
Leia também:


Um modelo de IA é um programa treinado para reconhecer padrões ou tomar decisões de forma autônoma, sem a necessidade de intervenção humana direta.
Ele é criado quando se aplica um algoritmo a um conjunto de dados, permitindo que aprenda com exemplos e generalize esse conhecimento para novas situações. Na prática, ele funciona de maneira semelhante ao processo de aprendizado humano.
Por exemplo, você já viu uma criança aprendendo o nome dos animais? Primeiro, pais ou professores mostram várias imagens de gatos, cachorros, pássaros e peixes, nomeando cada um deles.
Com o tempo, mesmo que a criança veja um gato ou cachorro que nunca viu antes, ela será capaz de reconhecê-lo por conta própria.
Os modelos de IA seguem essa mesma lógica, mas usam grandes volumes de dados e têm a capacidade de identificar padrões sutis que, muitas vezes, passariam despercebidos.
Modelo e algoritmo não são a mesma coisa. Embora os termos sejam frequentemente usados como sinônimos, eles têm significados distintos.
Algoritmo é o conjunto de regras matemáticas ou instruções que definem como o aprendizado será realizado. Já o modelo é o resultado final: o programa treinado com dados, pronto para ser aplicado em diferentes contextos.
Pense no algoritmo como uma receita de bolo, e o modelo como o bolo pronto. Isso porque ele surge da aplicação do algoritmo a um conjunto de dados. E é por meio desse processo, conhecido como treinamento, que o modelo se torna capaz de fazer previsões e tomar decisões com base em novas informações.

De forma geral, os modelos de IA operam extraindo informações de dados brutos, aplicando técnicas matemáticas e estatísticas para identificar padrões e, a partir disso, executando tarefas com alto nível de autonomia.
Para isso, analisam grandes volumes de dados, reconhecem padrões ocultos e utilizam essas informações para tomar decisões ou realizar previsões de forma independente. Esse processo ocorre em três etapas principais: modelagem, treinamento e inferência.
Entenda a seguir o que acontece em cada uma dessas fases:
A modelagem é a fase em que se define como o modelo vai aprender. É nesse momento que se desenvolve uma estrutura capaz de imitar a lógica de tomada de decisão humana. Para isso, é preciso selecionar algoritmos ou camadas de algoritmos que funcionarão como a “arquitetura” do modelo.
Na prática, essa etapa equivale a projetar um cérebro artificial que simula a expertise humana, mas que só poderá ser utilizado após passar pelo processo de treinamento.
O treinamento é o momento em que o modelo realmente aprende. Ele é alimentado com grandes quantidades de dados em ciclos contínuos de teste e validação. Durante esse processo, o desempenho do modelo é avaliado constantemente, e ajustes são realizados até que ele atinja o nível de precisão desejado.
À medida que os modelos se tornam mais complexos, como os grandes modelos de linguagem (LLMs) com bilhões de parâmetros, a quantidade de dados necessária para o treinamento também cresce exponencialmente.
Vale lembrar que, embora o uso de dados do mundo real seja ideal para garantir que os modelos reflitam a realidade que precisam analisar, nem sempre isso é possível por questões de privacidade, viés e custo.
Nesses casos, a alternativa é o uso de dados sintéticos (dados artificialmente gerados com base em exemplos reais), que mantém a qualidade do treinamento sem expor informações sensíveis.
Além disso, durante essa etapa, também é necessário lidar com desafios como viés nos dados, que pode levar a decisões injustas ou discriminatórias, e também com problemas como overfitting e underfitting.
É justamente para evitar esses problemas que os cientistas de dados aplicam técnicas de validação, regularização e ajuste fino que tornam o modelo mais robusto, justo e confiável.

Na fase de inferência, o modelo treinado entra em ação. Ele começa a operar em cenários reais, processando novos dados e utilizando o conhecimento adquirido para tirar conclusões, prever resultados ou realizar ações, como recomendar produtos, identificar fraudes ou prever a demanda de um estoque.
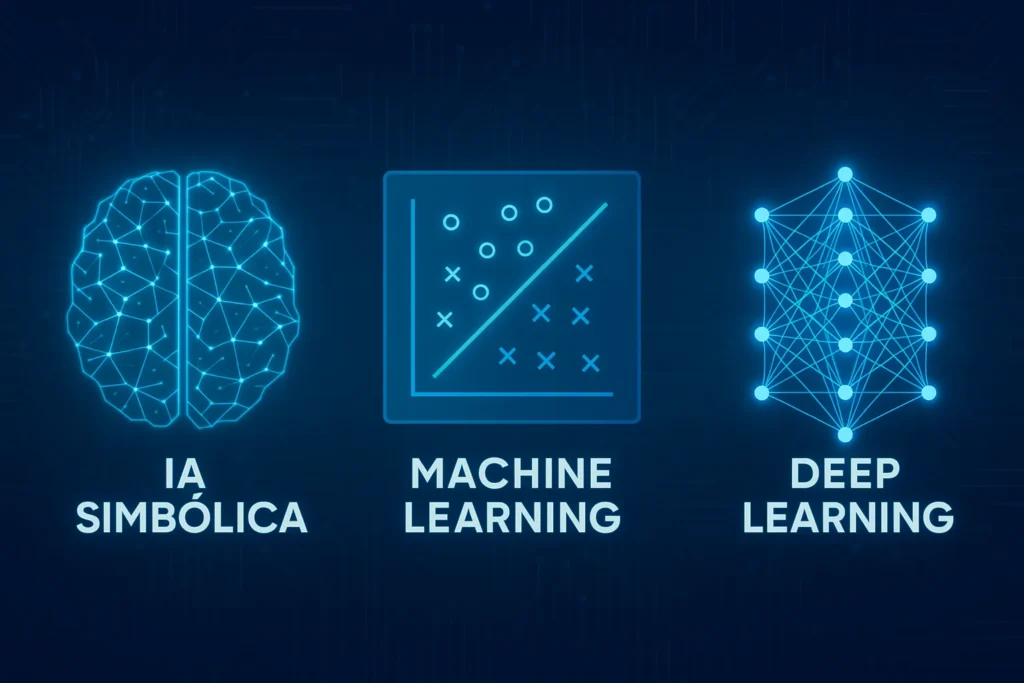
Os modelos de inteligência artificial podem ser classificados em três grandes grupos de acordo com sua lógica de funcionamento e nível de complexidade.
Entenda as diferenças entre eles a seguir.
A IA simbólica, também chamada de IA baseada em regras, foi uma das primeiras abordagens desenvolvidas, mas é utilizada até hoje em diversos sistemas. Nesse caso, o conhecimento é representado por símbolos e regras lógicas, e as decisões são tomadas com base em cadeias de inferência.
Na prática, ela funciona como programar um sistema para pensar seguindo uma lógica formal, no estilo “se isso acontecer, então faça aquilo” (if–then–else).
Por isso, essa IA não aprende com dados, mas sim com regras definidas por especialistas humanos. O resultado é um modelo altamente previsível e fácil de interpretar.
Esse modelo é indicado para aplicações em que é fundamental entender exatamente como o sistema chegou a uma conclusão, como em robôs industriais que seguem instruções fixas ou em sistemas de diagnóstico médico baseados em sintomas.
Por exemplo, se um paciente apresenta febre, tosse e dor no peito, o sistema pode sugerir pneumonia com base em uma regra previamente estabelecida.

O machine learning (ML) revolucionou a forma como os modelos de IA são desenvolvidos. Diferentemente da IA simbólica, que depende de regras programadas manualmente, os modelos de ML são treinados com dados.
Ao analisar grandes volumes de informações, esses modelos ajustam seus próprios parâmetros internos para identificar padrões, fazer previsões e tomar decisões com base em novas entradas. Esse processo de aprendizado pode ocorrer de três formas principais:
Nesse tipo de aprendizado, o modelo é treinado com dados rotulados, ou seja, conjuntos de entrada que já vêm acompanhados dos resultados esperados. Durante o treinamento, o algoritmo analisa esses pares de entrada e saída, buscando aprender a relação entre eles.
Em seguida, ele ajusta seus parâmetros com base nos erros cometidos, até conseguir generalizar com precisão para novos dados. Um modelo supervisionado pode ser treinado, por exemplo, para prever o tempo de viagem entre dois pontos com base em variáveis como clima, horário e tráfego.
Para isso, ele precisa de um conjunto de dados em que a duração de cada trajeto já seja conhecida. Com o tempo, o modelo aprende que dias chuvosos aumentam o tempo de deslocamento, horários de pico causam atrasos e assim por diante.
Modelos construídos com esse tipo de aprendizado podem ser utilizados para realizar tarefas como classificação de e-mails como spam, detecção de fraudes bancárias e previsão de demanda.
Aqui, o modelo recebe dados brutos, sem nenhuma instrução explícita sobre o que deve aprender, e precisa identificar padrões, estruturas ou agrupamentos por conta própria.
Por isso, modelos construídos com esse tipo de aprendizado podem ser usados em sistemas de análise exploratória de dados, segmentação de clientes, detecção de anomalias e sistemas de recomendação, como os usados pela Netflix e pela Amazon, por exemplo.
No entanto, os resultados precisam ser validados por humanos, já que o modelo pode encontrar padrões que não fazem sentido prático ou comercial para a finalidade do sistema.
Esse tipo de modelo aprende por tentativa e erro, em um ambiente interativo. A cada ação executada, ele recebe uma recompensa (ou penalidade), ajustando seu comportamento com o objetivo de maximizar os ganhos ao longo do tempo.
É como treinar um cachorro: ao obedecer um comando, ele ganha um petisco; ao errar, não recebe nada. Com o tempo, ele aprende o que fazer para ser recompensado.
Da mesma forma, um modelo por reforço pode aprender a jogar xadrez, dirigir um carro autônomo ou determinar o melhor momento para exibir um anúncio nas redes sociais, por exemplo.
O deep learning é um subconjunto mais avançado do aprendizado de máquina, derivado principalmente do aprendizado não supervisionado.
Na prática, ele representa um “ramo” mais sofisticado do machine learning, já que utiliza redes neurais artificiais com múltiplas camadas para modelar padrões complexos e executar tarefas altamente especializadas.
Graças a essa arquitetura, o deep learning é capaz de lidar com grandes volumes de dados não estruturados, como imagens, áudios, vídeos e textos, de forma autônoma e com alta precisão. É essa tecnologia que possibilita que sistemas consigam identificar rostos, traduzir idiomas, gerar imagens realistas e responder a comandos de voz.
Por isso, o deep learning está por trás das aplicações mais avançadas da inteligência artificial, como modelos generativos, visão computacional, reconhecimento de fala e processamento de linguagem natural (NLP). O próprio ChatGPT, por exemplo, é baseado em deep learning.
Os modelos de IA baseados em machine learning também podem ser classificados em diferentes tipos, dependendo das características analisadas. Confira abaixo os principais.
Os modelos de inteligência artificial supervisionada são categorizados conforme a natureza da tarefa que realizam. Os grupos mais conhecidos são os modelos de classificação e os modelos de regressão.
Os modelos de regressão são usados quando o objetivo é prever um valor numérico contínuo com base em variáveis de entrada. Na prática, eles respondem a perguntas como: “quanto?”, “qual valor?”, “qual será a temperatura amanhã?” ou “qual será o preço de um produto daqui a uma semana?”.
Esses modelos identificam a relação matemática entre variáveis independentes (x) e uma variável dependente (y). Por exemplo, é possível prever o valor de uma casa com base em fatores como localização, metragem, número de quartos e ano de construção.
Para isso, utilizam algoritmos como regressão linear, regressão polinomial, SVR (Support Vector Regression) e até alguns modelos generativos. São amplamente aplicados em áreas como previsão do tempo, precificação dinâmica, gestão de riscos e projeção de demanda.
Já os modelos de classificação são usados quando a tarefa envolve atribuir uma categoria ou rótulo a uma entrada. Em vez de prever um valor contínuo, eles classificam os dados em valores discretos, como “sim” ou “não”, “positivo” ou “negativo”, ou ainda categorias como “gato”, “cachorro” e “pássaro”.
Esses modelos são comuns em aplicações como filtros de spam, reconhecimento de imagens, diagnóstico médico, sistemas de recomendação e análise de sentimentos.
Entre os algoritmos mais utilizados para esse tipo de tarefa estão Naïve Bayes, análise discriminante linear (LDA) e regressão logística. Na prática, os modelos de regressão são utilizados para prever valores contínuos, enquanto os de classificação têm como foco atribuir categorias.
Na prática, os modelos de regressão são ideais para prever valores contínuos, enquanto os de classificação são usados para atribuir categorias.
Confira as principais diferenças entre eles na tabela abaixo:
| Aspecto | Modelos de Regressão | Modelos de Classificação |
|---|---|---|
| Tipo de saída | Valor contínuo (ex: preço, idade, temperatura) | Categoria ou rótulo discreto (ex: sim/não, tipo A/B/C) |
| Objetivo | Prever uma quantidade ou valor numérico | Atribuir uma classe ou categoria à entrada |
| Exemplos de tarefas | Previsão de preços, duração de trajetos, consumo de energia | Detecção de spam, diagnóstico médico, reconhecimento de imagem |
| Tipo de problema resolvido | Relação matemática entre variáveis independentes e dependentes | Identificação de padrões para classificação entre grupos |
| Formato do rótulo nos dados | Números reais (ex: 245.78, 73,5) | Classes pré-definidas (ex: “spam” ou “não spam”) |

Os modelos de ML também podem ser classificados de acordo com a forma como eles aprendem e representam os dados. Nesse caso, os grupos mais importantes são conhecidos como modelos generativos e os modelos discriminativos.
Os modelos generativos têm como objetivo modelar a distribuição conjunta dos dados (P(x, y)), ou seja, a probabilidade de uma entrada (x) e uma saída (y) ocorrerem simultaneamente. Na prática, eles aprendem como os dados se comportam como um todo, identificando padrões, correlações e estruturas dentro do conjunto analisado.
Além de classificar ou prever, os modelos generativos têm a capacidade de criar novos dados semelhantes aos dados de treinamento. Por isso, são a base de tecnologias como geração de texto, síntese de imagens, tradução de idiomas e composição musical.
Por exemplo, um modelo generativo de linguagem pode aprender que expressões como “era uma vez” costumam aparecer no início de histórias e usar esse conhecimento para compor narrativas completas.
Vale lembrar que esse tipo de modelo é bastante utilizado em aprendizado não supervisionado, mas também pode ser aplicado em contextos supervisionados.
Já os modelos discriminativos focam em diferenciar os dados. Eles modelam a probabilidade condicional P(y|x), ou seja, a chance de uma entrada x pertencer a uma classe y. Seu principal objetivo é definir limites claros de decisão entre categorias, priorizando a precisão nas tarefas de classificação ou predição.
Geralmente, esses modelos são utilizados em aprendizado supervisionado, quando o objetivo é atribuir rótulos a exemplos com base em características específicas.
Como não precisam representar toda a estrutura dos dados, os modelos discriminativos geralmente são mais rápidos e demandam menos recursos computacionais. Além disso, eles são mais eficientes em tarefas como análise de sentimentos, detecção de fraudes, reconhecimento de voz e visão computacional.
Entenda abaixo as principais diferenças entre esses dois modelos:
| Aspecto | Modelos Generativos | Modelos Discriminativos |
|---|---|---|
| Probabilidade modelada | P(x, y): probabilidade conjunta da entrada e saída | P(y |
| Objetivo principal | Aprender como os dados são gerados e criar novos exemplos realistas | Aprender a separar ou classificar os dados em categorias |
| Capacidade de geração de dados | Sim, pode gerar novos dados a partir do que aprendeu | Não, apenas classifica ou prevê com base em dados existentes |
| Exemplo prático | ChatGPT gerando uma resposta em linguagem natural | Modelo classificando um e-mail como spam ou não spam |
| Capacidade explicativa | Modela correlações e estrutura dos dados | Foca apenas nos limites de decisão |
Os modelos de base, também conhecidos como foundation models ou modelos fundamentais, são modelos de deep learning pré-treinados em grandes volumes de dados para aprender padrões e representações amplas.
Eles funcionam como uma “base” versátil, que pode ser ajustada e adaptada para tarefas específicas. Isso reduz o tempo, o custo e o uso de recursos computacionais necessários para o treinamento, em comparação com o desenvolvimento de um modelo do zero.
Os foundation models também se destacam pela capacidade de generalizar, ou seja, realizar bem tarefas que nunca encontraram durante o treinamento.
Eles ainda podem apresentar comportamentos emergentes (habilidades inesperadas), como gerar código ou traduzir idiomas, mesmo sem terem sido treinados diretamente para essas funções.
Muitos desses modelos também são multimodais, ou seja, conseguem entender e integrar diferentes tipos de dados simultaneamente, como texto, imagem, vídeo e som.
Isso permite aplicações como gerar legendas a partir de imagens, descrever o conteúdo de vídeos ou responder perguntas com base em informações visuais e textuais combinadas.
Você certamente já interagiu com esse tipo de modelo por aí. Ele está por trás de tecnologias como:
Com o avanço dessas tecnologias, os foundation models devem continuar impulsionando soluções modernas de IA, moldando o futuro do desenvolvimento inteligente em diversos setores.
Agora que você já sabe o que são os modelos de IA, como funcionam e para que servem, está na hora de dar o próximo passo: aprender a criar os seus próprios modelos. E o melhor caminho para isso é usar Python, a linguagem de programação mais utilizada no universo da inteligência artificial.
A Trilha de Aplicações de IA com Python da Asimov Academy foi feita exatamente para isso! Com aulas práticas, projetos guiados e exemplos do mundo real, você aprende de forma aplicada como funcionam os modelos de IA e como usá-los para resolver problemas de verdade.
Comece hoje mesmo a construir seus próprios modelos de IA!

Crie agentes autônomos combinando modelos de linguagem (como ChatGPT, DeepSeek e Claude) com Python.
Comece agora
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:







Comentários
30xpShow
Olá, Vitor!
É muito bacana mesmo! 🚀