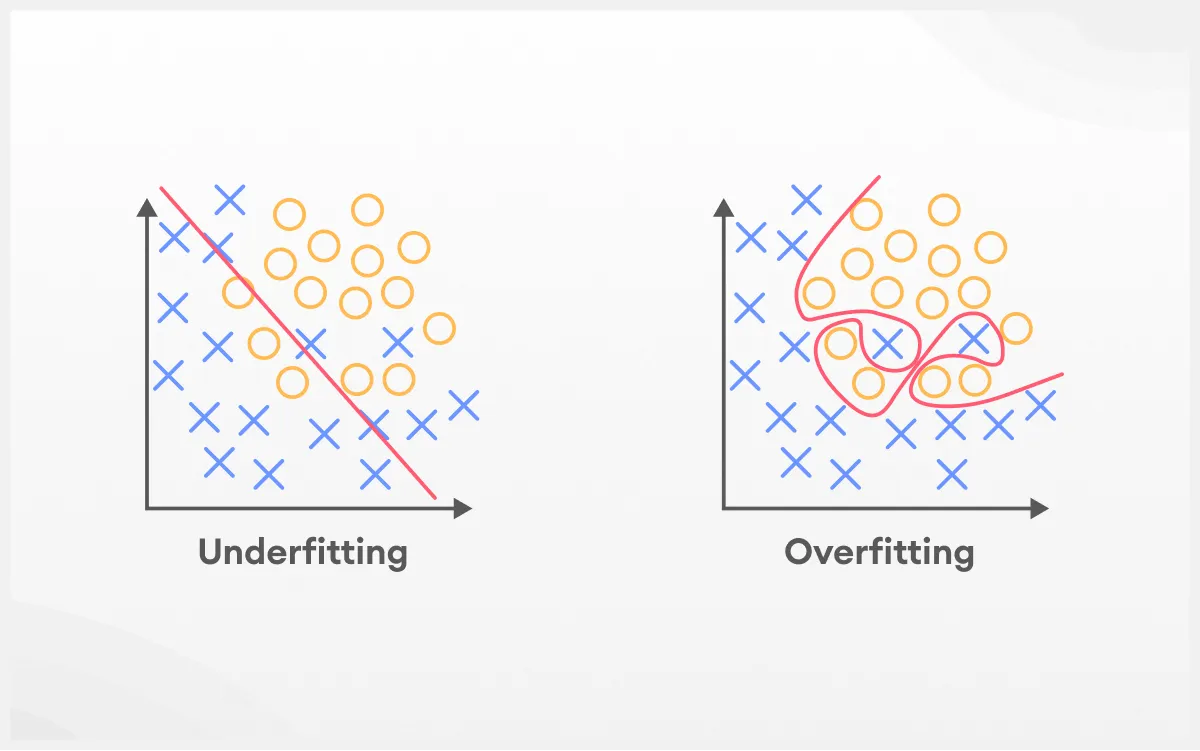

O que é overfitting?
Overfitting, ou sobreajuste, é um fenômeno em machine learning e estatística onde um modelo se ajusta excessivamente aos dados de treinamento, capturando não apenas os padrões reais, mas também o ruído e as peculiaridades específicas desses dados. Como resultado, o modelo apresenta alta precisão nos dados usados para treinamento, mas tem desempenho ruim ao ser aplicado a novos dados, pois não consegue generalizar adequadamente.
Sabe quando alguém decora as respostas da prova em vez de entender a matéria? Funciona até certo ponto, mas é só a pergunta vir de um jeito diferente que tudo desanda.
Overfitting acontece quando um modelo “aprende demais” os dados de treinamento. Em vez de captar os padrões que realmente importam, ele também memoriza ruídos, exceções e detalhes específicos que não fazem sentido fora daquele conjunto. Com isso, o desempenho até parece ótimo durante os testes internos, mas despenca quando o modelo é colocado para lidar com dados novos.
Esse comportamento geralmente aparece quando:
- O conjunto de dados de treinamento é pequeno ou mal distribuído;
- O modelo tem complexidade demais, com muitos parâmetros, e acaba “decorando” em vez de aprender;
- O treinamento é longo demais e o modelo se ajusta excessivamente aos dados disponíveis;
- Há muito ruído ou informações irrelevantes nos dados e o modelo não consegue ignorar.
Um exemplo simples: imagine um modelo criado para identificar cães em fotos. Se ele for treinado com imagens tiradas quase sempre em parques, pode acabar associando grama à presença de um cachorro. Aí, ao ver um cãozinho dentro de casa, ele pode simplesmente errar, afinal, ele aprendeu a ver grama, não a reconhecer um cachorro de verdade.
Para evitar esse tipo de problema, é essencial usar algumas estratégias como:
- Dividir bem os dados em conjuntos de treino, validação e teste;
- Aplicar validação cruzada, que ajuda a entender como o modelo se comporta com diferentes amostras;
- Usar regularização, uma técnica que impede que o modelo fique complexo demais;
- Reduzir a complexidade do modelo, treinar por menos tempo ou aumentar a variedade dos dados.
No fim das contas, o que se busca em qualquer modelo de machine learning é a capacidade de generalizar, ou seja, funcionar bem mesmo com dados que nunca viu antes. E é aí que mora o perigo do overfitting: ele pode até parecer inteligente, mas só sabe repetir o que já viu. E isso, no mundo real, raramente é suficiente.
O que é underfitting?
Underfitting é um problema em machine learning que ocorre quando um modelo é simples demais para capturar a complexidade dos dados. Isso faz com que o modelo não aprenda adequadamente os padrões subjacentes, resultando em desempenho ruim tanto nos dados de treinamento quanto nos dados novos, ou seja, ele não consegue generalizar nem mesmo para os dados que já viu.
Já tentou explicar um tema complexo com uma única frase e viu que a pessoa não entendeu nada? É mais ou menos isso que acontece com underfitting em machine learning. Quando um modelo é simples demais, ele não consegue capturar as relações e padrões escondidos nos dados e acaba falhando tanto no treino quanto na hora de fazer previsões novas.
Esse cenário costuma se manifestar por:
- Erros altos em todo lugar: o modelo “não aprendeu” bem nem no conjunto de treinamento, nem no de teste;
- Visão rasa das variáveis: não consegue enxergar ligações importantes entre os dados;
- Baixa capacidade preditiva: parece alheio ao que realmente está ocorrendo nos dados.
É como tentar montar um quebra‑cabeça gigante usando apenas três peças. Você nunca vai entender a imagem completa.
Pense num exemplo prático: digamos que você queira estimar o valor de imóveis e usa um modelo totalmente linear. Se o mercado tiver efeitos não lineares como localização premium ou reformas recentes o modelo vai ignorar tudo isso e errar feio tanto nos dados que já viu quanto nos novos.
Prevendo preços de apartamentos com Machine Learning
Exemplos de overfitting e underfitting (códigos práticos)
Quando treinamos um modelo de machine learning, um dos maiores desafios é encontrar o equilíbrio entre simplicidade e complexidade. Se o modelo for simples demais, ele não aprenderá o suficiente sobre os dados, isso é o underfitting.
Se for complexo demais, ele aprenderá até o que não precisa, isso é o overfitting.
Mas como isso se manifesta na prática? Vamos explorar com exemplos visuais usando um conjunto de dados clássico: o make_moons, da biblioteca scikit-learn.
Scikit-learn: o que é, por que usar e como instalar
1. Criando um dataset simples
Usaremos o make_moons, do scikit-learn, que gera dois grupos de pontos em formato de meia-lua — um padrão que não é linear, o que ajuda a revelar claramente os limites dos modelos simples e complexos.
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# Gerar dados
X, y = make_moons(n_samples=300, noise=0.3, random_state=42)
# Visualizar
plt.figure(figsize=(6, 4))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1, edgecolor='k')
plt.title("Dataset make_moons")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()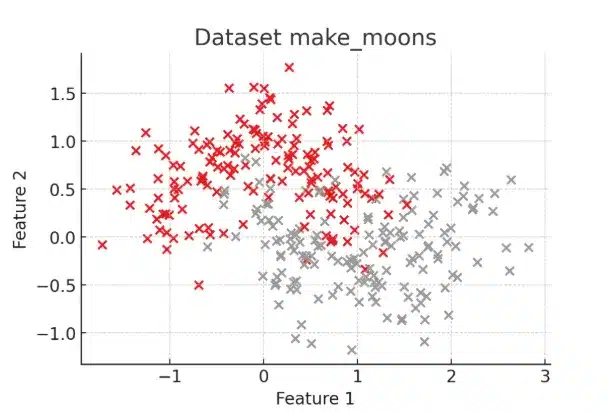
2. Treinando um modelo simples: Underfitting
Começamos com a regressão logística, um modelo linear. Esse tipo de modelo não consegue capturar bem os padrões não lineares do make_moons, o que resulta em baixo desempenho mesmo no conjunto de treino.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Separar dados em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Treinar modelo simples
model_simple = LogisticRegression()
model_simple.fit(X_train, y_train)
# Avaliação
train_acc = accuracy_score(y_train, model_simple.predict(X_train))
test_acc = accuracy_score(y_test, model_simple.predict(X_test))
print(f"Underfitting - Acurácia treino: {train_acc:.2f} | teste: {test_acc:.2f}")3. Treinando um modelo muito complexo: Overfitting
Agora, treinamos um modelo extremamente complexo: uma Random Forest com muitas árvores e profundidade ilimitada. Esse modelo tende a aprender até os ruídos dos dados de treino, o que prejudica a generalização.
from sklearn.ensemble import RandomForestClassifier
model_complex = RandomForestClassifier(n_estimators=500, max_depth=None, random_state=42)
model_complex.fit(X_train, y_train)
train_acc = accuracy_score(y_train, model_complex.predict(X_train))
test_acc = accuracy_score(y_test, model_complex.predict(X_test))
print(f"Overfitting - Acurácia treino: {train_acc:.2f} | teste: {test_acc:.2f}")Visualizando os resultados
Agora, vamos criar uma visualização comparando as fronteiras de decisão dos dois modelos:
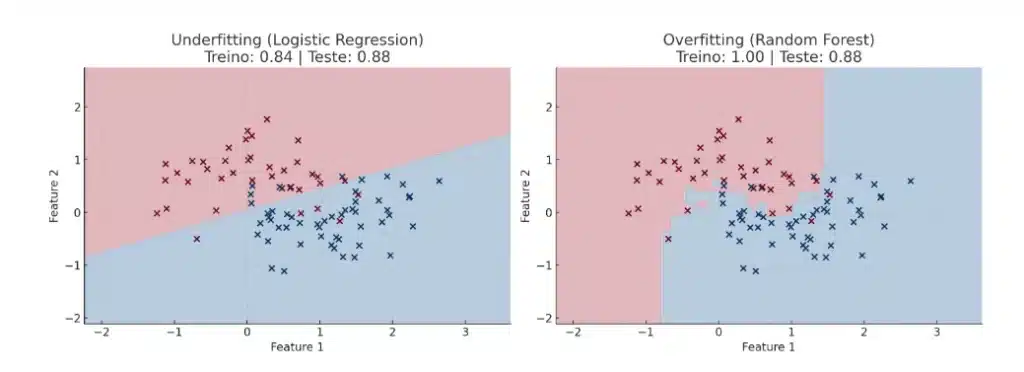
Principais diferenças entre overfitting e underfitting
Em machine learning, conseguimos medir a qualidade de um modelo observando seu desempenho em dois conjuntos de dados distintos: o treinamento (onde o modelo aprende) e o teste (onde avaliamos sua capacidade de generalizar).
O objetivo é sempre encontrar o “ponto ideal” entre esses extremos, garantindo baixo erro de treino e bom desempenho em dados não vistos.
Tabela comparativa
| Aspecto | Overfitting | Underfitting |
| Definição | Captura ruídos e particularidades do conjunto de treino, dificultando a generalização para novos dados. | Não aprende padrões relevantes; o modelo é simples demais ou mal ajustado, falhando até no treino. |
| Desempenho no treino | Excelente (erro muito baixo ou quase zero). | Insatisfatório (erro alto). |
| Desempenho no teste | Ruim (erro alto, pois o modelo não generaliza). | Ruim (erro alto, pois falha em capturar padrões). |
| Causa mais comum | • Modelo muito complexo (muitos parâmetros) • Poucos dados ou dados ruidosos• Treino excessivo | • Modelo muito simples (poucos parâmetros) • Treinamento insuficiente• Dados escassos |
| Exemplo prático | Árvore de decisão profunda que memorizou outliers; falha em novos casos. | Regressão linear tentando ajustar relação altamente não linear. |
| Sinais em curvas de aprendizado | Treino: erro decresce até valer quase zeroValidação: erro cresce após certo ponto de treino | Treino e validação: erro permanece alto e quase paralelo. |
| Impacto nos limites de decisão | Fronteiras complexas, “onduladas” e sensíveis a ruídos. | Fronteiras muito simples, incapazes de separar classes. |
| Bias–Variance | Baixo bias, alta variância (modelo instável). | Alto bias, baixa variância (modelo muito rígido). |
| Diagnóstico | • Grande gap entre erro de treino e de teste • Flutuações fortes nos scores de cross‑validation | • Erro alto em todos os conjuntos • Pontos de aprendizado estagnados no início do treinamento |
| Estratégias de mitigação | • Regularização (L1, L2) ou dropout • Poda de árvores • Aumentar dados de treino (data augmentation) | • Aumentar a complexidade do modelo (mais camadas, nós, parâmetros) • Treinar por mais épocas • Extrair novas features |
Como detectar overfitting e underfitting na prática?
Para detectar overfitting e underfitting na prática, você pode seguir estes passos fundamentais:
1. Divisão dos dados em treino e teste
Separe seu conjunto de dados em conjunto de treinamento e conjunto de teste (por exemplo, 70% treino e 30% teste). O modelo é treinado no conjunto de treino e avaliado no conjunto de testes para verificar sua capacidade de generalização.
2. Comparação de métricas nos conjuntos de treino e teste
- Overfitting ocorre quando o modelo tem desempenho muito bom nos dados de treino, mas ruim nos dados de teste, indicando que ele decorou o conjunto de treino e não generaliza bem;
- Underfitting ocorre quando o modelo tem desempenho ruim tanto no treino quanto no teste, mostrando que ele é simples demais para capturar os padrões dos dados;
- Métricas comuns para avaliação incluem acurácia, erro quadrático médio, F1-score, etc., dependendo do problema.
3. Uso de validação cruzada (cross-validation)
A validação cruzada consiste em dividir os dados em vários subconjuntos (folds), treinando e testando o modelo em diferentes combinações para obter uma avaliação mais robusta e reduzir o risco de overfitting devido à escolha específica da partição. Isso permite monitorar a variabilidade do desempenho e ajuda a ajustar hiperparâmetros sem vazar informação do conjunto de teste.
4. Exemplo prático com scikit-learn
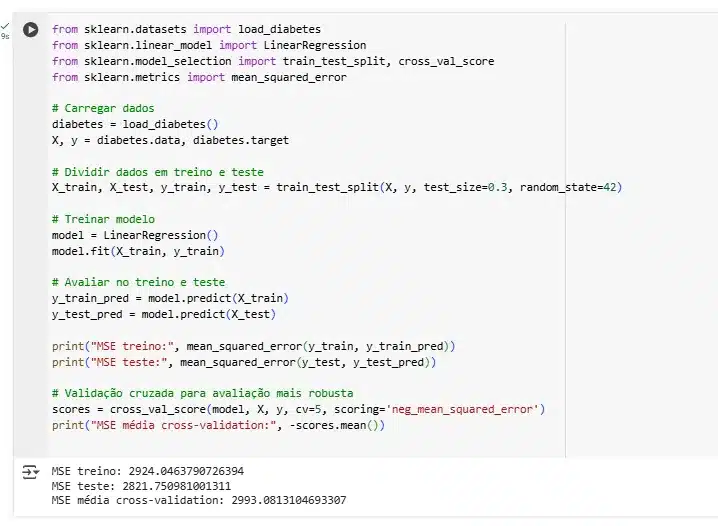
Análise dos resultados
- Se MSE Treino ≪ MSE Validação → ajuste demais (overfitting);
- Se MSE Treino ≈ MSE Validação e ambos altos → ajuste de menos (underfitting);
Dicas adicionais para evitar overfitting
- Use regularização, métodos de ensemble (bagging, boosting);
- Monitore curvas de aprendizado (perda no treino e validação);
- Utilize parada antecipada (early stopping) em modelos iterativos.
Essas práticas permitem identificar e mitigar overfitting e underfitting, garantindo que seu modelo tenha boa capacidade de generalização para dados novos.
Como evitar o overfitting e o underfitting?
Evitando overfitting:
- Regularização (L1, L2)
Ao incluir uma penalidade sobre o tamanho dos parâmetros do modelo, a regularização impede que os coeficientes cresçam demais.
- L1 (Lasso): tende a zerar coeficientes irrelevantes, promovendo seleção automática de variáveis;
- L2 (Ridge): distribui penalidades de forma mais suave, reduzindo todos os coeficientes sem eliminá‑los por completo.
- L1 (Lasso): tende a zerar coeficientes irrelevantes, promovendo seleção automática de variáveis;
- Reduzir a complexidade do modelo
- Em árvores de decisão, limite a profundidade máxima ou exija um número mínimo de amostras por nó;
- Em redes neurais, diminua o número de camadas ou de neurônios por camada.
- Em árvores de decisão, limite a profundidade máxima ou exija um número mínimo de amostras por nó;
- Aumentar o volume de dados
Quanto mais exemplos o modelo “vê”, menor a chance de decorar ruídos.
- Coleta adicional: buscar bases de dados suplementares ou gerar dados sintéticos;
- Data augmentation: em imagens, aplique rotações, espelhamentos, cortes e variações de brilho para criar variações realistas.
- Coleta adicional: buscar bases de dados suplementares ou gerar dados sintéticos;
- Dropout (apenas em redes neurais)
Desligar, a cada iteração, uma fração dos neurônios força o modelo a não depender excessivamente de padrões específicos, melhorando a generalização. - Early stopping (parada antecipada)
Monitore a métrica no conjunto de validação durante o treinamento. Pare assim que o erro de validação começar a subir, evitando que o modelo aprenda o “ruído”. - Validação cruzada
Realize k‑fold cross‑validation para testar o modelo em diferentes particionamentos de treino e validação. Isso garante que sua configuração de hiperparâmetros não esteja “viciada” em uma única divisão dos dados.
Como evitar underfitting
- Escolher modelos mais complexos
Se o seu modelo é incapaz de capturar padrões, pense em:
- Árvore de decisão com maior profundidade;
- Redes neurais mais profundas ou com mais neurônios;
- Modelos baseados em ensemble (Boosting, Random Forest) que combinam múltiplas estimativas.
- Árvore de decisão com maior profundidade;
- Adicionar features relevantes
Invista em feature engineering: crie variáveis derivadas que expressam melhor a relação entre entrada e saída (por exemplo, interações, polinômios, codificações categóricas mais ricas). - Ajustar hiperparâmetros
Explore cuidadosamente parâmetros como:
- Taxa de aprendizado (learning rate) em algoritmos iterativos;
- Critério de divisão e profundidade máxima em árvores;
- Número de estimadores em métodos de ensemble;
- Regularização (ajustar α em Ridge/Lasso ou taxa de dropout).
- Taxa de aprendizado (learning rate) em algoritmos iterativos;
- Treinar por mais épocas
Para redes neurais, aumente o número de ciclos de atualização (epochs) pode permitir que o modelo extraia padrões mais profundos do conjunto de treino, desde que combinado com early stopping para não chegar ao overfitting. - Coletar ou sintetizar mais dados
Mesmo que o risco principal seja o overfitting, ter mais exemplos pode ajudar também a underfitting, pois disponibiliza mais variações dos padrões reais.
Como aprender machine learning e criar modelos robustos sem overfitting ou underfitting
Gostou de aprender como evitar o overfitting e o underfitting nos seus modelos? Então aproveite para levar esse conhecimento ainda mais longe.
Conheça a Trilha Data Science & Machine Learning da Asimov Academy, ideal para quem quer dominar de verdade as técnicas mais avançadas da área. Você vai aprender a analisar dados complexos, treinar modelos robustos de machine learning, aplicar conceitos de matemática e estatística com confiança e criar predições com Python que fazem a diferença em projetos reais.
São 67 horas de conteúdo, sendo 29 horas focadas em projetos práticos. A trilha é avançada, mas acessível, com uma didática clara e envolvente. Com nota 4.8 entre os participantes e um certificado ao final, ela é perfeita para quem quer se destacar em um dos mercados mais promissores da atualidade.

Trilha Data Science e Machine Learning
Explore dados, desenvolva modelos preditivos e extraia insights valiosos para impulsionar a tomada de decisões.
Comece agoraVocê também pode gostar:







Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp