

O que é o algoritmo Random Forest?
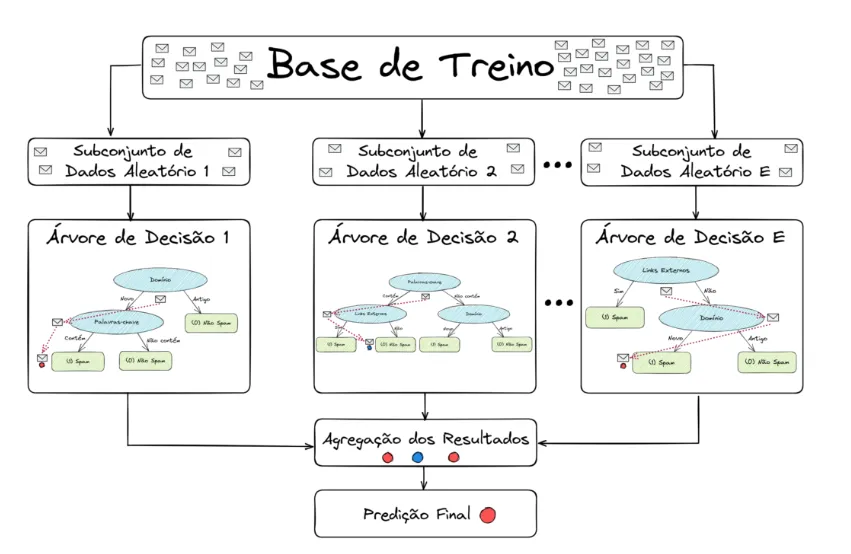
Random Forest (ou “Floresta Aleatória”) é um algoritmo de machine learning que usa várias árvores de decisão para fazer previsões mais precisas. Em vez de depender de uma única árvore que pode errar fácil dependendo dos dados, ele consulta uma “floresta” de árvores. Cada uma dá seu palpite, e a decisão final é feita por votação (no caso de classificação) ou média (no caso de regressão).
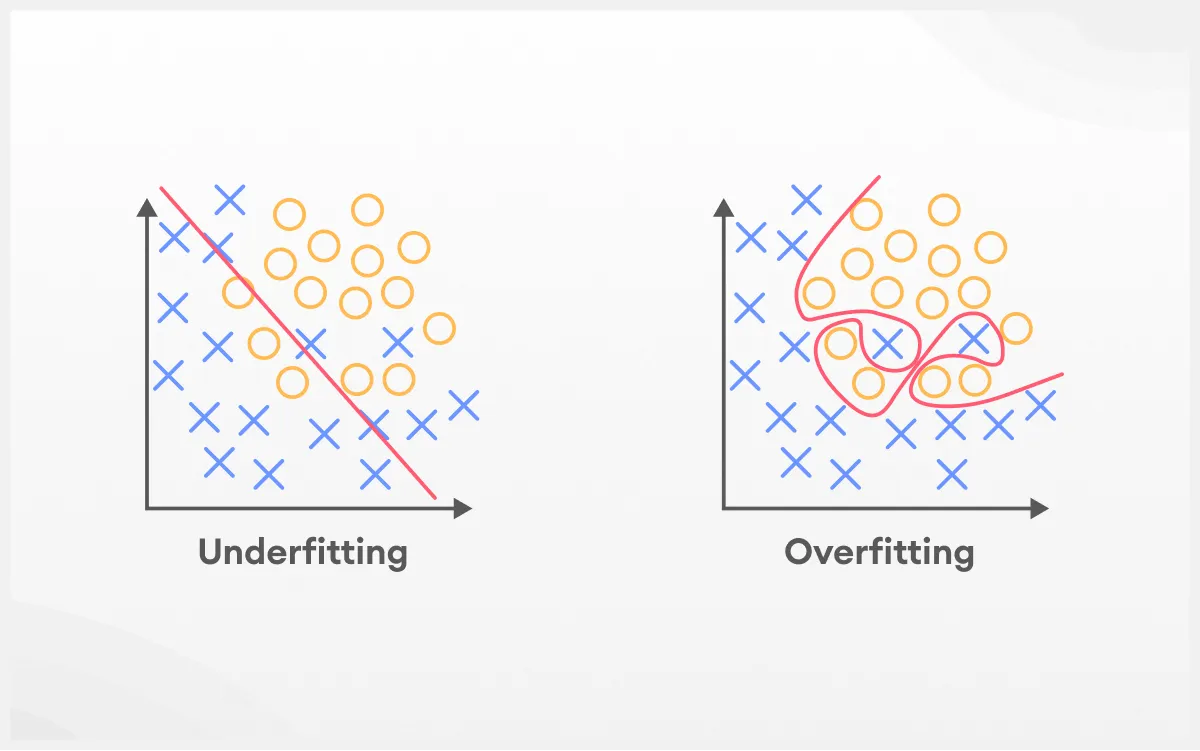
Funciona assim: o algoritmo constrói várias árvores de decisão, cada uma treinada com amostras diferentes do conjunto de dados. Além disso, a cada divisão de uma árvore, ele escolhe aleatoriamente apenas algumas variáveis para tomar a decisão. Isso ajuda a manter as árvores diversas entre si e evita que todas aprendam os mesmos padrões, o que poderia causar sobreajuste (overfitting).
Esse processo faz parte de uma técnica chamada bagging (ou bootstrap aggregating), que cria subconjuntos aleatórios dos dados com reposição. No fim, o resultado do Random Forest é a combinação das previsões de todas as árvores, gerando um modelo mais completo e confiável.
Mas vale lembrar: o Random Forest pode ser mais lento em grandes volumes de dados, já que precisa treinar e consultar várias árvores. Ainda assim, é uma das opções mais seguras quando você quer começar com um modelo que funciona bem na maioria dos casos.
Como funciona o Random Forest?
O Random Forest funciona como um time bem treinado somente de especialistas em uma determinada área: cada um dá sua opinião, e a decisão final leva em conta o que a maioria determinar. Para isso, o algoritmo passa por algumas etapas que garantem diversidade dessas opiniões dos especialistas, precisão e robustez no resultado.
1. Seleção aleatória de amostras (bagging)
Tudo começa com a criação de várias amostras aleatórias do conjunto de dados original. Essa técnica se chama bootstrap e permite repetições, ou seja, uma mesma observação pode aparecer mais de uma vez na mesma amostra. Cada uma dessas amostras será usada para treinar uma árvore de decisão diferente.
Essa diversidade de amostras é essencial porque ela faz com que cada árvore enxergue os dados de um jeito diferente, o que reduz o risco de todos cometerem os mesmos erros.
2. Construção das árvores
Durante a criação de cada árvore, o algoritmo também seleciona aleatoriamente um subconjunto de variáveis (features) a cada divisão. Isso significa que nem todas as variáveis são consideradas ao mesmo tempo, o que aumenta ainda mais a variedade entre as árvores.
O resultado são árvores mais independentes entre si, o que melhora a performance do modelo como um todo.
3. Crescimento das árvores
As árvores crescem até o fim sem poda. Isso permite que elas se tornem bem detalhadas e se adaptem melhor aos dados que receberam. Mas como o modelo vai usar várias árvores diferentes, esse excesso de detalhe em cada uma não causa problemas como o overfitting.
4. Combinação das previsões
Ao final disso tudo, depois que todas as árvores estão prontas, o Random Forest começa a fazer previsões:
- Se for um problema de classificação, cada árvore “vota” na classe que acha correta, e vence a que tiver mais votos.
- Se for um problema de regressão, o algoritmo faz a média das previsões feitas por todas as árvores.
Essa combinação baseada em votação ou média, gera um resultado final mais estável e confiável. Afinal, mesmo que algumas árvores errem, a maioria tende a acertar.
Por que usar Random Forest?
Agora, vale a pena olhar para o motivo de tanta gente usar esse algoritmo no dia a dia, de cientistas de dados a analistas de negócio.
O principal motivo?
Ele entrega resultados mais confiáveis do que uma única árvore de decisão. Isso acontece porque, ao juntar várias árvores treinadas de formas diferentes, o modelo evita se apegar demais aos dados de treino, o famoso “overfitting”, como já explicamos anteriormente. Com isso, ele consegue generalizar melhor para novos dados.
Quais são as vantagens do Random Forest?
- Alta precisão:
Na prática, ele costuma superar uma árvore de decisão sozinha em tarefas de classificação e regressão, principalmente quando os dados são complexos ou têm muitas variáveis; - Resistente a ruídos e outliers:
Mesmo que algumas árvores se confundam com valores extremos ou dados “sujos”, a maioria tende a seguir a direção correta, o que mantém a robustez do modelo; - Funciona com diferentes tipos de dados:
Você pode aplicar o Random Forest tanto com variáveis numéricas quanto categóricas. Ele se adapta bem a diferentes problemas e contextos; - Ajuda a entender os dados:
O algoritmo permite medir a importância de cada variável nas previsões. Isso ajuda a descobrir quais fatores mais influenciam o resultado, algo útil para análises mais profundas; - Pouca preparação dos dados:
Em geral, você não precisa normalizar os dados nem fazer grandes ajustes antes de treinar o modelo. Isso acelera o processo e facilita a aplicação prática.
Onde o Random Forest é usado?
A resposta curta: em quase tudo. Na prática, ele é aplicado em diversas áreas:
- Finanças: prever inadimplência, detectar fraudes;
- Saúde: identificar risco de doenças ou priorizar pacientes;
- E-commerce: prever demanda, recomendar produtos;
- Marketing: classificar leads, segmentar clientes;
- Indústria: prever falhas em equipamentos, otimizar processos.
Passo a passo para implementar o Random Forest em Python
Se você quer prever inadimplência financeira ou identificar risco de doenças, o Random Forest é uma ótima escolha. E a biblioteca scikit-learn torna tudo isso bem fácil de colocar em prática.
Abaixo, um passo a passo para você aplicar o algoritmo:
1. Importe as bibliotecas
Primeiro, você precisa importar os pacotes que vão te ajudar no carregamento dos dados, separação em treino/teste, criação do modelo e avaliação:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report2. Carregue e prepare os dados
Suponha que você tenha um arquivo CSV com seus dados. Você vai separar as features (variáveis independentes) da variável alvo (como “inadimplente” ou “risco”).
data = pd.read_csv('seus_dados.csv')
X = data.drop('target', axis=1) # Substitua 'target' pelo nome da sua coluna de saída
y = data['target']3. Divida os dados em treino e teste
Aqui, você separa os dados em duas partes: uma para treinar o modelo e outra para testá-lo.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)4. Crie o modelo
Você já pode instanciar seu Random Forest. O parâmetro n_estimators define o número de árvores na floresta.
model = RandomForestClassifier(n_estimators=100, random_state=42)5. Treine o modelo
Com os dados de treino prontos, agora é só ajustar o modelo:
model.fit(X_train, y_train)6. Faça previsões
Depois de treinado, o modelo pode prever os resultados para os dados de teste:
y_pred = model.predict(X_test)7. Avalie o desempenho
Você pode ver se o modelo está acertando as previsões usando métricas simples como acurácia e um relatório de classificação:
print("Acurácia:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))Esse roteiro funciona bem para vários problemas de classificação, como prever quem pode atrasar um pagamento ou quais pacientes têm maior risco. O segredo está em adaptar os dados corretamente e ajustar o modelo conforme seu objetivo.
Exemplo prático de uso do Random Forest
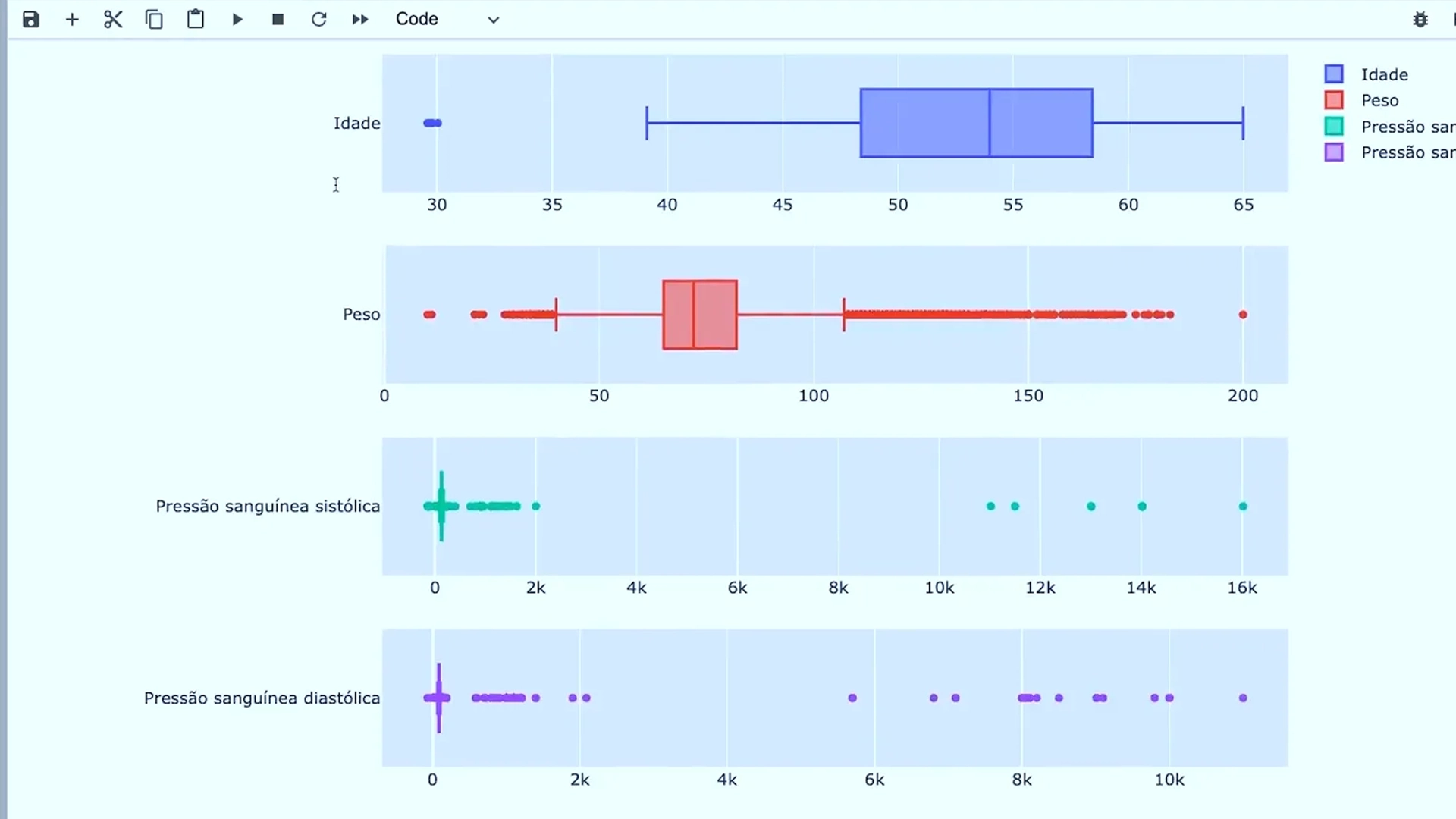
Um ótimo exemplo do uso do Random Forest na prática é o projeto que temos na nossa formação em Data Science e Machine Learning, que é o “Prevendo risco de doenças cardíacas com Machine Learning”. Nele, o algoritmo é aplicado à área da saúde com um objetivo claro: identificar pessoas com alto risco de desenvolver doenças cardíacas, usando dados clínicos e demográficos.
Como o modelo funciona?
O projeto utiliza informações como:
- Idade, gênero, altura e peso;
- Pressão sanguínea e níveis de colesterol;
- Glicose, histórico médico e hábitos (fumo, álcool, atividade física).
Esses dados alimentam o modelo Random Forest, que cria diversas árvores de decisão com subconjuntos aleatórios dessas variáveis. Cada árvore faz sua previsão, e o modelo final combina todas elas para chegar a um resultado mais confiável e preciso. Ou seja, se a pessoa tem ou não o risco de desenvolver doenças cardíacas.
4 Desafios e limitações do Random Forest
Apesar de ser um dos algoritmos mais populares e confiáveis, o Random Forest tem algumas limitações que merecem atenção, principalmente quando se trabalha com muitos dados ou precisa de explicações claras sobre as decisões do modelo.
Vamos aos principais pontos negativos do Random Forest:
1. Complexidade computacional
Como o modelo constrói várias árvores de decisão, o processo pode ser pesado tanto na hora de treinar quanto ao fazer previsões. Isso significa maior uso de memória e mais tempo de processamento, especialmente em bases de dados grandes ou com muitas variáveis.
Em projetos mais simples, esse tempo extra pode ser desnecessário. E em ambientes com pouca capacidade computacional (como sistemas embarcados ou notebooks mais fracos), pode até inviabilizar o uso.
2. Baixa interpretabilidade
Diferentemente de uma única árvore de decisão, que você pode “ler” como um fluxograma, o Random Forest toma decisões com base em centenas de árvores. Isso dificulta entender exatamente por que o modelo chegou a determinada conclusão.
É possível saber quais variáveis mais influenciam a decisão (feature importance), mas não exatamente como elas interagem. Para aplicações que exigem explicações claras, como saúde ou decisões financeiras, essa falta de transparência pode ser um problema.
3. Viés em variáveis com muitos valores únicos
O algoritmo pode dar importância exagerada a variáveis que têm muitos valores distintos, mesmo que elas não sejam tão úteis assim.
Um exemplo clássico:
Se você usa o Random Forest para prever inadimplência e inclui a variável “ID do cliente” (única para cada pessoa), o modelo pode achar que ela é super-relevante só porque é diferente para cada caso. Mas, na prática, isso não ajuda em nada na previsão.
4. Dados muito ruidosos ou desbalanceados
Mesmo sendo robusto, o Random Forest não faz milagres com dados ruins. Se o conjunto está cheio de outliers, valores ausentes ou classes muito desproporcionais, o desempenho pode cair.
Existem formas de contornar isso, como balancear os dados ou ajustar hiperparâmetros, mas é bom saber que o modelo também tem suas limitações.
Comece agora a dominar o Random Forest com nossa trilha!
Se você deseja continuar sua jornada no aprendizado de Machine Learning, está na hora de dar o próximo passo.
A Trilha Data Science & Machine Learning da Asimov Academy é o caminho ideal para quem quer dominar Python, explorar dados, desenvolver modelos preditivos e extrair insights valiosos com projetos reais, como o que utiliza o Random Forest para prever doenças cardíacas.
Explore dados, crie modelos e impulsione a tomada de decisões com confiança.

Trilha Data Science e Machine Learning
Explore dados, desenvolva modelos preditivos e extraia insights valiosos para impulsionar a tomada de decisões.
Comece agoraVocê também pode gostar:






Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp