Comunidade

Engenharia de Prompts
LG
Lucas Valério Giraldi • 21 dias atrás

Quando se trata de análise de dados em Python, uma das ferramentas mais poderosas e populares é a biblioteca Pandas. Esta biblioteca oferece uma estrutura chamada DataFrame, que é essencialmente uma tabela muito inteligente, similar a uma planilha de Excel. Neste tutorial, vamos explorar o que é um DataFrame do Pandas, e como você pode começar a usá-lo para suas análises de dados.
Imagine uma tabela do Excel com linhas e colunas, onde você pode armazenar dados de diferentes tipos, como números, strings e datas. Agora, imagine que essa tabela tem superpoderes, permitindo que você faça cálculos complexos, alterações e análises com apenas algumas linhas de código. Esse é o DataFrame do Pandas!
Um DataFrame é uma estrutura de dados bidimensional, o que significa que os dados são organizados em linhas e colunas. Cada coluna pode conter um tipo diferente de dado, e cada linha corresponde a um registro, ou seja, um conjunto de informações relacionadas.
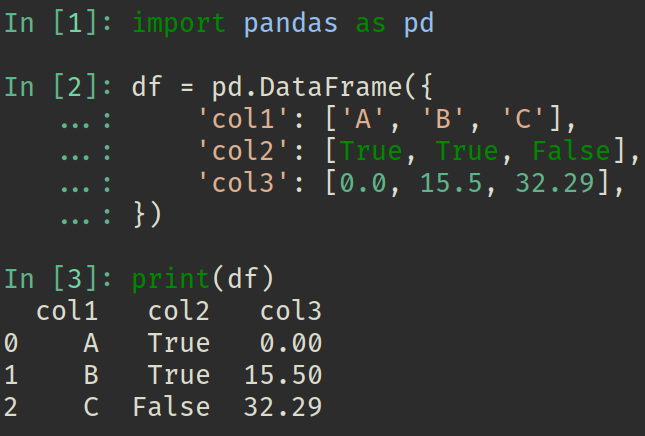
Para criar um DataFrame, você pode começar com algo tão simples quanto uma lista de listas ou um dicionário de listas em Python. Aqui está um exemplo usando um dicionário:
import pandas as pd
# Criando um dicionário com dados
dados = {
'Nome': ['Ana', 'Bruno', 'Carlos'],
'Idade': [25, 30, 45],
'Cidade': ['Rio de Janeiro', 'São Paulo', 'Belo Horizonte']
}
# Convertendo o dicionário em um DataFrame
df = pd.DataFrame(dados)
# Exibindo o DataFrame
print(df)
# output:
# Nome Idade Cidade
# 0 Ana 25 Rio de Janeiro
# 1 Bruno 30 São Paulo
# 2 Carlos 45 Belo HorizonteNote que, na representação acima, cada chave do dicionário corresponde ao nome de uma coluna, e a lista associada à chave são os valores da coluna. Para este exemplo funcionar, é importante que todas as listas tenham o mesmo número de elementos!
Agora que temos nosso DataFrame, vamos explorar alguns métodos úteis de DataFrames com Pandas. Para isso, vamos utilizar o mesmo DataFrame df que criamos acima.
Para dar uma espiada nos dados, você pode usar df.head() para ver as primeiras linhas, ou df.tail() para ver as últimas. Isso é como abrir uma cortina e espiar para dentro da sua tabela de dados.
Podemos passar um valor para estes métodos representando o número de linhas que queremos espiar:
print(df.head(2)) # Espiar as duas primeiras linhas
# output:
# Nome Idade Cidade
# 0 Ana 25 Rio de Janeiro
# 1 Bruno 30 São Paulo
print(df.tail(1)) # Espiar a última linha
# output:
# Nome Idade Cidade
# 2 Carlos 45 Belo HorizonteVocê pode selecionar uma coluna específica usando df['NomeDaColuna'] ou várias colunas com df[['Coluna1', 'Coluna2']]. É como apontar para a coluna que você quer em uma tabela física.
Note que é possível reordenar colunas dessa forma também:
print(df['Nome']) # Olhar apenas a coluna "Nome"
# output:
# 0 Ana
# 1 Bruno
# 2 Carlos
# Name: Nome, dtype: object
print(df[['Idade', 'Nome']]) # Olhar para as colunas "Idade" e "Nome" (nesta ordem)
# output:
# Idade Nome
# 0 25 Ana
# 1 30 Bruno
# 2 45 CarlosNote que a representação é diferente quando selecionamos apenas uma coluna, comparado com a seleção de duas ou mais colunas. Isso acontece porque o objeto retornado quando selecionamos uma única coluna é uma Série do Pandas. Você pode aprender mais sobre como manipular Séries do Pandas neste tutorial.
Para filtrar dados com base em uma condição, você pode usar algo como df[df['Idade'] > 30], que é como dizer “me mostre apenas as linhas onde a idade é maior que 30”:
print(df[df['Idade'] > 30]) # Filtrar por idade maior que 30
# output:
# Nome Idade Cidade
# 2 Carlos 45 Belo HorizontePara adicionar uma nova coluna, você pode simplesmente atribuir os dados a ela, como df['NovaColuna'] = [1, 2, 3]. Remover é tão fácil quanto usar df.drop('NomeDaColuna', axis=1). Pense nisso como colar uma nova coluna em uma tabela ou usar uma borracha para apagar uma que você não quer mais:
df['NovaColuna'] = [1, 2, 3] # Adicionar nova coluna
print(df)
# output:
# Nome Idade Cidade NovaColuna
# 0 Ana 25 Rio de Janeiro 1
# 1 Bruno 30 São Paulo 2
# 2 Carlos 45 Belo Horizonte 3
df = df.drop('NovaColuna', axis=1) # Remover nova coluna
print(df)
# output:
# Nome Idade Cidade
# 0 Ana 25 Rio de Janeiro
# 1 Bruno 30 São Paulo
# 2 Carlos 45 Belo HorizonteO detalhe importante aqui é que df.drop() retorna um DataFrame novo, portanto é preciso passá-lo para a mesma variável df se quisermos que o DataFrame modificado sobrescreva o antigo.
Por padrão, o DataFrame está ordenado em seu índice, que geralmente é composto por valores numéricos partindo de zero. Se ao invés disso você quiser ordenar as linhas por uma das colunas, pode usar df.sort_values('NomeDaColuna'):
print(df.sort_values('Idade')) # Ordenar por idade
# output:
# Nome Idade Cidade
# 0 Ana 25 Rio de Janeiro
# 1 Bruno 30 São Paulo
# 2 Carlos 45 Belo Horizonte
print(df.sort_values('Cidade')) # Ordenar por cidade (ordem alfabética)
# output:
# Nome Idade Cidade
# 2 Carlos 45 Belo Horizonte
# 0 Ana 25 Rio de Janeiro
# 1 Bruno 30 São PauloDataFrames são incrivelmente poderosos e podem fazer muito mais do que mostramos aqui. Mas com esses conceitos básicos e métodos, você já pode começar a explorar seus próprios conjuntos de dados. Lembre-se, a prática leva à perfeição, então comece a brincar com seus próprios DataFrames e veja o que você pode descobrir!

Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:






Comentários
30xp