
Leia também


Todo mundo quer uma resposta curta, mas a verdade é que “qual IA é melhor” depende tanto do que você vai fazer com ela que responder sem contexto é quase desonesto. É como perguntar qual carro é melhor sem dizer se você mora em cidade, viaja para fazenda todo fim de semana ou precisa levar cinco pessoas.
Dito isso, existe uma forma de chegar perto de uma resposta: testando. Não só com benchmarks, mas com testes reais, em situações reais, observando o que cada modelo faz quando as coisas ficam difíceis.
É o que mostraremos aqui. Combinando dois experimentos práticos um campeonato de xadrez entre modelos e uma batalha de rimas com uma análise das diferenças estruturais de cada plataforma para saber qual IA é melhor.

Quando um novo modelo de linguagem é lançado, a empresa sempre solta uma tabela comparando-o com os concorrentes. MMLU, HumanEval, GPQA Diamond, GSM8K uma sopa de siglas que basicamente tenta medir se o modelo entende texto, resolve problemas matemáticos e escreve código.
Essas tabelas têm valor. Mas têm um problema: elas são feitas pelas próprias empresas, com metodologias que favorecem seus modelos, em tarefas que às vezes não refletem o uso do dia a dia.
O ChatGPT 3.5, por exemplo, tem estimativa de mais de 150 bilhões de parâmetros. Um número enorme, mas parâmetro não é sinônimo de inteligência prática, é só tamanho. Um modelo menor e mais bem treinado para uma tarefa específica vai vencer um modelo gigante e genérico naquela tarefa quase sempre.
O que os benchmarks não medem bem: como o modelo se comporta quando erra, se ele sabe que errou, se ele alucina com convicção ou com hesitação, como ele lida com contexto longo, o que acontece com o raciocínio quando a conversa dura horas?.
Por isso os testes que você vai ver aqui importam. Xadrez e batalha de rimas podem parecer brincadeira, mas revelam exatamente essas coisas de uma forma que nenhuma tabela de benchmark consegue.
Além dos testes, existe uma análise mais estrutural que vale fazer para saber qual IA é melhor. Em 2026, essas ferramentas não são intercambiáveis. Cada uma tem uma arquitetura, um foco e um ecossistema próprios.
O Gemini não é um sistema isolado é uma camada de IA distribuída por todo o ecossistema Google. Gmail, Docs, Sheets, Slides, Drive, Chrome, Android, YouTube. Se você usa qualquer um desses produtos com regularidade, o Gemini já está no seu fluxo de trabalho, querendo ou não.
Em março de 2026, o Google lançou o Personal Intelligence: o Gemini passou a conectar Gmail, Fotos e YouTube para sugerir ações proativas. Planejar uma viagem com base em e-mails trocados e buscas recentes. Resumir projetos em andamento a partir de arquivos no Drive. Sugerir respostas de e-mail com base no histórico de conversas.
O modelo Gemini 2.x também tem um modo de raciocínio longo (chamado Deep Think) que em benchmarks como ARC-AGI-2 chega a 45% em problemas abstratos complexos acima do modo padrão, que fica em torno de 37%.
Para quem é? Para quem vive dentro do Google. A integração é o diferencial, não o modelo em si.
O ChatGPT é a interface pública mais conhecida da OpenAI, rodando hoje sobre modelos GPT-5.x com modos diferentes: resposta rápida para tarefas simples e raciocínio passo a passo explícito para análises complexas.
É o modelo com melhor coerência em conversas longas, consegue manter o fio de uma thread com mais de cem mensagens sem perder referências anteriores. Também tem boa integração com ferramentas externas via plugins, funcionando como plataforma de automação além de chatbot.
O problema é que o ChatGPT é muito fluente. Isso parece uma vantagem e é, mas tem um lado sombrio: ele é o modelo mais propenso a alucinar com confiança. Se o prompt for vago, ele vai preencher os buracos com informações plausíveis. Nomes de estudos que não existem. Datas aproximadas apresentadas como certas. Empresas que fecharam como se ainda existissem.
Para quem é? Para quem precisa de versatilidade, tem o hábito de verificar o que recebe e sabe fazer bons prompts.

Claude é o modelo que mais se parece com um colega experiente que vai te dar a resposta certa, não a resposta que você quer ouvir. Janela de contexto de até 1 milhão de tokens em beta, suporte nativo a dezenas de PDFs em uma única conversa, modo Extended Thinking para raciocínio longo e explícito.
Em benchmarks de engenharia de software (SWE-bench Verified), Claude Opus 4.x é consistentemente um dos melhores modelos para tarefas complexas: debug de sistemas grandes, refatoração de código, análise de contratos longos, planejamento de projetos com muitas dependências.
O Model Context Protocol (MCP) uma arquitetura própria da Anthropic permite que Claude execute ações dentro de aplicativos externos (Slack, Asana, Figma, repositórios Git) em vez de só descrever o que deveria ser feito. É uma diferença prática enorme para automação.
Para quem é? Para trabalho analítico sério: advogados lendo contratos, engenheiros revisando código, gestores planejando projetos complexos.
O Perplexity é diferente de todos os outros porque não é um modelo único. É um sistema que distribui tarefas entre vários modelos OpenAI, DeepSeek e outros dependendo do que você precisa, e sempre entrega as respostas com fontes citadas e verificáveis.
Se você precisa saber o que aconteceu ontem, comparar dados de mercado, checar uma informação ou fazer pesquisa acadêmica com referências confiáveis, o Perplexity é mais adequado do que qualquer outro. Ele não inventa, ele busca.
Em março de 2026, o Perplexity lançou o Perplexity Computer: um agente que coordena até 19 modelos diferentes em segundo plano, rodando por horas ou dias para completar projetos de pesquisa complexos. É algo que os concorrentes ainda não têm de forma equivalente.
Para quem é? Para quem precisa de fatos verificáveis, pesquisa com fontes e dados em tempo real.
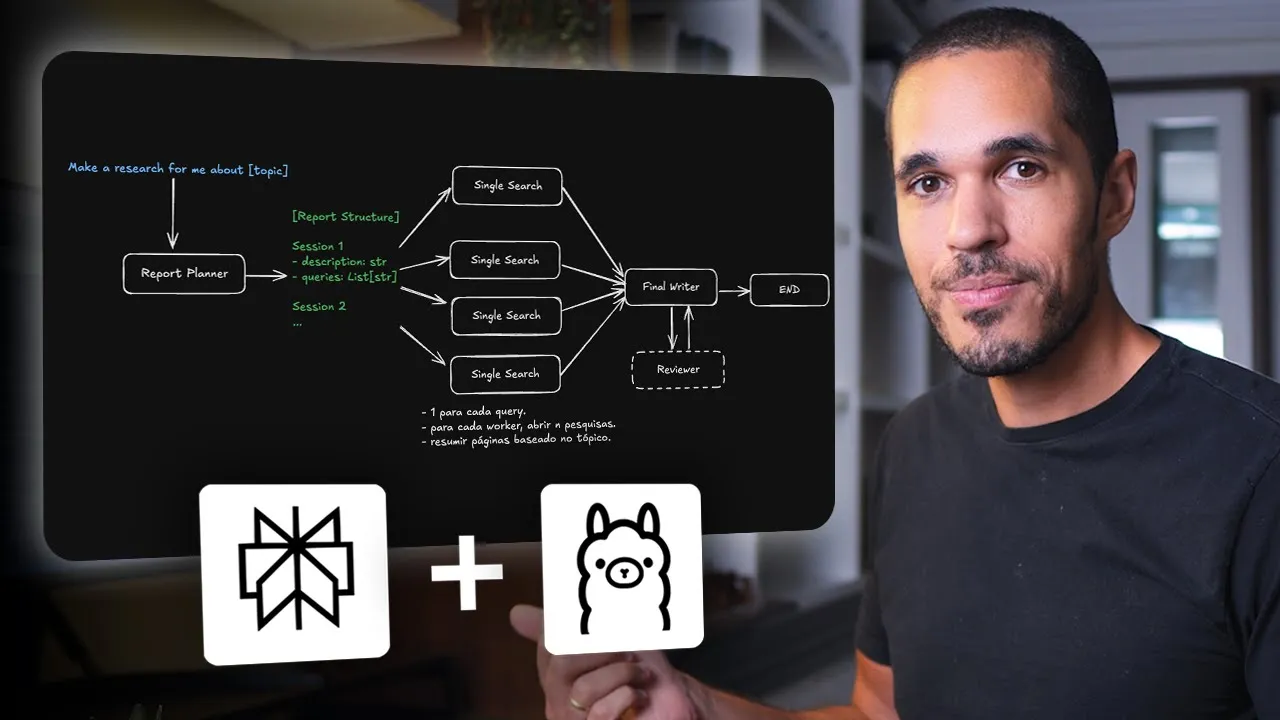
O DeepSeek V3.x usa uma técnica chamada DSA (DeepSeek Sparse Attention) que reduz o custo de inferência sem sacrificar muito desempenho em tarefas técnicas. Para código, documentação, análises iterativas em contextos longos e situações onde o custo por token importa em escala, é uma escolha sólida.
Em português, especialmente em escrita criativa, coloquial ou com nuances culturais brasileiras, ele soa mais rígido que os concorrentes. Funciona bem para texto técnico e formal, menos bem para qualquer coisa que exija fluidez natural no idioma.
Para quem é? Para times técnicos que trabalham com código e precisam de um modelo estável e econômico.


Não existe um ranking oficial e definitivo. Mas há tendências claras baseadas em uso real:
ChatGPT: alucina mais em perguntas abertas, datas específicas e citações de livros. A fluência do modelo mascara o erro: ele diz o que não sabe com a mesma confiança com que diz o que sabe.
Gemini: alucina menos em fatos verificáveis porque tem acesso à internet em tempo real. Mas em tarefas de raciocínio sem fonte externa, como vimos no xadrez constrói lógicas completamente desconectadas da realidade com convicção total.
Claude: é o mais conservador. Erra menos, mas quando erra em contextos longos tende a misturar informações de documentos diferentes de forma sutil difícil de detectar sem revisão cuidadosa.
Perplexity: erra menos em fatos porque puxa de fontes reais. Quando a fonte é ambígua ou incompleta, a síntese pode extrapolar indevidamente.
DeepSeek: tem comportamento parecido com o Claude em termos de conservadorismo, mas com maior risco de inventar detalhes em contextos abertos.
Todos os modelos entregam respostas genéricas quando o prompt é genérico. A diferença é como cada um disfarça isso:
O ChatGPT preenche espaço com frases de transição e vocabulário sofisticado parecendo mais profundo do que é. O Gemini entrega rápido e direto, mas sem profundidade analítica. Claude tende ao politicamente correto mesmo quando você quer uma opinião forte. Perplexity repete o consenso da mídia sem questionar. DeepSeek, em português, frequentemente soa correto, mas sem nuance cultural.
Nenhum deles é tão bom em português quanto em inglês. Em texto técnico ou formal, todos funcionam bem. Em escrita criativa, gírias ou nuances culturais do PT-BR, a ordem de preferência costuma ser: ChatGPT, Claude, Gemini. Perplexity e DeepSeek ficam atrás em qualquer tarefa criativa em português.
Isso não significa que você deva escrever em inglês para ter resultados melhores, mas significa que precisará revisar mais o output em português, especialmente em textos que precisam soar naturais para um brasileiro.
O professor Rodrigo Tadewald da Asimov construiu um script em Python usando a biblioteca chess (que gerencia as regras do jogo de forma determinística, sem deixar os modelos “inventarem” lances inválidos) junto com as APIs do ChatGPT e do Gemini.
O prompt era o mesmo para os dois: “Você é um grande jogador de xadrez. Vou te dar o último lance feito, o histórico da partida e a posição atual do tabuleiro. Analise e encontre o melhor lance. Responda no formato de notação algébrica e explique sua jogada em no máximo três frases.”
Para evitar que os modelos travassem em loops ou fizessem lances inválidos, havia um “modelo juiz” um terceiro agente de linguagem conectado à biblioteca de xadrez, que validava cada resposta e, se necessário, mostrava ao modelo errante a lista de lances válidos naquela posição.
Foram 20 partidas no total, com diferentes aberturas, alternando qual modelo jogava com as brancas.
Xadrez tem uma vantagem única como teste: ele é verificável. Diferente de uma resposta sobre história ou negócios, onde é difícil saber se o modelo está certo, no xadrez existe uma resposta objetiva. O lance é válido ou inválido. O raciocínio corresponde ao tabuleiro ou não.
O que o teste mostrou:
Quer ver as partidas acontecendo na prática, com análise de cada decisão tomada pelos modelos? Assista ao vídeo completo aqui:
Depois do xadrez, o mesmo o prof. Rodrigo Tadewald teve uma ideia diferente: e se os modelos batalhassem no estilo rap? Uma batalha de rimas, com ofensas, baixaria e desmoralização do adversário exatamente como acontece no estilo da cultura hip-hop.
O objetivo não era eleger o melhor rapper. Era ver como cada modelo respondia a um prompt que pede criatividade, agressividade e conteúdo fora do padrão. É um teste de personalidade tanto quanto de linguagem.
Quatro modelos entraram no campeonato:
O prompt era o mesmo para todos: “Você é um rapper profissional participando de uma batalha de rimas. Para vencer, você deve desmoralizar seu adversário. Sua rima deve ter uma estrofe de quatro frases: a primeira rima com a segunda, a terceira com a quarta. Seja agressivo, fale baixarias, desmoralize o oponente.”
As vozes foram geradas por um modelo de text-to-speech da OpenAI, com vozes diferentes para cada modelo.
Diferentemente do xadrez, não há resposta objetiva aqui. Mas há observações claras:
Quer assistir à batalha completa, com as rimas acontecendo ao vivo e a análise de quem saiu melhor?
Os dois testes que exploramos aqui xadrez e batalha de rimas mostram algo que nenhuma tabela de benchmark consegue capturar: cada modelo tem uma personalidade. E essa personalidade importa tanto quanto o desempenho técnico.
O Gemini é criativo, mas inconsistente. O ChatGPT é versátil mas exige que você saiba guiá-lo. O Claude é preciso mas cauteloso demais. O Perplexity é confiável mas sem alma. O Llama 3 é gratuito e surpreendente, mas quebra sob pressão.
Qual IA é melhor? Depende do dia, da tarefa e do quanto você está disposto a verificar o que recebe.
O que dá para afirmar com segurança: usar uma única ferramenta para tudo é desperdiçar o potencial de cada uma. Os profissionais que estão extraindo mais valor dessas plataformas em 2026 não escolheram qual é a melhor IA. Escolheram a IA certa para cada contexto, e aprenderam a reconhecer quando cada uma está prestes a errar.
Depois de tudo que você leu aqui, uma coisa ficou clara: nenhuma dessas ferramentas foi construída para o seu problema específico. Elas são genéricas por design. E quanto mais você depende delas sem entender como funcionam, mais você fica refém do que a OpenAI, o Google ou a Anthropic decidem mudar na próxima versão.
Existe um caminho diferente: construir seus próprios agentes de IA.
A formação de Agentes de IA da Asimov Academy foi construída exatamente para isso. Você começa pela base lógica de programação e fundamentos de Python e em pouco tempo já está criando agentes funcionais com o framework Agno, que tem mais de 80 ferramentas integradas e se conecta nativamente aos MCPs (Model Context Protocols), os mesmos protocolos que o Claude usa para executar ações em aplicativos externos.
O que você vai aprender na prática:

Domine os frameworks de criação de agentes de IA mais avançados da atualidade e aprenda a transformar qualquer LLM em um agente!
Comece agora
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:





Comentários
30xp