
Conheça o curso:


Qual a diferença entre dados relacionais e não relacionais? Essa é uma dúvida comum entre aqueles que estão começando a trabalhar com análise de dados, ou mesmo entre profissionais que ainda têm dificuldade para escolher a melhor abordagem para seus projetos.
E essa dúvida tem fundamento. Entender como os dados podem ser relacionais (ou não) é o primeiro passo para fazer boas escolhas técnicas. Afinal, cada projeto tem suas próprias necessidades. Por isso, é importante entender quando usar cada tipo e como aplicá-los na prática.
Neste artigo, você vai aprender o que são dados relacionais e não relacionais, quais são as principais diferenças entre eles e como manipulá-los com Python.
Dados relacionais são aqueles organizados de forma estruturada, em tabelas compostas por linhas e colunas. Se você já usou uma planilha no Excel, provavelmente viu algo parecido.
Cada linha representa um registro (como um cliente ou um pedido), enquanto cada coluna traz informações específicas sobre esse registro, como nome, data da compra ou valor total.
O banco de dados relacional utiliza esses dados e os distribui em diferentes tabelas, conectadas entre si por meio de chaves primárias e estrangeiras.
Essa interligação permite estabelecer relações entre os dados (daí o termo “relacional”), o que facilita a realização de consultas cruzadas, mantém a integridade das informações e evita repetições desnecessárias.
Um ponto importante é que os bancos de dados relacionais exigem um esquema rígido (ou schema). Ou seja, antes de começar a inserir os dados, é necessário definir quais colunas a tabela terá, que tipo de informação cada uma vai aceitar e como essas colunas se conectam a outras tabelas.
Esse nível de organização é importante para garantir a consistência e a confiabilidade das informações ao longo do tempo.
Em um e-commerce, por exemplo, a tabela “Pedidos” pode usar o ID do cliente para vincular automaticamente cada compra à pessoa certa, sem a necessidade de repetir todos os dados do cliente em cada pedido.
Isso economiza espaço e ainda garante que as informações permaneçam consistentes e atualizadas em todo o sistema.

Para consultar e manipular um banco de dados relacional, você precisa usar uma linguagem chamada SQL (Structured Query Language).
Criada ainda na década de 1970, ela continua sendo o padrão do mercado até hoje. Com SQL, você pode inserir dados, aplicar filtros, cruzar informações entre tabelas, atualizar registros e muito mais.
Se quiser saber quais clientes compraram determinado produto na sua loja online, por exemplo, é só fazer uma consulta que relacione as tabelas de clientes, pedidos e produtos.
Essa eficiência ajuda a explicar por que os bancos de dados relacionais (chamados SGBDs), como MySQL, PostgreSQL e SQL Server continuam tão populares.
Sistemas que exigem organização e integridade dos dados, como aplicações bancárias, sistemas hospitalares ou plataformas de e-commerce, utilizam muito esse tipo de estrutura.
Ou seja, é muito provável que você encontre um desses bancos em qualquer sistema que trabalhe com cadastros, vendas, controle de estoque ou relatórios.
Os dados não relacionais, também conhecidos como NoSQL (Not Only SQL), são armazenados de forma mais flexível e menos estruturada.
O cerne dessa abordagem está justamente na sua liberdade estrutural. Um banco de dados não relacional, que utiliza esses tipos de dados, permite que eles sejam armazenados no formato em que chegam, sem a necessidade de seguir um modelo fixo.
Ou seja, você não precisa definir previamente todas as colunas e tipos de dados. Em vez disso, pode ir ajustando a estrutura conforme o projeto evolui.
Outro detalhe importante é que os bancos não relacionais não utilizam a linguagem SQL como padrão. Cada sistema possui sua própria forma de consultar e manipular os dados, o que exige certa adaptação no processo de aprendizagem.
Em compensação, eles podem ser utilizados em aplicações mais complexas, como projetos que envolvem inteligência artificial (IA) e machine learning. Afinal, eles precisam processar grandes volumes de dados semiestruturados para o treinamento de modelos.
Os bancos NoSQL podem adotar diferentes modelos de armazenamento, dependendo do tipo de dado e da aplicação. Conheça cada um deles a seguir:
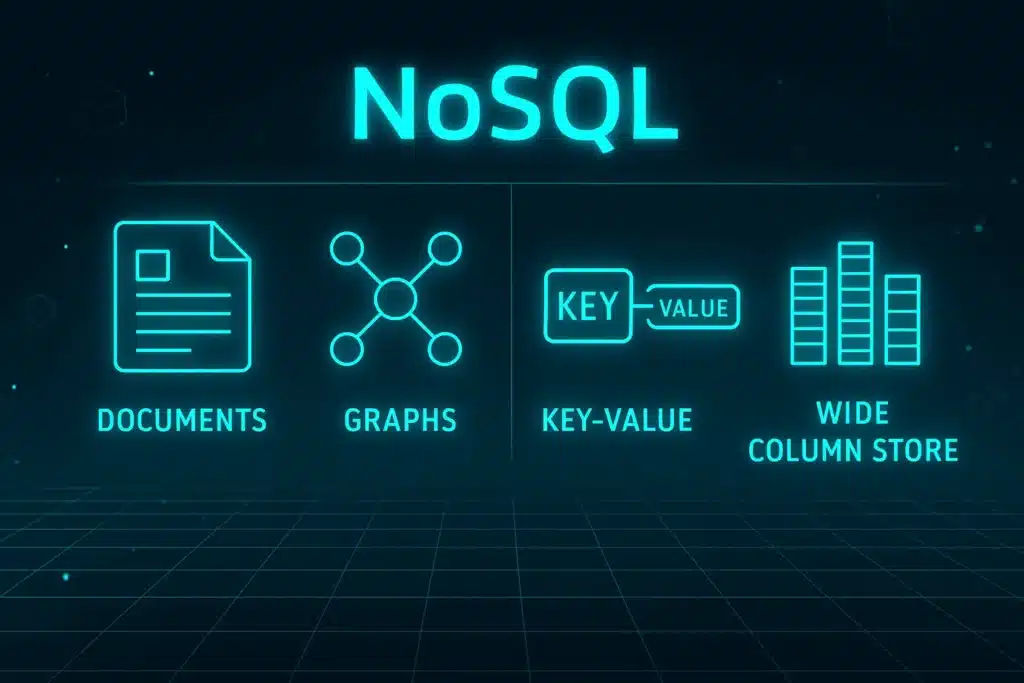
Os dados são armazenados em documentos JSON ou BSON, que funcionam como objetos com campos e valores. Ele é um dos modelos mais versáteis, já que permite que cada documento tenha uma estrutura única.
Por exemplo, no MongoDB, você pode começar registrando um usuário apenas com nome e e-mail. Depois, pode adicionar campos como preferências ou histórico de compras sem necessidade de alterar a estrutura do banco.
Neste modelo, cada dado é armazenado como um par de chave e valor. Ele é simples e extremamente rápido. Por isso, você pode utilizá-lo para aplicações que exigem performance, como cache, sessões de usuário ou contadores em tempo real.
O X (Twitter), por exemplo, usa o Redis para controlar, em tempo real, o número de curtidas, retweets e seguidores que aparecem na tela dos usuários.
Os dados são organizados por colunas em vez de linhas, o que facilita a leitura de dados específicos em grandes volumes. Você pode utilizar este modelo em projetos que precisam de alta escalabilidade e consultas rápidas, mesmo com milhões de registros.
A Netflix, por exemplo, usa o Cassandra para armazenar eventos de usuários em tempo real, como cliques, recomendações, reproduções e comportamento de navegação.
Neste modelo, os dados são armazenados como nós e arestas, representando as relações entre elementos. Bancos como Neo4j e AWS Neptune, por exemplo, são utilizados em sistemas que trabalham com conexões complexas, como redes sociais, mecanismos de recomendação ou mapas de rotas.
Como explicamos, os dados relacionais seguem um esquema fixo e exigem que a estrutura seja determinada previamente. Eles apresentam um formato altamente estruturado e organizado, com linhas e colunas bem definidas em uma tabela.
Já os dados não relacionais oferecem maior flexibilidade e podem assumir diferentes formatos, como documentos JSON, pares chave-valor, colunas independentes ou grafos. Eles não exigem um esquema rígido e se adaptam com facilidade a diversos tipos de informação.
Para visualizar melhor essas diferenças, confira a tabela comparativa abaixo:
| Característica | Dados Relacionais (SQL) | Dados Não Relacionais (NoSQL) |
| Estrutura | Tabelas com linhas e colunas padronizadas | Documentos, chave-valor, colunar ou grafos |
| Linguagem de consulta | SQL (Structured Query Language) | Varia conforme o banco (ex: CQL, APIs específicas, comandos próprios) |
| Flexibilidade | Baixa (requer estrutura definida previamente) | Alta (aceita formatos variados e estrutura dinâmica) |
| Performance | Boa para dados estruturados e transações complexas | Alta em leitura e escrita com grandes volumes e baixa latência |
| Escalabilidade | Vertical (melhorar hardware) ou horizontal com mais complexidade | Horizontal (distribuição fácil entre servidores) |
| Consistência de dados | ACID (consistência forte e transações confiáveis) | BASE (eventualmente consistente, com foco em disponibilidade) |
| Esquema (schema) | Rígido (precisa ser definido antes da inserção de dados) | Flexível (permite adicionar novos campos sem alterar a estrutura) |
| Ideal para | Aplicações com dados estruturados e regras claras (ex: sistemas bancários, ERPs) | Aplicações com dados dinâmicos, não estruturados ou em tempo real (ex: redes sociais, IoT, IA) |
O uso de dados relacionais é recomendado quando o projeto exige organização, estrutura fixa e consistência. Isso porque eles funcionam melhor em contextos em que os dados seguem um formato previsível, com relações bem definidas entre as informações. Por exemplo:
Em contrapartida, os dados não relacionais são a melhor escolha quando você precisa de flexibilidade, escalabilidade horizontal e capacidade de lidar com grandes volumes de dados variados. Isso inclui situações como:
A teoria é importante, mas entender como os dados relacionais e não relacionais são aplicados na prática ajuda (e muito!) na hora de fazer boas escolhas técnicas. Confira a seguir alguns exemplos que mostram como cada tipo de dado pode ser útil em diferentes situações:
Vamos supor que um e-commerce de moda precisa registrar todas as informações de vendas realizadas durante a Black Friday, como produtos, preços, clientes, formas de pagamento e datas.
Esses dados seguem uma estrutura fixa e previsível, com campos padronizados e regras bem definidas entre as tabelas. Por exemplo, um pedido pertence a um cliente, um produto pertence a uma categoria e assim por diante.
Nesse caso, o ideal é organizar tudo isso em um banco de dados relacional, como o PostgreSQL. Ele permite garantir a integridade dos dados e executar consultas complexas, como:
SELECT cliente_id, SUM(valor_total)
FROM pedidos
WHERE data >= '2025-01-01'
GROUP BY cliente_id;
Se o mesmo e-commerce decidir armazenar dados de perfis de usuários, onde cada cliente pode ter informações diferentes, como redes sociais, preferências de produto e listas de desejos, os dados devem ser diferentes. Afinal, eles mudam de pessoa para pessoa.
Nesse caso, o ideal é trabalhar com um banco de dados não-relacional, como o MongoDB. Ele permite armazenar diferentes combinações de dados sem a necessidade de alterar o esquema toda vez que um novo campo for adicionado.
Veja este exemplo de documento no MongoDB:
{
"nome": "Alice",
"email": "[email protected]",
"preferencias": ["moda", "livros"],
"enderecos": [
{"cidade": "São Paulo", "cep": "01000-000"},
{"cidade": "Campinas", "cep": "13000-000"}
]
}
Quando um usuário acessa várias vezes a mesma página de produto em uma loja online, o sistema normalmente consulta o banco de dados relacional a cada visita.
No entanto, esse processo pode ser muito mais rápido se as informações forem buscadas no Redis, que armazena os dados na memória e garante respostas quase instantâneas.
Muitos sistemas modernos combinam bancos relacionais e não relacionais para aproveitar o melhor de cada modelo. É comum, por exemplo:

Python é uma das melhores linguagens para quem quer começar a trabalhar com dados. Além de ser simples e versátil, ele se conecta facilmente a diferentes tipos de bancos de dados.
Essa linguagem oferece suporte completo tanto para bancos relacionais, como PostgreSQL, MySQL e SQLite, quanto para bancos não relacionais, como MongoDB, Redis e Cassandra.
No caso dos bancos relacionais, bibliotecas como SQLAlchemy e psycopg2 (especializado em PostgreSQL) permitem executar consultas SQL, gerenciar transações e até construir aplicações inteiras com base em dados estruturados.
Já para os bancos NoSQL, Python conta com pacotes como pymongo, que facilita a comunicação com documentos no MongoDB, e redis-py, ideal para interações rápidas com estruturas do tipo chave-valor.
Dominando essas ferramentas dentro do ecossistema Python, você consegue transitar com segurança entre os dois mundos de dados.
Assim, fica mais fácil construir soluções para diferentes cenários de uso, como análise de dados, automação ou aplicações de IA. Python se adapta a todos eles com facilidade.
Se você está começando na área de dados e quer aprender, na prática, como trabalhar com diferentes formatos de informação, a melhor estratégia é colocar a mão na massa!
Para te ajudar nessa jornada de aprendizado, a Asimov Academy oferece o curso gratuito Python para Dados: do zero à análise completa.
Ele é ideal para você, que está começando na área de dados, quer aprender como usar Python com bancos relacionais e começar a explorar aplicações com dados em diferentes formatos.
Acesse o curso gratuito e comece hoje mesmo a aprender com quem entende do assunto!

Realize análises poderosas que vão muito além do que ferramentas como Excel podem oferecer.
Comece agora
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:






Comentários
30xpMuito bom o artigo, para quem tem dúvidas, resolve bastante.
Fala, Rômulo!
Muito bom te ver por aqui. Ficamos felizes que você tenha curtido o conteúdo!
Sucesso pra você! O/