


Para aqueles que estão se aventurando no universo do machine learning, entender como melhorar a precisão das previsões pode ser a chave para resolver problemas desafiadores. E se eu te dissesse que a solução pode estar na combinação de diferentes modelos de previsão? Isso é o que o Ensemble Learning propõe: reunir várias “mentes” para tomar decisões mais robustas e confiáveis. Em vez de confiar em um único modelo, essa técnica combina os pontos fortes de vários algoritmos, gerando resultados que são mais precisos e generalizáveis.
Vamos explorar o que é o Ensemble Learning e como suas principais técnicas, como Bagging, Boosting e Stacking, podem transformar o desempenho dos seus modelos, tornando-os mais inteligentes e preparados para enfrentar diferentes desafios.
O que é Ensemble Learning?
Sabe aquela velha história de que “duas cabeças pensam melhor que uma”? No mundo do aprendizado de máquina, isso se chama Ensemble Learning. Mas aqui, em vez de duas cabeças, estamos falando de vários modelos trabalhando juntos para resolver um problema e dar respostas mais precisas. A ideia é simples: juntar forças para criar algo mais robusto e confiável do que qualquer modelo isolado.
E para isso o Ensemble Learning treina vários modelos (que podem ser iguais ou diferentes) para realizar a mesma tarefa. Depois, combina os resultados deles para formar uma “superprevisão”. Isso ajuda a reduzir erros, tanto de bias (quando o modelo é simplista demais) quanto de variance (quando ele é sensível demais a pequenas mudanças nos dados).
Pense nas Random Forests, por exemplo. Elas criam várias árvores de decisão, cada uma analisando uma parte dos dados, e depois votam na melhor solução. Esse trabalho em equipe é o que torna as Random Forests tão incríveis.
Como funciona o Ensemble Learning?
O Ensemble Learning combina as previsões de múltiplos modelos de machine learning para criar um resultado final mais preciso e confiável. Essa técnica pode ser aplicada tanto com modelos que trabalham de forma independente quanto com modelos sequenciais, utilizando métodos como média, votação ou até um modelo adicional que organiza e melhora os resultados.
Agora, imagine isso na prática: você está usando árvores de decisão. Em vez de treinar apenas uma árvore para analisar os dados, treina várias. Cada árvore dá sua opinião ou voto sobre a classificação dos dados. No final, junta tudo: a classe com mais votos é a escolhida, no caso de classificação, ou calcula-se a média das previsões, em regressão.
Se quiser algo mais avançado, como no Boosting, o processo é diferente. Aqui, cada modelo aprende com os erros do anterior. É como um grupo onde cada integrante cobre a falha do outro, construindo uma solução cada vez mais precisa.
No fundo, o Ensemble Learning é isso: um jeito inteligente de unir. Cada modelo contribui, e a soma das partes gera previsões mais confiáveis e robustas.
Por que usar Ensemble Learning?
O Ensemble Learning é uma estratégia interessante para melhorar a qualidade das previsões em machine learning. Ele se destaca por combinar a força de vários modelos, reduzindo erros e aumentando a robustez do sistema. Essa técnica é muito útil para superar limitações como o overfitting, quando o modelo aprende demais com os dados de treinamento, ou underfitting, quando ele não captura a complexidade necessária.
Ao usar múltiplos modelos, você equilibra as fraquezas de cada um. Imagine que um modelo sozinho possa errar por ser muito simples ou muito específico. O Ensemble Learning junta diferentes perspectivas, criando um resultado que aproveita o melhor de cada um. Isso gera previsões mais precisas e generalizáveis, mesmo em cenários desafiadores.
Outro ponto forte é a redução de viés e variância. Modelos simples (como regressão linear) podem ter alto viés, simplificando demais os dados. Já modelos mais complexos (como redes neurais profundas) podem sofrer de alta variância, sendo sensíveis a pequenas variações nos dados. O Ensemble Learning combina essas abordagens, equilibrando os extremos e gerando um modelo que funciona bem tanto nos dados de treino quanto em novos dados.
Principais métodos de Ensemble Learning
O que é Bagging?
Bagging, ou Bootstrap Aggregating, é uma técnica de machine learning que cria vários subconjuntos de dados, usando amostragem com reposição, para treinar múltiplos modelos independentes. No final, esses modelos combinam suas previsões por média (para regressão) ou votação (para classificação), criando um modelo mais robusto e menos propenso a overfitting.
Entendendo o Bootstrapping
Antes de entender Bagging, é importante conhecer o conceito de Bootstrapping. Essa técnica consiste em criar subconjuntos menores do conjunto de dados original, selecionando amostras de forma aleatória e com reposição. Isso significa que um mesmo dado pode aparecer mais de uma vez no subconjunto. Essa abordagem ajuda a explorar melhor os dados e a capturar suas características gerais, como média e desvio padrão.
No Bagging, o modelo treina com cada subconjunto gerado e, em seguida, combina os resultados para formar a previsão final. Esse processo reduz o risco de overfitting, embora possa introduzir um pouco mais de bias.
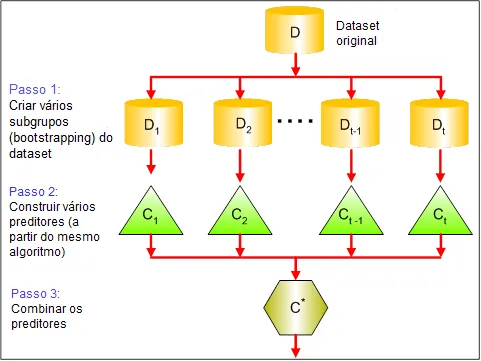
Como funciona o Bagging?
O funcionamento é bem direto:
- Crie múltiplos subconjuntos de dados a partir do conjunto original;
- Treine um modelo separado em cada subconjunto;
- Combine as previsões desses modelos, usando métodos como média (para regressão) ou votação (para classificação).
Um exemplo famoso de Bagging é o Random Forest, que utiliza árvores de decisão como modelos base. Cada árvore é treinada em um subconjunto diferente, e as previsões são combinadas para criar uma saída final confiável.
Exemplo prático: Random Forest em Python
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Carregar o conjunto de dados
data = load_iris()
X = data.data
y = data.target
# Dividir os dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Criar o modelo Random Forest
model = RandomForestClassifier(n_estimators=100, random_state=42)
# Treinar o modelo
model.fit(X_train, y_train)
# Fazer previsões
predictions = model.predict(X_test)Essa abordagem simples e eficiente exemplifica como o Bagging pode ser aplicado na prática, melhorando a precisão e reduzindo a variabilidade nas previsões.
Boosting
O que é Boosting?
Boosting é uma técnica de Ensemble Learning que transforma modelos fracos em um modelo forte. Ao contrário de outras abordagens, como o Bagging, o Boosting treina modelos de forma sequencial, com cada modelo focando em corrigir os erros dos anteriores. O objetivo aqui é diminuir a bias dos modelos iniciais, criando um preditor final que seja muito mais preciso e robusto. Essa técnica é bastante popular em competições de machine learning devido à sua grande capacidade de adaptação e excelente performance.
Como funciona o Boosting?
O Boosting segue um processo iterativo e sequencial:
- Um modelo inicial é treinado com os dados disponíveis;
- As previsões deste modelo são avaliadas, e os erros, identificados;
- Um novo modelo é treinado, com foco nos erros do modelo anterior;
- Esse processo se repete várias vezes e, no final, as previsões de todos os modelos são combinadas para formar uma previsão final mais precisa.
Cada modelo subsequente tem a tarefa de corrigir os erros cometidos pelo modelo anterior. O Boosting, então, combina os modelos com o objetivo de reduzir a bias do sistema. Para isso, os modelos base utilizados são simples, com alto bias e baixa variância, como as árvores de decisão rasas.
AdaBoost: o mais famoso dos Boosting
Um dos algoritmos mais populares dessa técnica é o AdaBoost (Adaptive Boosting). O diferencial do AdaBoost é que ele dá maior peso às instâncias mais difíceis (aquelas em que o modelo anterior teve mais dificuldades para prever). Isso faz com que cada modelo subsequente tenha um impacto maior nas predições certas e corrija as falhas do modelo anterior.
Cada modelo começa com um peso igual, mas à medida que o treinamento avança, os modelos que acertam mais predições passam a ter um peso maior, e aqueles que erram mais têm um peso menor. Com isso, o Ensemble final se torna muito mais robusto.
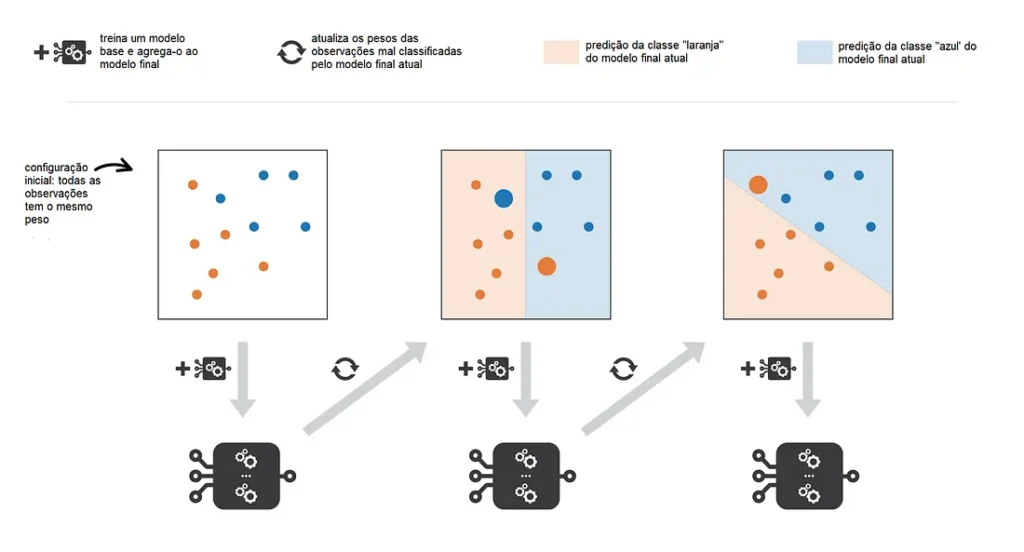
Exemplo prático: implementando AdaBoost em Python
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Carregar o conjunto de dados
data = load_iris()
X = data.data
y = data.target
# Dividir os dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Criar um modelo base (árvore de decisão de baixa profundidade)
base_model = DecisionTreeClassifier(max_depth=1)
# Criar o modelo AdaBoost
boosting_model = AdaBoostClassifier(base_estimator=base_model, n_estimators=50, random_state=42)
# Treinar o modelo
boosting_model.fit(X_train, y_train)
# Fazer previsões
boosting_predictions = boosting_model.predict(X_test)Esse código implementa o AdaBoost, que começa com um modelo simples de árvore de decisão e, em seguida, ajusta os pesos dos modelos subsequentes para corrigir os erros dos anteriores. Ao final, temos um Ensemble mais preciso e robusto, pronto para fazer previsões com maior acurácia.
Stacking
O que é Stacking?
Stacking, ou Stacked Generalization, é uma técnica de Ensemble Learning que combina modelos diferentes para melhorar a precisão das previsões. Diferentemente do Bagging e Boosting, o Stacking utiliza modelos paralelos, treinados de forma independente, e depois combina suas previsões por meio de um modelo adicional chamado de meta-modelo. O meta-modelo aprende a melhor forma de combinar as saídas dos modelos base, aproveitando o que cada um fez de melhor.
Como funciona o Stacking?
O processo de Stacking pode ser descrito da seguinte forma:
- Treinamento inicial: vários modelos (como árvores de decisão, KNN, Random Forest) são treinados no mesmo conjunto de dados;
- Predições: cada modelo faz suas previsões no conjunto de dados de treino e no conjunto de dados de teste;
- Meta-modelo: as previsões dos modelos base (os “weak learners”) são usadas como novas features para treinar um modelo final. Esse modelo, o meta-modelo, pode ser, por exemplo, uma regressão logística;
- Combinando as previsões: o meta-modelo aprende a combinar as previsões de maneira a melhorar a performance, considerando onde cada modelo base foi mais preciso e onde errou.
O objetivo do Stacking é criar um modelo final que se beneficie dos pontos fortes de cada modelo individual, equilibrando as fraquezas deles. Esse processo de combinação permite que o Ensemble tenha uma performance superior ao modelo simples.
Exemplo prático de Stacking em Python
Aqui está um exemplo de como implementar o Stacking usando a biblioteca Scikit-learn:
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Carregar o conjunto de dados
data = load_iris()
X = data.data
y = data.target
# Dividir os dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Definir os modelos base
base_models = [
('rf', RandomForestClassifier(n_estimators=100)),
('dt', DecisionTreeClassifier())
]
# Criar o modelo Stacking
stacking_model = StackingClassifier(estimators=base_models, final_estimator=LogisticRegression())
# Treinar o modelo
stacking_model.fit(X_train, y_train)
# Fazer previsões
stacking_predictions = stacking_model.predict(X_test)Comparação entre Bagging, Boosting e Stacking
Você já se deparou com conceitos, técnicas e exemplos de Bagging, Boosting e Stacking no Ensemble Learning e, embora compartilhem o objetivo de melhorar a precisão das previsões, cada uma traz algo único para a mesa. Vamos explorar suas diferenças e ver qual delas pode ser mais interessante para o seu problema.
Bagging (Bootstrap Aggregating)
O Bagging é uma técnica que pode ser vista como uma forma de dar mais confiança a modelos instáveis, como árvores de decisão. Ele faz isso ao criar várias instâncias do mesmo algoritmo, treinadas em subconjuntos aleatórios dos dados de treinamento, gerados por amostragem com reposição.
O funcionamento é simples: cada modelo é treinado de forma independente, e suas previsões são combinadas através de média (para problemas de regressão) ou votação (para classificação). Isso resulta em um modelo final mais estável e robusto.
Boosting
O Boosting, por outro lado, é como um time trabalhando de maneira sequencial para alcançar um objetivo comum. Aqui, em vez de treinar os modelos de forma independente, cada modelo é treinado para corrigir os erros cometidos pelo anterior. Ao fazer isso, o Boosting foca em melhorar a precisão, ajustando os pesos das instâncias mal classificadas.
Cada novo modelo se concentra no que os anteriores erraram, e o resultado final é uma combinação ponderada das previsões de todos os modelos. Embora o Boosting possa aumentar significativamente a precisão, ele tende a ser mais suscetível ao overfitting, especialmente se o modelo não for bem ajustado.
Stacking
Agora, o Stacking é como uma orquestra, onde vários modelos são treinados e, em seguida, suas previsões são usadas como entradas para um meta-modelo, que aprende a melhor forma de combiná-las. Em vez de simplesmente juntar os resultados, o Stacking envolve a criação de um modelo superior que se beneficia dos pontos fortes de cada modelo base.O poder do Stacking vem da diversidade dos modelos base. Quando bem implementado, essa técnica tende a produzir melhores resultados do que tanto Bagging quanto Boosting, especialmente quando se utiliza uma combinação de modelos diferentes. Um exemplo comum seria usar árvores de decisão, regressão logística e outros modelos base, com um modelo linear como meta-modelo.
| Característica | Bagging | Boosting | Stacking |
|---|---|---|---|
| Objetivo principal | Reduzir variância | Reduzir viés | Combinar previsões |
| Método de treinamento | Paralelo | Sequencial | Híbrido |
| Sensibilidade ao Overfitting | Menor | Maior | Variável |
| Exemplos comuns | Random Forest | AdaBoost, XGBoost | Modelos heterogêneos combinados |
5 aplicações práticas do Ensemble Learning
Os métodos de Ensemble Learning, como Bagging, Boosting e Stacking, não são apenas teorias interessantes, mas são fundamentais para uma série de aplicações práticas no mundo real. O que torna essas técnicas tão únicas é a forma como conseguem combinar diversos modelos para criar uma solução mais robusta e precisa. Aqui estão algumas áreas em que essas técnicas são amplamente usadas:
1. Detecção de fraudes
Em instituições financeiras, técnicas de Ensemble Learning, como o Random Forest (Bagging) e o Gradient Boosting, são fundamentais para detectar fraudes. Eles analisam padrões de comportamento nas transações e ajudam a identificar transações suspeitas. O uso de múltiplos modelos torna a detecção mais precisa, minimizando a quantidade de falsos positivos, o que é vital para não prejudicar a experiência do cliente.
Análise de crédito com Machine Learning
2. Diagnóstico médico
O diagnóstico correto e rápido pode salvar vidas em hospitais e clínicas, e os modelos de Ensemble Learning são usados para prever doenças com base em dados clínicos. Modelos de Boosting são particularmente eficazes para tarefas como a classificação de imagens médicas ou a previsão de doenças a partir de dados laboratoriais. A combinação de modelos diferentes melhora a precisão, oferecendo diagnósticos mais confiáveis.
Prevendo risco de doenças cardíacas com Machine Learning
3. Previsão de vendas
Empresas precisam prever as vendas para ajustar seus estoques e estratégias de marketing de maneira eficiente. Os modelos de Ensemble são usados para analisar dados históricos, levando em conta variáveis como sazonalidade e condições econômicas. O Stacking é ideal para combinar diferentes modelos preditivos, como regressão linear e árvores de decisão, permitindo previsões de vendas mais precisas, ajudando as empresas a tomarem decisões informadas.
4. Reconhecimento de imagens
O reconhecimento automático de objetos em imagens é fundamental em muitas áreas, como segurança e comércio eletrônico.As técnicas como Bagging e Boosting podem ser frequentemente utilizadas em competições de aprendizado de máquina, como o Kaggle, para melhorar o desempenho em tarefas de classificação de imagens. A combinação de diferentes modelos ajuda a capturar características variadas das imagens, tornando o sistema mais preciso e robusto.

Crie um Bot Nutricionista com Inteligência Artificial no Telegram
5. Análise de sentimentos
As empresas precisam entender como os consumidores percebem seus produtos e serviços para melhorar a experiência e otimizar suas ofertas. Modelos de Ensemble, nesse caso, podem ser usados para analisar grandes volumes de texto, como avaliações e comentários de clientes, para classificar os sentimentos expressos (positivo, negativo ou neutro). O Stacking pode ser aplicado para combinar diferentes abordagens, como análise léxica e deep learning, garantindo uma análise de sentimentos mais precisa e com maior capacidade de captar nuances.

Prompts para Inferência e Análise de Sentimentos
Dê o próximo passo na sua jornada com machine learning
Explorar técnicas avançadas de Machine Learning, como Ensemble Learning, pode transformar sua forma de trabalhar com dados. Métodos como Bagging, Boosting e Stacking são ferramentas poderosas que, quando bem aplicadas, aumentam a precisão de previsões e tornam os modelos mais robustos e confiáveis. Além disso, entender como essas técnicas funcionam e como evitar armadilhas como o overfitting pode ser um diferencial competitivo na sua carreira.
Se você quer dominar essas habilidades, o curso Árvores de Decisão e Ensemble Learning é a escolha certa. Nele, você aprenderá a construir modelos de alto desempenho a partir de conceitos fundamentais de árvores de decisão até técnicas avançadas de Ensemble Learning. O curso também inclui práticas aplicadas, como um projeto de análise de crédito, que o prepara para implementar esses conhecimentos em desafios reais do mercado.
Agora é o momento de investir no seu desenvolvimento e se destacar como um especialista em Machine Learning. Inscreva-se no curso Árvores de Decisão e Ensemble Learning e dê o próximo passo na sua jornada profissional.

Árvores de Decisão e Ensemble Learning
Você também pode gostar:





Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp