

Precisa criar modelos de machine learning de maneira descomplicada e eficiente, mas não sabe como? Então o Scikit-learn pode ser exatamente o que você está procurando.
Neste artigo, vamos mergulhar no que torna o Scikit-learn tão especial: por que ele é a escolha de tantos profissionais, como ele facilita sua jornada e, claro, o passo a passo para começar a usá-lo. Afinal, descomplicar o complexo é o primeiro passo para transformar ideias em soluções reais, e o Scikit-learn vai te surpreender!
O que é a biblioteca Scikit-learn?
Scikit-learn, também conhecido como Sklearn, é uma biblioteca de código aberto para a linguagem de programação Python, desenvolvida especificamente para facilitar a implementação de algoritmos de machine learning. Ela oferece uma ampla gama de ferramentas e funcionalidades que permitem realizar tarefas como classificação, regressão, clusterização e pré-processamento de dados.
O que faz do Scikit-learn uma escolha tão popular?
Primeiro, ele é construído sobre pilares sólidos, como NumPy, SciPy e Matplotlib, que garantem eficiência e robustez. Depois, ele oferece uma interface superamigável, sendo possível até mesmo para quem está dando os primeiros passos criar modelos para classificação, regressão, clusterização e muito mais.
E a cereja do bolo? A comunidade ativa e a documentação rica tornam tudo mais fácil, desde tirar dúvidas até compartilhar ideias.
Seja para análise preditiva ou para criar um modelo incrível de machine learning, o Scikit-learn é prático, acessível (afinal, é de código aberto) e funciona em diversas situações. Com ele, o Python prova mais uma vez por que é a linguagem queridinha do momento: suas bibliotecas, como NumPy, Pandas e Sklearn, entregam simplicidade e eficiência para resolver problemas complexos sem complicar sua vida.
A importância do Scikit-learn no campo do machine learning não pode ser subestimada. Ele se tornou uma das bibliotecas mais utilizadas devido à sua simplicidade e eficiência. Com uma interface amigável, mesmo iniciantes podem começar a criar modelos de machine learning sem a necessidade de um conhecimento técnico profundo.
Por que usar Scikit-learn?

Se você está se perguntando por que escolher o Scikit-learn para seus projetos de machine learning, a resposta está em sua combinação única de simplicidade e eficiência. Ele não só facilita a vida de quem está começando, mas também é uma ferramenta poderosa para profissionais mais experientes.
A primeira coisa que chama atenção no Scikit-learn é sua facilidade de uso. A API é tão intuitiva que você consegue focar no que realmente importa: a lógica do modelo. Nada de se perder em detalhes técnicos desnecessários. Você sente que está no controle desde o início.
Outro ponto forte é a versatilidade. O Scikit-learn cobre uma enorme variedade de algoritmos e técnicas, como classificação, regressão, clusterização e até redução de dimensionalidade. Isso significa que, qualquer que seja seu objetivo, ele provavelmente tem a solução pronta para você.
E tem mais: ele se integra perfeitamente com outras bibliotecas que você já conhece e ama, como Pandas e Matplotlib. Isso torna o processo de manipulação e visualização de dados muito mais fluido e simples. Tudo conversa bem, sem dores de cabeça.
Comparação com outras bibliotecas
Agora, se você está pensando em alternativas como TensorFlow ou PyTorch, é bom saber que o Scikit-learn tem um foco diferente. Enquanto essas bibliotecas são ótimas para deep learning e redes neurais, o Scikit-learn se destaca nos algoritmos clássicos de machine learning. Ele é perfeito para quem quer dominar os fundamentos e entender como tudo funciona por trás das cenas, antes de dar passos maiores.
No final das contas, o Scikit-learn é como aquele amigo que está sempre pronto para ajudar: simples, confiável e sempre lá para facilitar sua jornada no machine learning.
Principais recursos do Scikit-learn
O Scikit-learn é aquele tipo de ferramenta que te faz pensar: “Por que eu não conhecia isso antes?”. Ele vem cheio de soluções práticas para quem precisa descomplicar tarefas de machine learning. Vamos dar uma olhada nos recursos que realmente fazem a diferença:
Classificação: o que é e como funciona?
Começando pela classificação, que é uma das tarefas mais comuns em machine learning, em que o objetivo é prever a categoria à qual um determinado dado pertence. Por exemplo, podemos usar a classificação para determinar se um e-mail é spam ou não. Com o Scikit-learn, você tem algoritmos como regressão logística, árvores de decisão e K-Nearest Neighbors (KNN), prontos para te ajudar a resolver isso com rapidez e precisão.
Regressão: como prever valores contínuos?
A regressão é outra tarefa fundamental em machine learning, utilizada para prever valores contínuos. Por exemplo, podemos prever o preço de uma casa com base em suas características, como tamanho e localização. O Scikit-learn possui implementações de algoritmos de regressão, como Regressão Linear e Regressão de Ridge, que transformam até os cálculos mais chatos em algo direto e funcional.
Clusterização: agrupando dados semelhantes
A clusterização é como organizar uma gaveta bagunçada. Ela agrupa dados parecidos, o que pode ser útil, pois essa técnica permite agrupar dados semelhantes em conjuntos. Por exemplo, podemos usar a clusterização para segmentar clientes com base em seu comportamento de compra. O Scikit-learn oferece algoritmos como K-Means e DBSCAN para realizar essa tarefa de forma eficiente.
Redução de dimensionalidade: simplificando dados complexos
Quando os dados têm muitas variáveis, pode ficar difícil trabalhar com eles. A redução de dimensionalidade é uma técnica que ajuda a simplificar conjuntos de dados complexos, mantendo suas características mais importantes. Isso é particularmente útil quando lidamos com dados de alta dimensionalidade. O Scikit-learn implementa técnicas como análise de componentes principais (PCA) para facilitar essa tarefa.
Pré-processamento de dados: preparando dados para análise
Antes de aplicar qualquer algoritmo de machine learning, é fundamental preparar os dados. O Scikit-learn oferece várias ferramentas para pré-processamento, como normalização, padronização e tratamento de valores ausentes, garantindo que os dados estejam prontos para análise. É como arrumar a casa antes de receber as visitas, tudo fica em ordem para o próximo passo. Ou seja, receber a vista.
Com esses recursos, o Scikit-learn garante que você tenha tudo o que precisa para criar modelos poderosos e resolver problemas complexos, sem complicar a sua vida.
Como instalar o Scikit-learn: passo a passo sem complicação
Instalar o Scikit-learn é mais fácil do que parece, e você tem várias formas de fazer isso, dependendo do seu ambiente ou preferência. Aqui estão as opções mais comuns para você começar:
1. Usando o pip (o jeito mais direto)
Se você quer algo rápido e eficiente, o pip é o caminho.
Antes de começar:
Confirme se sua versão do Python é 3.6 ou superior (requisito mínimo). Para isso, você precisa rodar o seguinte comando:
python3 --version Instalando o Scikit-learn:
Se tudo estiver certo com o Python, use este comando:
pip install scikit-learn Dica extra:
É sempre uma boa ideia criar um ambiente virtual para evitar bagunça com outras bibliotecas. Faça assim:
python -m venv sklearn-env
source sklearn-env/bin/activate # No Windows, use: sklearn-env\Scripts\activate
pip install -U scikit-learn 2. Usando Conda (ideal para quem usa Anaconda)
Se você já está no sistema do Anaconda, o Conda facilita bastante. Para isso, você precisa fornecer o seguinte comando:
conda install scikit-learn Quer criar um ambiente específico para o Scikit-learn? Experimente isto:
conda create -n sklearn-env -c conda-forge scikit-learn
conda activate sklearn-env 3. Instalando direto do código-fonte
Se você gosta de personalização ou quer a versão mais recente, dá para compilar o Scikit-learn direto do código-fonte. Mas atenção: você vai precisar de algumas dependências, como um compilador C/C++. As instruções detalhadas estão na documentação oficial.
4. Verificando se deu tudo certo
Depois de instalar, vale a pena conferir se está tudo funcionando como esperado. Use estes comandos:
python -m pip show scikit-learn # Mostra informações sobre a instalação
python -c "import sklearn; sklearn.show_versions()" # Detalha a versão instalada Exemplos práticos de uso do Scikit-learn
1. Criando um modelo de classificação com o conjunto de dados Iris
O famoso conjunto de dados Iris é um clássico para começar a trabalhar com classificação. Ele contém informações sobre diferentes espécies de flores e é um ótimo ponto de partida para aprender técnicas de classificação.
Carregando e explorando o conjunto de dados
Primeiro, vamos carregar o conjunto de dados Iris para analisar as informações que ele contém:
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.DESCR)Este código vai carregar os dados e exibir uma descrição das características das flores, como o comprimento e a largura das pétalas e sépalas, além das classes (espécies).
Dividindo os dados em conjuntos de treinamento e teste
Agora, vamos dividir os dados em dois conjuntos: um para treinar o modelo e outro para testar a precisão depois.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)Aqui, estamos usando 80% dos dados para treinamento e 20% para testes, o que é uma boa prática para evitar sobreajuste.
Treinando o modelo de classificação
Agora é a hora de criar e treinar o nosso modelo. Vamos usar a Regressão Logística, que é um dos algoritmos mais comuns para problemas de classificação:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)Esse código cria o modelo e o treina com os dados de treinamento.
Avaliando a precisão do modelo
Agora que treinamos o modelo, vamos ver como ele se sai no conjunto de teste:
accuracy = model.score(X_test, y_test)
print("Acurácia do modelo:", accuracy)Esse código vai calcular a precisão do modelo, ou seja, o quão bem ele classificou as flores no conjunto de teste.
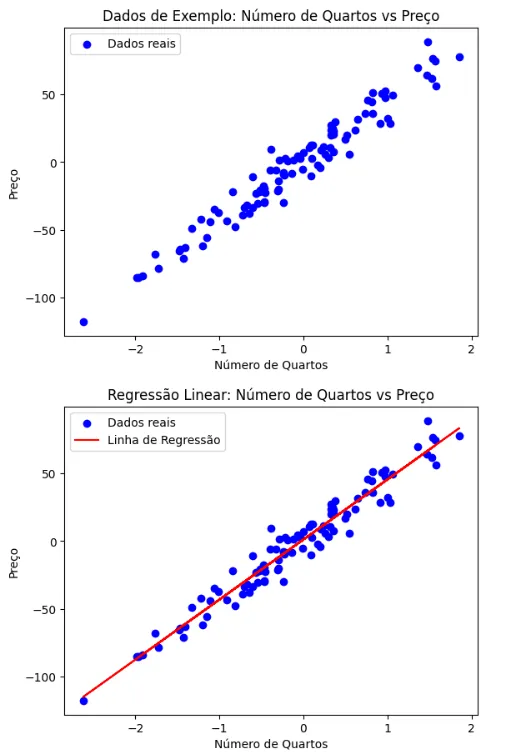
2. Criando um modelo de regressão linear
Agora vamos aprender como usar o Scikit-learn para prever valores contínuos com regressão linear.
Gerando dados de exemplo
Para começar, vamos gerar alguns dados de exemplo. Imagine que queremos prever o preço de uma casa com base no número de quartos. Vamos gerar estes dados:
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=1, noise=10)Esse código cria um conjunto de dados com 100 amostras e uma variável preditora (número de quartos), com um pouco de ruído para deixar a simulação mais realista.
Treinando e avaliando o modelo de regressão linear
Agora, vamos treinar o modelo de regressão linear e ver como ele faz previsões:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X, y)
predictions = model.predict(X)Aqui, criamos e treinamos o modelo de regressão linear e depois usamos o modelo para prever os valores de y (preço da casa).
3. Exemplo prático de agrupamento com K-Means
No exemplo a seguir, será demonstrado como o K-Means pode ser aplicado para identificar clusters em um conjunto de dados sintético gerado aleatoriamente. Utilizando a função make_blobs, geraremos um conjunto de dados com 300 amostras distribuídas em 4 clusters. Em seguida, aplicaremos o algoritmo de K-Means para detectar esses grupos e visualizá-los em um gráfico de dispersão, destacando os centros dos clusters em vermelho.
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt # Importando o módulo necessário para visualização
# Gerando dados para agrupamento
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# Aplicando K-Means
kmeans = KMeans(n_clusters=4)
y_kmeans = kmeans.fit_predict(X)
# Visualizando os resultados do agrupamento
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.title('Agrupamento com K-Means')
plt.show()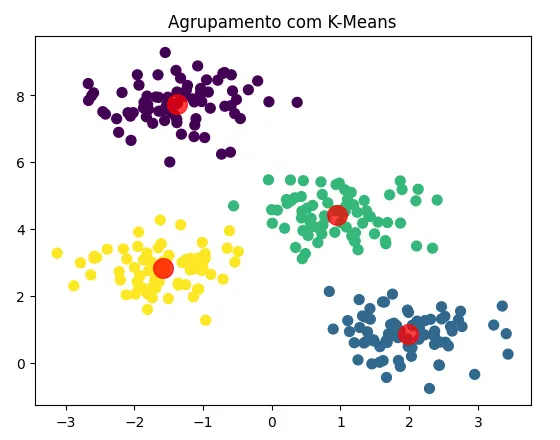
Pronto para dar o próximo passo em Machine Learning?
Agora que você já conhece o poder do Scikit-learn e suas aplicações em classificação, regressão e clusterização, que tal aprofundar seus conhecimentos ainda mais? A Asimov oferece a Trilha Data Science & Machine Learning, na qual você aprende diretamente com exemplos práticos usando o Scikit-learn, explorando todos os conceitos essenciais para se tornar um expert em machine learning.
Venha fazer parte da Asimov Academy e dê um grande passo na sua carreira de Data Science!
Você também pode gostar:









Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xpTo na trilha de iniciante ainda mas já tinha ouvido falar nesta biblioteca Scikit-learn. Acredito que devo primeiro acabar de fazer a minha trilha de introdução a Python e aí sim, depois de mais algumas trilhas me aprofundar. O que acha Rebeca?
Bom dia, Bruno! Tudo certo?
Você pode fazer as duas sem problemas, mas é altamente recomendado conhecer a base do Python para ter menos dificuldades ao aprender essa biblioteca. Se você já se sente um pouco confortável ao resolver alguns problemas em Python, já pode iniciar aprendendo Scikit-learn.
Caso ainda estiver com dúvidas, estou à disposição. Abs!