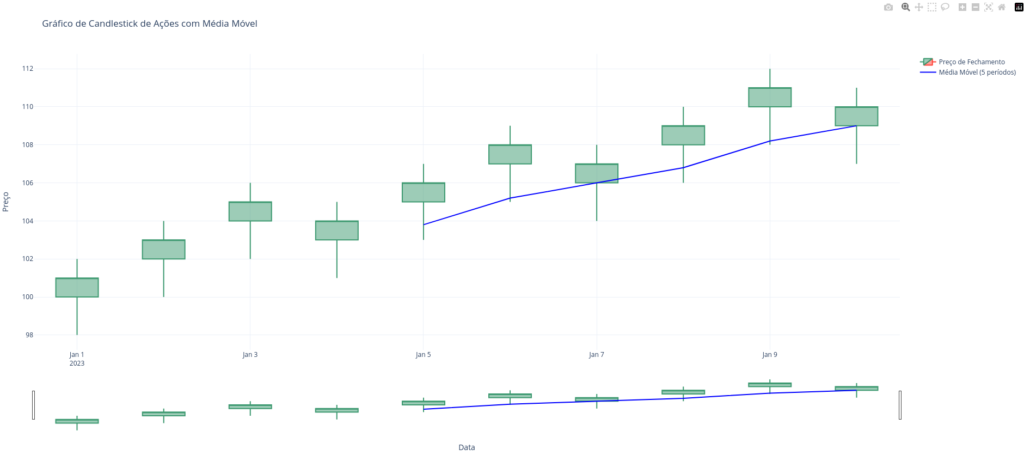
A análise de dados financeiros é fundamental para investidores e analistas interessados em Trading Quantitativo. Vamos criar um gráfico de candlestick para visualizar os dados de ações usando a biblioteca Plotly:
import pandas as pd
import plotly.graph_objects as go
# Dados fictícios de ações
data = {
'Data': pd.date_range(start='2023-01-01', periods=10, freq='D'),
'Abertura': [100, 102, 104, 103, 105, 107, 106, 108, 110, 109],
'Alta': [102, 104, 106, 105, 107, 109, 108, 110, 112, 111],
'Baixa': [98, 100, 102, 101, 103, 105, 104, 106, 108, 107],
'Fechamento': [101, 103, 105, 104, 106, 108, 107, 109, 111, 110]
}
df = pd.DataFrame(data)
# Calculando a média móvel de 5 períodos
df['MM5'] = df['Fechamento'].rolling(window=5).mean()
# Criando o gráfico de candlestick com a média móvel
fig = go.Figure(data=[go.Candlestick(
x=df['Data'],
open=df['Abertura'],
high=df['Alta'],
low=df['Baixa'],
close=df['Fechamento'],
name='Preço de Fechamento'
)])
# Adicionando a média móvel ao gráfico
fig.add_trace(go.Scatter(
x=df['Data'],
y=df['MM5'],
mode='lines',
name='Média Móvel (5 períodos)',
line=dict(color='blue', width=2)
))
fig.update_layout(title='Gráfico de Candlestick de Ações com Média Móvel',
xaxis_title='Data',
yaxis_title='Preço',
template='plotly_white')
fig.show()Com base no código acima, conseguimos plotar os dados do mercado financeiro no formato de candlestick, junto a uma média móvel:
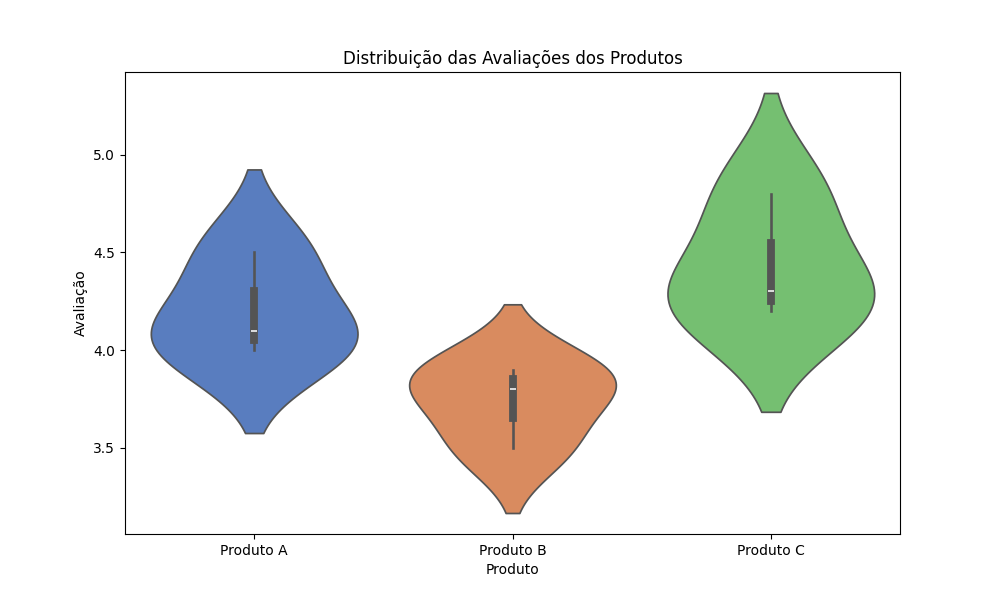
Avaliações de produtos são essenciais para entender a satisfação dos clientes. Vamos criar um gráfico de violino para visualizar a distribuição das avaliações usando a biblioteca Seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Dados fictícios de avaliações
data = {
'Produto': ['Produto A', 'Produto B', 'Produto C'] * 3,
'Avaliação': [4.5, 3.8, 4.2, 4.0, 3.5, 4.8, 4.1, 3.9, 4.3]
}
df = pd.DataFrame(data)
# Criando o gráfico de violino
plt.figure(figsize=(10, 6))
sns.violinplot(x='Produto', y='Avaliação', data=df, hue='Produto', palette='muted', legend=False)
plt.title('Distribuição das Avaliações dos Produtos')
plt.xlabel('Produto')
plt.ylabel('Avaliação')
plt.show()No gráfico abaixo, fica claro que o Produto B é o que possui pior distribuição de avaliações, portanto deve satisfazer pouco os clientes do marketplace:
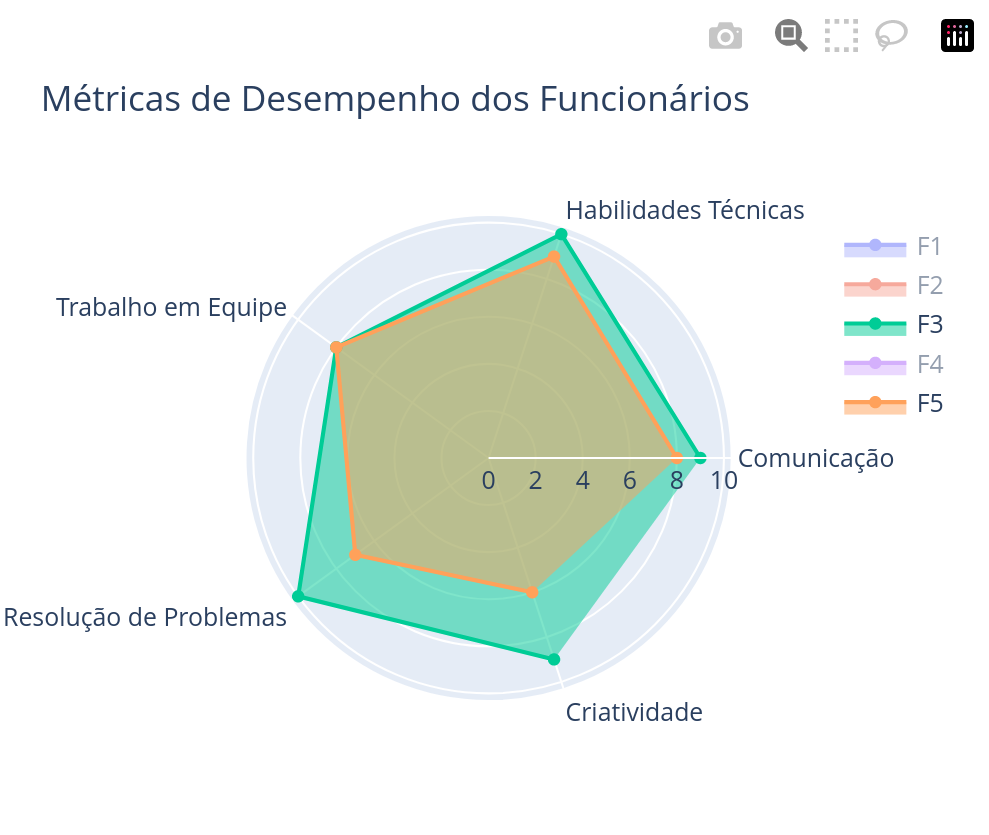
A performance dos funcionários é um indicador importante para a gestão de equipes. Vamos criar um gráfico de dispersão para visualizar a relação entre a experiência e a performance dos funcionários usando a biblioteca Matplotlib:
import pandas as pd
import seaborn as sns
import plotly.graph_objects as go
# Dados de exemplo
dados = {
'Funcionário': ['F1', 'F2', 'F3', 'F4', 'F5'],
'Comunicação': [8, 7, 9, 6, 8],
'Habilidades Técnicas': [9, 8, 10, 7, 9],
'Trabalho em Equipe': [7, 8, 8, 9, 8],
'Resolução de Problemas': [8, 9, 10, 6, 7],
'Criatividade': [7, 8, 9, 7, 6],
'Departamento': ['Vendas', 'Engenharia', 'RH', 'Engenharia', 'Vendas'],
'Ano': [2021, 2021, 2021, 2021, 2021],
'Taxa de Atrito': [0.1, 0.2, 0.3, 0.4, 0.5]
}
df = pd.DataFrame(dados)
# Gráfico radar para desempenho dos funcionários
categorias = ['Comunicação', 'Habilidades Técnicas', 'Trabalho em Equipe', 'Resolução de Problemas', 'Criatividade']
fig = go.Figure()
for i, linha in df.iterrows():
fig.add_trace(go.Scatterpolar(
r=[linha[cat] for cat in categorias],
theta=categorias,
fill='toself',
name=linha['Funcionário']
))
fig.update_layout(title='Métricas de Desempenho dos Funcionários')
fig.show()
# Heatmap de atrito
atrito = df.pivot("Departamento", "Ano", "Taxa de Atrito")
plt.figure(figsize=(10, 6))
sns.heatmap(atrito, annot=True, cmap="YlGnBu")
plt.title('Heatmap de Taxa de Atrito')
plt.show()O gráfico gerado nos permite comparar funcionários dentro de cada um dos aspectos avaliados:
A visualização de dados com Python é uma habilidade essencial para qualquer analista de dados. Com as bibliotecas Matplotlib, Seaborn e Plotly, você pode criar gráficos e visualizações poderosas que ajudam a transformar dados brutos em insights valiosos.
Se você está interessado em se aprofundar mais nesse assunto, confira a Trilha de cursos: “Análise e Visualização de Dados”, da Asimov Academy. E, para aprender mais sobre como criar gráficos interativos e customizáveis, recomendamos os seguintes cursos da Trilha:
Com essas ferramentas e conhecimentos, você estará bem equipado para transformar dados em insights valiosos e tomar decisões informadas. Conte com a Asimov na sua jornada de visualização de dados com Python!

Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:




Comentários
30xp