
Leia também:
O Text-to-Speech (TTS) é a tecnologia que transforma texto em áudio com voz natural. Ele começou como um recurso de acessibilidade, mas hoje está em tudo: leitores de tela, assistentes virtuais, IVRs, narração automática de conteúdo, dublagem e até podcasts gerados por inteligência artificial (IA).
A OpenAI oferece modelos de TTS rápidos e de alta qualidade, como o tts-1 e o tts-1-hd. Eles entregam vozes naturais, suportam vários idiomas e permitem streaming. Tudo isso pode ser integrado facilmente em aplicações Python.
Neste tutorial, você vai aprender a gerar áudio a partir de texto usando a API da OpenAI (Text-to-Speech), escolhendo vozes, definindo formatos (MP3 ou WAV) e salvando o arquivo localmente com poucas linhas de código.
Importante: se você precisa do caminho inverso (transformar áudio em texto) confira também nosso tutorial de Speech-to-Text (Whisper).
Como funciona a geração de voz da OpenAI
A geração de voz da OpenAI funciona por modelos neurais de TTS que convertem texto em fala natural. Quando você envia um texto para o endpoint audio/speech, modelos como gpt-4o-mini-tts, tts-1 e tts-1-hd processam o conteúdo e retornam um áudio com ritmo, pausas e entonação muito próximas de uma voz humana.
Esses modelos já oferecem vozes prontas e podem ser usadas imediatamente, sem configuração extra. O processo acontece em duas etapas principais:
1. Interpretação do texto
O modelo analisa o conteúdo antes de gerar áudio. Ele identifica:
- Pausas naturais;
- Entonação adequada;
- Pronúncia de expressões;
- Palavras que precisam de mais destaque;
- O ritmo ideal da fala.
Isso só é possível porque os modelos foram treinados com grandes conjuntos de áudios e transcrições, entendendo nuances da fala humana em diferentes sotaques e velocidades.
2. Síntese de voz
Depois da interpretação, o modelo transforma o texto em uma representação acústica (como um espectrograma). A partir dela, o vocoder interno gera a forma de onda final, o arquivo de áudio que você recebe.
Esse pipeline de análise + síntese é o que garante vozes mais naturais e expressivas, muito superiores aos sintetizadores antigos. No fim, você consegue gerar falas em vários idiomas, narrar conteúdos, dublar vídeos e até produzir áudio em tempo real com poucas linhas de Python.
Quer saber como ter um gerador local e gratuito? O nosso Prof. Rodrigo ensina tudo sobre o famoso Kokoro TTS 82M, neste vídeo:
Qual modelo de TTS usar?
A OpenAI oferece três modelos principais para TTS. A escolha depende do tipo de aplicação que você quer desenvolver.
- gpt-4o-mini-tts: modelo mais novo e o mais indicado para aplicações em tempo real. Além de gerar voz natural, permite ajustar várias características da fala, como emoção, velocidade, entonação, sussurros e acento. Recomendado para quem precisa de respostas rápidas e personalização avançada;
- tts-1: modelo otimizado para baixa latência. É rápido e eficiente, recomendado para gerar muitos áudios sem exigir a máxima fidelidade. Use quando a prioridade é velocidade;
- tts-1-hd: versão de alta qualidade. Entrega mais naturalidade, expressividade e riqueza de detalhes. É a melhor opção para narrações, vídeos, conteúdos profissionais e podcasts gerados por IA.
Vozes e o formato de saída
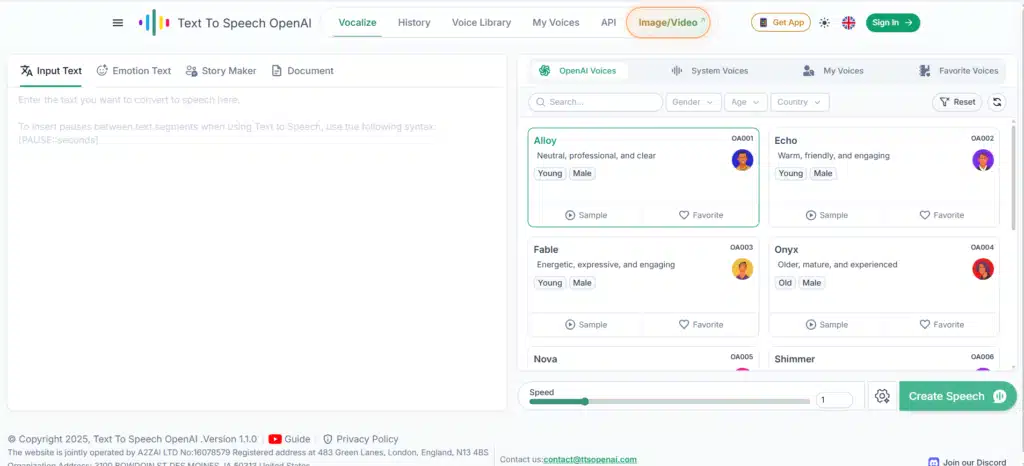
Antes de gerar o áudio, você precisa escolher duas coisas:
- Qual voz vai narrar o texto
- O formato do arquivo (MP3 ou WAV)
A API de Text-to-Speech da OpenAI já inclui várias vozes prontas. Elas são otimizadas para inglês, mas funcionam bem com português. Algumas têm entonação natural mesmo em textos longos.
Vozes disponíveis
As vozes mais comuns são:
- Alloy;
- Echo;
- Fable;
- Onyx;
- Nova;
- Shimmer.
Além delas, existem outras opções como coral, ash, ballad e sage, totalizando 11 vozes.
Importante:
Para português, a onyx geralmente entrega o resultado mais natural (grave, estável e menos metálica). Mas, dependendo do estilo do texto, as vozes shimmer e nova também funcionam bem.
Vale lembrar que você pode testar as vozes antes de usar. Para isso, use a demo oficial: OpenAI.fm, uma ferramenta simples para ouvir as vozes e encontrar a que combina melhor com o seu projeto.
Formatos de saída (MP3 x WAV)
A API permite gerar áudio em diferentes formatos. Os mais usados são:
- MP3: arquivo menor, ideal para web, bots, notificações e apps móveis;
- WAV: qualidade máxima, sem compressão. Boa opção para podcasts, dublagens e edição profissional.
Como usar a API da Open AI (Text-to-speech): passo a passo
Vamos montar todo o ambiente e escrever o primeiro código capaz de transformar texto em voz usando os modelos de TTS da OpenAI.
O que você precisa antes de começar
- Python 3.10+ instalado;
- Chave de API da OpenAI;
- SDK oficial atualizado;
- Um editor de código, como VS Code, PyCharm, entre outros.

Veja também:
Melhor IDE para Python: Qual é o melhor editor de código Python?
1. Prepare o ambiente (Python + SDK + chaves)
Vamos instalar duas bibliotecas:
openai: SDK oficial;python-dotenv: para carregar sua chave com segurança
Para isso, instale as dependências:
pip install openai python-dotenvConfigure sua variável de ambiente
Em seguida, crie um arquivo .env na raiz do projeto:
OPENAI_API_KEY=coloque_sua_chave_aquiImportante: nunca faça commit da sua chave em repositórios Git. O .env deve estar no .gitignore.
2. Converta texto em áudio (Python)
Agora vamos transformar um texto em voz usando o modelo gpt-4o-mini-tts (ou tts-1, se preferir). O fluxo é simples:
- Carregue a chave de API;
- Defina o texto que será narrado;
- Escolha a voz;
- Chame o endpoint de TTS;
- Salve o áudio em MP3 ou WAV.
Exemplo básico em Python
from pathlib import Path
from openai import OpenAI
from dotenv import load_dotenv
import os
# Carrega variáveis do .env
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Caminho do arquivo final
speech_file_path = Path("voz.mp3")
with client.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts", # ou tts-1 / tts-1-hd
voice="coral", # escolha a voz desejada
input="Hoje é um ótimo dia para construir algo que as pessoas vão amar!",
instructions="Fale com um tom alegre e positivo."
) as response:
response.stream_to_file(speech_file_path)Esse código:
- Envia o texto para o endpoint de TTS;
- Usa a voz coral;
- Recebe o áudio via streaming;
- Salva o arquivo como voz.mp3.
Por padrão, o endpoint gera um MP3, mas você pode pedir outros formatos, como WAV.
3. Gere outros formatos (WAV, por exemplo)
Para isso, inclua o parâmetro format:
response = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="nova",
input="Gerando áudio em formato WAV.",
response_format="wav"
)4. Toque o áudio em memória (opcional)
Se quiser apenas ouvir o áudio sem salvar o arquivo, você pode ler o retorno em bytes e reproduzir usando bibliotecas como playsound, pydub ou APIs de áudio do próprio sistema.

Leia também:
Como usar IA para transcrever áudio automaticamente com Python
Exemplo prático: escrevendo o código para criar áudios
Agora que você já sabe como funciona o Text-to-Speech da OpenAI e quais modelos pode usar, vamos ao principal: gerar um áudio real a partir de um texto usando Python.
O exemplo abaixo mostra o fluxo completo de criação, desde o carregamento da chave até a criação do arquivo MP3. A ideia é que você veja, na prática, como funciona uma requisição ao endpoint audio/speech e como configurar modelo, voz e texto de forma simples.
No final da execução, você terá um arquivo fala.mp3 gerado com o modelo tts-1 e a voz onyx, que geralmente entrega um bom resultado em português.
Código completo
from openai import OpenAI
from dotenv import load_dotenv
import os
# Carrega variáveis do .env
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Texto que será transformado em áudio
texto = """
Python é uma linguagem de programação de alto nível, interpretada, imperativa e orientada a objetos.
Foi lançada por Guido van Rossum em 1991 e hoje é mantida pela Python Software Foundation.
"""
# Gera o áudio
response = client.audio.speech.create(
model="tts-1",
voice="onyx",
input=texto,
)
# Salva o arquivo
with open("fala.mp3", "wb") as f:
f.write(response.read())Entenda o que diz o código
Vamos explicar, passo a passo, o que cada trecho faz.
Importações necessárias
from openai import OpenAI
from dotenv import load_dotenv
import osAqui, importamos:
- OpenAI: cliente oficial para fazer chamadas à API;
- load_dotenv: usado para carregar a variável
OPENAI_API_KEYdo arquivo.env; - os: para acessar variáveis de ambiente.
Essas importações garantem que sua chave não fique exposta no código.
Carregando a chave de API com segurança
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))Nessas linhas:
load_dotenv()lê o arquivo.env;os.getenv("OPENAI_API_KEY")recupera sua chave;OpenAI(...)cria o cliente que vamos usar para chamar o modelo de Text-to-Speech.
Ponto importante: nunca coloque a chave da API diretamente no código.
O texto que será transformado em áudio
texto = """
Python é uma linguagem de programação de alto nível, interpretada, imperativa e orientada a objetos.
Foi lançada por Guido van Rossum em 1991 e hoje é mantida pela Python Software Foundation.
"""Nessa etapa, você define o conteúdo que será narrado. Pode ser:
- Uma string direta;
- Um texto carregado de um .txt;
- Vários parágrafos.
O modelo vai interpretar exatamente o que estiver nessa variável.
Chamando o endpoint de Text-to-Speech
response = client.audio.speech.create(
model="tts-1",
voice="onyx",
input=texto,
)Essa é a parte mais importante. Aqui, dizemos:
- model=”tts-1″: o modelo que vai gerar a voz;
- voice=”onyx”: a voz usada para a narração;
- input=texto: conteúdo a ser lido.
O retorno dessa função já é o áudio pronto.
Salvando o arquivo gerado
with open("fala.mp3", "wb") as f:
f.write(response.stream_to_file("fala.mp3")) Essa parte:
- Abre um arquivo fala.mp3 em modo binário;
- Grava o áudio retornado pela API;
- Salva o arquivo localmente.
Você pode mudar o nome para algo como narracao.mp3 ou audio.wav, por exemplo.
Execute o código
Salve o arquivo e execute:
python tts.pySe tudo estiver configurado corretamente, o arquivo fala.mp3 será criado na pasta do projeto, já com seu texto narrado.
O que dá para fazer com esse exemplo?
Com esse padrão de código, você consegue gerar áudio para praticamente qualquer aplicação. Por exemplo:
- Narrar artigos automaticamente;
- Criar áudios para vídeos;
- Enviar avisos falados em bots;
- Montar podcasts sem narrador humano;
- Gerar feedback de voz em apps e automações.
O que muda de um caso para outro são apenas quatro parâmetros:
- Texto (input);
- Voz (voice);
- Formato (MP3 ou WAV);
- Modelo (priorizando velocidade ou qualidade).
Com esses ajustes simples, você reaproveita exatamente a mesma estrutura para qualquer projeto.
Aprenda na prática:
Asimov Transcripts – Transcrevendo áudios com a API do ChatGPT
Dicas importantes para usar a API de áudio da Open AI
Antes de usar o Text-to-Speech na prática, é importante seguir as orientações abaixo:
Fatie textos longos em blocos menores
A API aceita entradas de até 4096 caracteres (aproximadamente 5 minutos de áudio). Por isso, para textos maiores, o ideal é dividir o conteúdo em parágrafos e enviar cada trecho separadamente. No final, você pode concatenar (unir) os arquivos.
Essa estratégia evita timeouts, reduz a latência e deixa a narração mais uniforme e coesa, especialmente em textos longos.
Latência
Modelos de TTS levam alguns segundos para gerar o áudio, principalmente quando o texto é muito grande, há instruções detalhadas de voz ou você usa o tts-1-hd (mais pesado).
Para aplicações em tempo real, como assistentes de voz ou respostas instantâneas, o melhor modelo é o gpt-4o-mini-tts, otimizado para baixa latência.
Limites da API de áudio
Para contas pagas, os limites padrão são:
- 50 requisições por minuto (RPM);
- 4096 caracteres por requisição.
Esses valores são suficientes para projetos pessoais e pequenos sistemas.
Realtime API (fala-em/fala-out)
Se você precisa de uma experiência realmente interativa, ou seja, ouvir o microfone, gerar áudio em tempo real e responder com baixa latência, use a Realtime API.
Ela permite que você faça streaming de entrada e saída, interrompa e retome a fala, além de fornecer respostas praticamente instantâneas para assistentes falados.
Casos de uso práticos da API de áudio da OpenAI (Text-to-Speech)
Agora que você já sabe usar o TTS da OpenAI, veja alguns exemplos de onde usar essa API na prática.
- Acessibilidade (leitura de conteúdo): transforme qualquer texto em áudio para apoiar pessoas com deficiência visual ou dificuldades de leitura. Por exemplo, converta artigos de blog em narrações e PDFs e documentos em áudios;
- Narração automática de posts e artigos: se você publica conteúdo com frequência, o TTS gera versões em áudio sem precisar de um narrador humano. Por exemplo, você pode criar versões narradas de newsletters e transformar capítulos de livros em MP3;
- IVR, voice bots e notificações em apps: você também pode usar o TTS para criar mensagens automáticas para call centers, assistentes de voz no WhatsApp ou Telegram e notificações faladas em apps de mobilidade ou entregas, por exemplo;
- Áudio em vários idiomas: mesmo otimizadas para inglês, as vozes da OpenAI funcionam bem em português, espanhol, francês e outros idiomas. Por isso, você pode usar essa ferramenta para criar aulas personalizadas para estudantes de idiomas e diálogos falados para materiais didáticos, por exemplo;
- Chatbots e assistentes mais envolventes: você pode transformar um chatbot tradicional em um assistente de voz quando você adiciona TTS. Dá para criar agentes de suporte e bots de agendamento, por exemplo.
Veja também:
Chatbot com OpenAI e Python: Um Guia Completo para Iniciantes
Dê o próximo passo e crie seus próprios agentes de IA
Com a API de Text-to-Speech da OpenAI, você transforma qualquer texto em áudio natural com poucas linhas de Python.
Mas, se você quiser ir além de gerar voz e começar a criar agentes completos de IA, capazes de ouvir, falar, decidir e agir, faça a Formação Engenheiro de Agentes de IA, da Asimov Academy.
Assim como você aprendeu a dar voz aos seus projetos com TTS, na formação você aprenderá a dar ação e inteligência prática aos seus sistemas.
Você começa do zero, revisando lógica e fundamentos de Python. Depois, evolui para a criação, coordenação e execução de agentes reais, prontos para uso em projetos, automações e aplicações de alto impacto.
Comece agora a construir seus próprios agentes de IA!

Formação Engenheiro de Agentes de IA
Domine os frameworks de criação de agentes de IA mais avançados da atualidade e aprenda a transformar qualquer LLM em um agente!
Comece agoraVocê também pode gostar:










Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp