BLOG

Engenharia de dados: o que é, o que faz e como iniciar na área

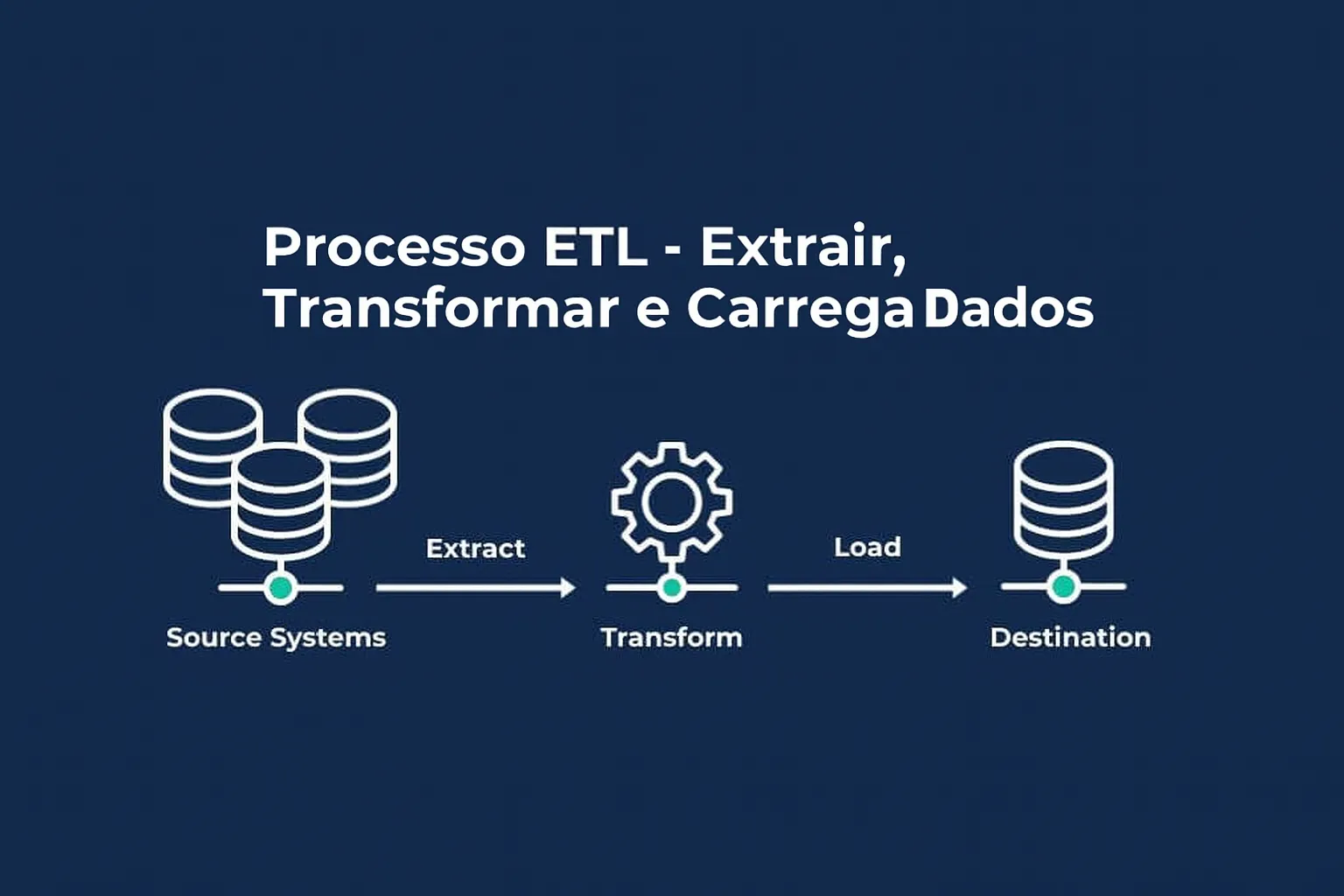

A sigla ETL vem de Extração, Transformação e Carga de Dados. Na prática, é um processo que conecta diferentes sistemas, organiza as informações e entrega tudo pronto para análise em um repositório centralizado, como um Data Warehouse ou Data Lake.
No dia a dia das empresas, dados surgem de todos os lados — sistemas internos como CRM e ERP, planilhas, aplicativos, arquivos externos, entre outras fontes. O desafio está em transformar esse volume enorme e desorganizado de informações em algo realmente útil para quem precisa tomar decisões. É aí que entra o ETL.
Tudo começa com a extração, que busca dados onde quer que eles estejam. Pode ser em um banco interno da empresa, em um sistema de vendas, numa planilha antiga ou até em fontes externas.
Depois vem a transformação, etapa em que os dados passam por uma verdadeira “faxina”: são limpos, padronizados, enriquecidos e estruturados para que façam sentido no contexto de negócio. É aqui que se garante que os dados estejam corretos, coerentes e prontos para serem analisados.
Por fim, temos a carga dos dados, agora organizados e confiáveis, são enviados para um ambiente seguro e centralizado. É nesse espaço que analistas, gestores e times estratégicos podem acessar as informações, criar relatórios, fazer cruzamentos e descobrir oportunidades.
O ETL é essencial para qualquer empresa que queira se apoiar em dados de verdade, aquelas que se consideram data-driven. Além disso, com dados bem tratados, a empresa reduz riscos, evita decisões baseadas em achismos e ganha agilidade para responder ao mercado. O ETL também abre caminho para análises mais sofisticadas, como uso de inteligência artificial, machine learning e previsões mais precisas.
Outro ponto importante: quando os dados seguem um processo estruturado e rastreável, fica muito mais fácil cumprir com leis de proteção de dados, como a LGPD.

Organizar dados dispersos em um ambiente onde eles possam contar histórias e embasar decisões é um desafio. O ETL faz exatamente isso, em três passos que conversam entre si para deixar tudo pronto para análise.
Primeiramente, o sistema “conversa” com cada fonte: bancos relacionais (MySQL, PostgreSQL), APIs, planilhas, sistemas ERP ou CRM. Você pode optar por puxar tudo de uma vez (carga completa), só o que mudou desde a última vez (carga incremental) ou acionar um gatilho sempre que houver atualização.
Imagine, por exemplo, trazer diariamente o extrato de vendas de uma loja virtual direto do MySQL de forma automática.
Com os dados em mãos, começa a “faxina”:
É nessa fase que a informação ganha contexto, garantindo relatórios confiáveis.
Prontos para uso, os dados seguem para o repositório escolhido: Data Warehouse, Data Lake ou um banco analítico, como BigQuery ou PostgreSQL. O carregamento também pode ser total ou incremental, de acordo com o volume e a criticidade. Aí, seu time de BI, cientistas de dados e gestores acessam tudo num mesmo lugar, sem surpresas.
Em projetos de grande escala, é comum sobrepor parte dessas etapas: enquanto um lote de registros é extraído, outro já passa pela transformação e um terceiro é carregado. Essa engrenagem paralela economiza horas de processamento e entrega insights cada vez mais frescos.
Quando falamos em engenharia de dados, o ETL é o ponto central que mantém tudo funcionando em harmonia. Sem ele, os dados ficariam espalhados, sem padrão e, no fim das contas, pouco confiáveis.
Veja por que esse processo é tão valorizado na engenharia de dados:
O ETL limpa e padroniza as informações que chegam de diferentes fontes, sejam sistemas legados, planilhas, APIs ou bancos de dados. Isso evita duplicatas, corrige registros inconsistentes e garante que todo mundo trabalhe com a mesma versão dos dados.
Em vez de dedicar horas a tarefas manuais de formatação e movimentação de arquivos, os engenheiros de dados automatizam essas rotinas com pipelines de ETL. Assim, sobra energia para criar modelos, explorar novas ferramentas e propor melhorias que realmente impactam o negócio.
Ao concentrar tudo num único repositório Data Warehouse, Data Lake ou outro ambiente analítico, o ETL oferece uma fonte única da verdade. Dashboards, painéis de BI e algoritmos de machine learning se beneficiam de dados prontos para uso, sem ter que lidar com “sujeira” ou faltas de informação.
Mais do que unificar dados atuais, o ETL consegue agregar registros antigos e novos, possibilitando análises históricas. Isso ajuda a traçar tendências, entender padrões de comportamento e medir o impacto de mudanças ao longo do tempo.
Conforme a empresa expande seus sistemas e gera cada vez mais informações, um pipeline de ETL bem desenhado se ajusta à demanda. É uma estrutura que cresce junto com o volume de dados, mantendo performance e qualidade.
Em mercados que exigem rastreabilidade e controle rígido de informações, como financeiro, saúde e telecom, o ETL garante que cada dado esteja registrado adequadamente, facilitando auditorias e relatórios de conformidade.
Sem esse processo, qualquer iniciativa de análise ou inteligência ficaria prejudicada pela falta de padronização e pela desconfiança na qualidade das informações.
Perfeitas para quem já tem uma infraestrutura local e quer uma solução madura, com interface visual e suporte consolidado.
Se você já trabalha com AWS, Azure ou Google Cloud, usar a ferramenta da própria nuvem simplifica permissões, escalabilidade e integrações.
Para quem já ama código, essas opções permitem criar pipelines como se fosse um projeto de software, com versionamento, testes e deploy.
Quando uma empresa junta dados de centenas de fontes, sistemas de vendas, sensores de fábrica, aplicações em nuvem, planilhas antigas e muito mais, é preciso um método claro para transformar esse caos em inteligência. Surgem então duas estratégias: ETL e ELT. Ambas passam por três etapas (Extração, Transformação, Carga), mas a ordem e o “onde” das transformações fazem toda a diferença.
| Aspecto | ETL | ELT |
| Onde se transforma? | Em servidor de processamento intermediário | Diretamente no data warehouse / data lake |
| Tipo de dado mais comum | Estruturado (tabelas) | Qualquer formato (estruturado ou não) |
| Velocidade inicial | Mais lenta (transformação antes da carga) | Mais rápida (carga imediata) |
| Custo de infraestrutura | Exige ambiente extra para transformações | Aproveita recursos existentes na nuvem |
| Flexibilidade | Boa para processos definidos e estáveis | Ideal para experimentação e escalabilidade |
Em grandes empresas, não é raro combinar ETL e ELT. Por exemplo, usar ETL para dados críticos de sistemas legados e ELT para novos fluxos de IoT ou log de aplicativos. Assim, cada fonte segue o caminho mais eficiente até o analista.
No fim, tanto ETL quanto ELT têm o mesmo objetivo: entregar dados limpos e confiáveis para gerar insights. A escolha depende da origem dos dados, do volume, da velocidade que você precisa e da arquitetura disponível.
Agora que já entendemos o que é ETL e por que ele é tão importante no mundo dos dados, vamos ver isso funcionando na prática. Abaixo, você confere um exemplo de pipeline ETL bem direto, desenvolvido em Python, que passa pelas três etapas do processo de extração, transformação e carga.
A ideia aqui é buscar dados de uma API pública, aplicar uma transformação simples e, por fim, salvar essas informações em um arquivo CSV. É um ótimo ponto de partida para quem quer começar a criar seus próprios fluxos de dados.
Nesta primeira etapa, usamos a biblioteca requests para acessar a API que fornece dados fictícios no formato JSON. Esse tipo de dado é comum em integrações com APIs, e aqui vamos pegar uma lista de 100 posts simulados:
import requests
def extract():
url = "https://jsonplaceholder.typicode.com/posts"
response = requests.get(url)
response.raise_for_status() # Garante que a requisição foi bem-sucedida
data = response.json()
return dataCom os dados em mãos, usamos o pandas para organizar tudo em um DataFrame, uma estrutura que lembra uma tabela. Em seguida, criamos uma nova coluna chamada title_length, que indica quantos caracteres tem o título de cada post. Também fazemos uma checagem para evitar problemas com valores nulos (apesar de, neste exemplo, não haver):
import pandas as pd
def transform(data):
df = pd.DataFrame(data)
df['title_length'] = df['title'].apply(len) # Cria a nova coluna com tamanho do título
df.fillna('', inplace=True) # Preenche possíveis valores nulos com string vazia
return dfPor fim, os dados transformados são salvos em um arquivo .csv, que pode ser usado posteriormente em uma ferramenta de BI, em um sistema analítico ou simplesmente para exploração local:
def load(df):
df.to_csv('posts_transformed.csv', index=False)
print("Dados carregados no arquivo posts_transformed.csv")Esse exemplo é simples, mas totalmente funcional. E o mais interessante: ele pode ser expandido facilmente. Basta adicionar mais fontes de dados, aplicar transformações mais sofisticadas (como filtros, agrupamentos e validações) e até carregar os dados diretamente em bancos de dados como PostgreSQL, MongoDB ou serviços de Data Warehouse como o BigQuery ou Redshift, utilizando bibliotecas como SQLAlchemy, pymongo ou pybigquery.
Seja no varejo, na indústria ou nos serviços, uma coisa é certa: quem quer tomar decisões com segurança precisa de dados confiáveis. E o processo ETL é a ponte entre o caos das informações brutas e a clareza dos insights estratégicos.
Ao entender como funciona cada etapa da coleta à transformação e carga, você não só ganha domínio técnico, como também começa a enxergar as possibilidades reais que os dados oferecem para o crescimento de um negócio.
Quer dar os primeiros passos na prática e construir seus próprios pipelines com Python? Acesse a trilha completa de Engenharia de Dados da Asimov Academy e aprenda, do zero ao avançado, como transformar dados em decisões com eficiência, automação e inteligência.

Domine os fundamentos da Engenharia de Dados e construa seu primeiro pipeline com Python, ETL, Airflow e deploy na nuvem.
Comece agora
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:



Comentários
30xp