

Você já se perguntou como as empresas conseguem prever o comportamento dos clientes ou como os médicos identificam o risco de doenças? Isso pode parecer mágica, mas é tudo feito com dados e uma técnica chamada regressão logística. Mesmo que o nome pareça um pouco complicado, o conceito é bem simples: ela ajuda a calcular a probabilidade de algo acontecer. Em vez de simplesmente estimar, a regressão logística transforma números em previsões precisas.
Neste texto, vamos desvendar como ela funciona, por que é tão diferente da regressão linear e como ela tem sido aplicada em áreas como marketing, saúde e finanças para facilitar decisões mais precisas.
O que é regressão logística?
A regressão logística pode parecer um nome complicado, mas a ideia por trás dela é bem simples: prever a probabilidade de algo acontecer. Pense em situações do dia a dia, como tentar descobrir se um cliente vai fazer uma compra ou não, com base no comportamento dele. A regressão logística faz exatamente isso, ela usa dados para prever respostas categóricas, como “sim” ou “não”, “verdadeiro” ou “falso”.
Essa técnica é muito usada em análises preditivas e classificações. E o mais interessante: o resultado dela é sempre uma probabilidade, um número entre 0 e 1. Por trás dos cálculos, ela utiliza uma transformação chamada logit, que nada mais é do que uma forma de relacionar as chances de algo dar certo (sucesso) com as chances de não dar (fracasso). A fórmula básica dessa transformação é:
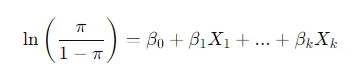
Aqui, π representa a probabilidade de sucesso, e os βs são os coeficientes que o modelo ajusta com base nos dados. Esses valores são encontrados usando um método chamado máxima verossimilhança, que tenta otimizar o modelo para se ajustar o melhor possível aos dados fornecidos.
Depois de ajustado, o modelo classifica os resultados: se a probabilidade for menor que 0,5, o resultado será 0 (por exemplo, “não”); se for maior, será 1 (por exemplo, “sim”).
Por fim, é importante testar como o modelo se sai ao prever os resultados. Um método comum para avaliar isso é o teste de Hosmer-Lemeshow, que verifica se o modelo está realmente representando bem os dados.
Diferença entre regressão logística e regressão linear
A regressão linear e a regressão logística são duas técnicas estatísticas amplamente usadas para modelar relações entre variáveis. A diferença principal entre elas está no tipo de problema que resolvem. Usamos a regressão linear para prever valores que variam de forma ininterrupta dentro de um intervalo, como peso, altura, temperatura ou o preço de um imóvel. Já a regressão logística serve para resolver problemas de classificação, como identificar se um cliente comprará ou não um produto.
A regressão linear é ideal para quando o objetivo é prever uma variável dependente que assume valores dentro de uma escala contínua. Por exemplo, ao estimar o preço de um imóvel, a fórmula básica da regressão linear é representada como:
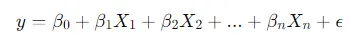
Nessa fórmula, y é a variável que queremos prever, X representa as variáveis independentes (como número de quartos ou localização), β são os coeficientes que determinam a importância de cada variável, e ϵ é o erro do modelo.
Já a regressão logística é utilizada para prever resultados categóricos, como sim ou não, verdadeiro ou falso. Nesse caso, em vez de prever um número contínuo, ela calcula uma probabilidade entre 0 e 1. A fórmula da regressão logística inclui uma transformação sigmoide que ajusta os valores para esse intervalo:
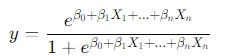
Exemplos de aplicação
Por exemplo, podemos usar a regressão logística para estimar a probabilidade de um imóvel custar mais de R$ 500 mil, baseando-se em características como bairro e número de quartos.
Embora ambas analisem a relação entre variáveis independentes e dependentes, elas produzem saídas diferentes. A regressão linear modela a relação como uma linha reta, enquanto a regressão logística representa essa relação com uma curva sigmoide.
Um ponto em comum é que ambas fazem parte do aprendizado supervisionado no machine learning, onde os dados usados para treinamento já vêm rotulados. Além disso, tanto a regressão linear quanto a logística exigem conjuntos de dados robustos para treinar modelos eficazes e lidar com desafios como o overfitting ou subestimação de variáveis importantes.
Outro aspecto essencial é o tipo de distribuição estatística usada. A regressão linear presume que os dados seguem uma distribuição normal (ou gaussiana), enquanto a regressão logística utiliza a distribuição binomial, especialmente útil para problemas de classificação.
Para facilitar a aplicação prática, considere um exemplo de regressão linear: prever o preço da gasolina no Brasil com base no local, data e preços anteriores.
Para que serve a regressão logística?
A regressão logística é uma técnica estatística muito utilizada para resolver problemas de classificação, nos quais o objetivo é prever uma probabilidade categórica, como “sim” ou “não”. Por meio dessa abordagem, é possível calcular a chance de um evento específico ocorrer com base em um conjunto de variáveis independentes.
Sua versatilidade a torna uma ferramenta poderosa em diversos setores, como marketing, saúde e finanças, oferecendo insights que auxiliam na tomada de decisões estratégicas.
Aplicações práticas em diferentes setores
Marketing
No mundo do marketing, a regressão logística desempenha um papel crucial na personalização de campanhas. Por exemplo, empresas podem prever se um usuário clicará em um anúncio com base em dados como histórico de navegação, idade e localização. Esses insights ajudam a otimizar as campanhas publicitárias, aumentando a taxa de conversão e reduzindo custos.
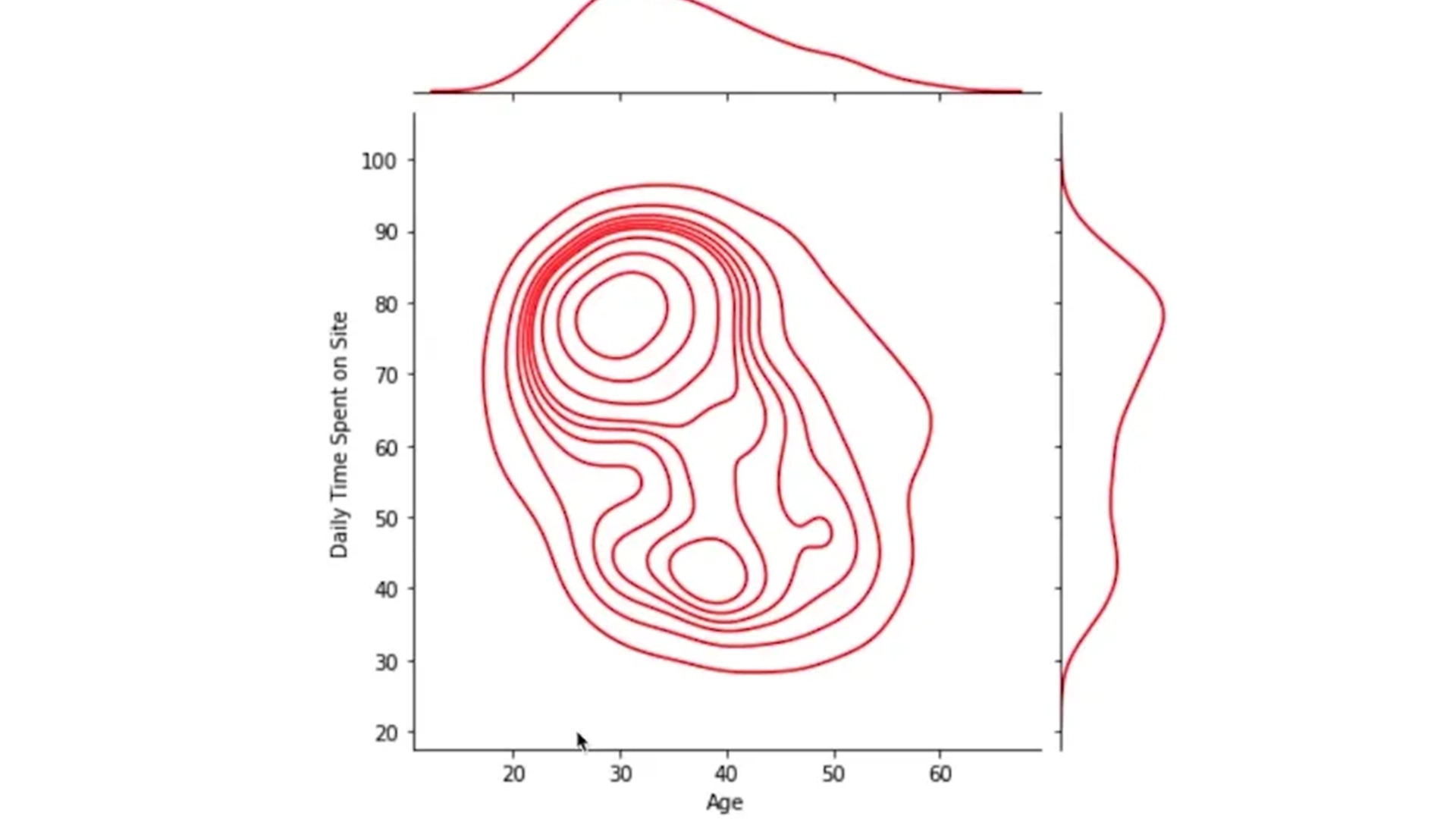
Regressão Logística em dados de publicidade
Saúde
Na medicina, a regressão logística é frequentemente usada para prever a probabilidade de um paciente desenvolver uma doença. Por exemplo, ao analisar fatores como histórico familiar, hábitos de vida e exames laboratoriais, médicos podem identificar grupos de risco e atuar de forma preventiva. Isso torna a regressão logística uma ferramenta essencial para melhorar diagnósticos e planejar tratamentos.
Prevendo risco de doenças cardíacas com Machine Learning
Finanças
Instituições financeiras utilizam a regressão logística para avaliar o risco de crédito. Com base em variáveis como histórico de pagamento, renda e endividamento, é possível prever se um cliente será um bom ou mau pagador. Essa aplicação contribui para decisões mais certeiras na concessão de crédito, ajudando a minimizar prejuízos e otimizar carteiras de investimentos.
Análise de ações com Machine Learning
Como funciona a regressão logística?
A regressão logística é fundamentada na função logit, que transforma probabilidades em uma escala linear, facilitando a análise e previsão de eventos categóricos. Embora seja uma técnica avançada, sua essência pode ser compreendida em etapas claras.
A matemática por trás da regressão logística
A equação básica da regressão logística é:
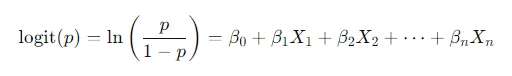
Onde:
- p é a probabilidade do evento ocorrer;
- β0 é o intercepto, que representa o valor base quando todas as variáveis independentes (X) são zero;
- β1,β2,…,βn são os coeficientes que indicam o impacto de cada variável independente (X1,X2,…,Xn) na probabilidade do evento.
A função logit, transforma a probabilidade ppp em uma escala linear. Isso permite que os modelos de regressão logística representem relações complexas entre variáveis e probabilidades de maneira mais clara e precisa.
Como interpretar os resultados
Depois de calcular os coeficientes (β), os resultados são geralmente interpretados através da razão de chances (odds ratio). A razão de chances é uma métrica que indica o impacto relativo de uma variável no aumento ou redução da probabilidade de um evento.
- Razão de chances maior que 1: o fator analisado aumenta a probabilidade do evento ocorrer;
- Razão de chances igual a 1: o fator não tem efeito sobre a probabilidade;
- Razão de chances menor que 1: o fator reduz a probabilidade do evento ocorrer.
Por exemplo, em um modelo de saúde que avalia a relação entre tabagismo e doenças cardíacas, um odds ratio de 2 para o tabagismo significa que fumantes têm o dobro de chances de desenvolver doenças cardíacas em comparação com não fumantes, considerando outras variáveis constantes.
Tipos de regressão logística
A regressão logística é uma técnica estatística, com aplicações que variam conforme o tipo de resposta categórica analisada. Existem três tipos principais: binária, multinomial e ordinal. Cada um deles resolve problemas específicos em diferentes contextos.
Regressão logística binária
A regressão logística binária é a mais comum, aplicada quando a variável dependente possui dois resultados possíveis, como “sim” ou “não”. Por exemplo, é usada para prever se um e-mail é spam ou não ou se um tumor é maligno ou benigno.
Essa abordagem é comumente empregada em problemas de classificação binária, sendo eficiente para decisões dicotômicas.
Regressão logística multinomial
Já a regressão logística multinomial é usada quando a variável dependente tem três ou mais categorias, sem uma ordem específica. Um exemplo prático seria prever o gênero de filme que um espectador prefere com base em fatores como idade e estado civil.
Esse tipo de regressão permite identificar padrões de escolha entre múltiplas opções, ajudando em estratégias como campanhas de marketing direcionadas.
Regressão logística ordinal
Por outro lado, aplica-se a regressão logística ordinal quando a variável dependente possui categorias ordenadas. Aqui, as respostas seguem uma hierarquia, como notas de A a F ou escalas de satisfação de 1 a 5.
Esse modelo é útil para interpretar relações em contextos cujos resultados têm uma progressão lógica.
Implementando a regressão logística em Python
Utiliza-se a regressão logística para resolver problemas de classificação e, com o suporte de bibliotecas do Python, implementamos essa técnica de forma prática e eficiente. Abaixo, apresentamos um passo a passo para criar um modelo de regressão logística utilizando a biblioteca scikit-learn.
Passo 1: importar as bibliotecas necessárias
Primeiro, importe os pacotes essenciais para manipulação de dados, criação do modelo e avaliação de desempenho.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_scorePasso 2: carregar os dados
Utilize o Pandas para carregar seu conjunto de dados, seja de um arquivo CSV, seja de outra fonte.
data = pd.read_csv('seus_dados.csv')Passo 3: preparar os dados
Selecione a variável dependente (alvo) e as variáveis independentes (preditoras).
X = data[['variavel_independente']]
y = data['variavel_dependente']Passo 4: dividir os dados em treino e teste
Divida os dados em conjuntos de treino e teste para avaliar o desempenho do modelo.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Passo 5: criar o modelo de regressão logística
Crie e treine o modelo com os dados de treino.
model = LogisticRegression()
model.fit(X_train, y_train)Passo 6: fazer previsões
Use o modelo treinado para prever os resultados no conjunto de teste.
predictions = model.predict(X_test)Passo 7: avaliar o modelo
Meça a precisão do modelo para verificar sua eficácia.
accuracy = accuracy_score(y_test, predictions)
print(f'Acurácia do modelo: {accuracy}')Esse processo básico é suficiente para construir um modelo funcional. Você pode expandir sua análise adicionando técnicas de pré-processamento, validação cruzada ou ajuste de hiperparâmetros para melhorar o desempenho.
Exemplo prático: previsão de resultados com dados fictícios
Para tornar mais claro o uso da regressão logística, vamos implementar um exemplo em que o objetivo é prever se um cliente fará uma compra com base no tempo que ele passa navegando no site.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Dados fictícios
data = pd.DataFrame({
'tempo_navegacao': [5, 10, 15, 20, 25, 30, 35, 40, 45, 50],
'compra': [0, 0, 1, 1, 1, 0, 0, 1, 0, 1] # 0 = não comprou, 1 = comprou
})
# Preparar os dados
X = data[['tempo_navegacao']]
y = data['compra']
# Dividir os dados em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Criar o modelo de regressão logística
model = LogisticRegression()
model.fit(X_train, y_train)
# Fazer previsões
predictions = model.predict(X_test)
# Avaliar o modelo
accuracy = accuracy_score(y_test, predictions)
print(f'Acurácia do modelo: {accuracy}')Resultado esperado
- Treinamento do modelo: com base nos dados fictícios fornecidos, ensinando-o a identificar a relação entre o tempo de navegação e a probabilidade de compra.
- Previsão: o modelo prediz se um cliente comprará com base no tempo de navegação nos dados de teste;
- Acurácia: a avaliação do modelo exibe a precisão, indicando quão bem ele prevê os resultados nos dados de teste.
Comparação entre regressão logística e outras técnicas de machine learning
A regressão logística é uma técnica fundamental em machine learning, especialmente para problemas de classificação binária. No entanto, há várias outras técnicas que podem ser comparadas com ela, cada uma com suas próprias características, vantagens e desvantagens. Abaixo estão as comparações com outras técnicas populares de machine learning.
1. Regressão linear
A regressão linear modela a relação entre variáveis dependentes e independentes usando uma combinação linear. É usada para prever valores contínuos, como preços ou quantidades.
- Vantagens:
- Fácil de entender e interpretar;
- Eficiente em termos computacionais para dados lineares.
- Desvantagens:
- Assume uma relação linear entre as variáveis, o que pode ser limitante quando as variáveis têm uma relação não linear.
2. Deep learning
O deep learning, ou aprendizado profundo, utiliza redes neurais complexas para analisar grandes volumes de dados. É utilizado em tarefas como reconhecimento de imagem e processamento de linguagem natural.
- Vantagens:
- Capacidade de capturar padrões complexos em grandes conjuntos de dados;
- Flexível e adaptável a diferentes tipos de dados.
- Desvantagens:
- Requer maiores recursos computacionais e tempo para treinamento;
- Menos interpretável do que a regressão logística, o que dificulta a análise dos resultados.
3. Random Forest
Random Forest é um algoritmo de Ensemble que utiliza múltiplas árvores de decisão para melhorar a precisão das previsões. É eficaz em problemas de classificação e regressão.
- Vantagens:
- Robusto contra o overfitting, pois a média das previsões de várias árvores diminui o impacto de variabilidade;
- Capacidade de lidar com grandes conjuntos de dados com alta dimensionalidade.
- Desvantagens:
- Menos interpretável do que a regressão logística;
- O tempo de treinamento pode ser maior devido à construção de várias árvores de decisão.
4. Máquinas de vetores de suporte (SVM)
As Máquinas de Vetores de Suporte (SVM) são usadas para problemas de classificação, criando uma linha ou um hiperplano de separação entre diferentes classes.
- Vantagens:
- Eficaz em espaços de alta dimensionalidade e com margens de separação não lineares;
- Bem-sucedida em tarefas binárias com grandes margens de separação.
- Desvantagens:
- O desempenho pode ser afetado com conjuntos de dados grandes, devido ao alto custo computacional;
- Menos intuitiva e interpretável do que a regressão logística, especialmente em configurações não lineares.
Aprofunde seus conhecimentos em data science e machine learning
Neste guia, você aprendeu sobre a regressão logística, suas aplicações, como funciona a matemática por trás dela e como implementá-la em Python. Essa técnica é fundamental na ciência de dados e pode ser aplicada em diversos setores, desde marketing até saúde.
Se você deseja aprofundar seus conhecimentos na área, convidamos você a conhecer a Trilha de Data Science e Machine Learning, da Asimov Academy. A trilha é ideal para quem deseja se tornar um cientista de dados. Comece do zero com nossos cursos introdutórios e siga para os cursos avançados de machine learning, adquirindo todo o conhecimento necessário em matemática e estatística ao longo do caminho. Tudo isso com a didática clara e concisa da Asimov.

Data Science & Machine Learning
Você também pode gostar:









Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp