
Leia também:
O Beautiful Soup é uma biblioteca Python que facilita a tarefa de web scraping, ou seja, a extração de dados de páginas da web. Com ela, é possível navegar pela estrutura de um documento HTML ou XML e extrair as informações desejadas de forma eficiente. Neste tutorial, vamos explorar como utilizar o Beautiful Soup em três exemplos práticos de projetos de web scraping.
Antes de mergulharmos nos exemplos, é importante entender o básico sobre a biblioteca Beautiful Soup. Ela funciona analisando o código HTML de uma página e criando um objeto que representa o documento como uma estrutura de dados. A partir desse objeto, podemos buscar e manipular elementos da página de maneira simples e intuitiva.
Para começar a usar o Beautiful Soup, você precisa instalá-lo. Isso pode ser feito através do pip, o gerenciador de pacotes do Python:
pip install beautifulsoup4Além disso, você também precisará da biblioteca padrão requests para fazer as requisições HTTP às páginas que deseja raspar.
Vamos começar com um exemplo simples: extrair os títulos das principais notícias do site globo.com.
import requests
from bs4 import BeautifulSoup
# Fazendo a requisição para a página de notícias
url = 'https://www.globo.com/'
response = requests.get(url)
html = response.text
# Criando o objeto Beautiful Soup
soup = BeautifulSoup(html, 'html.parser')
# Buscando todos os elementos que contêm os títulos das notícias
titulos = soup.find_all('h2', class_='post__title')
# Extraindo e imprimindo os títulos
for titulo in titulos:
print(titulo.text.strip())Neste exemplo, utilizamos o método find_all para buscar todos os elementos h2 que possuem a classe titulo-noticia, que é onde os títulos das notícias estão contidos. A busca foi realizada após a inspeção da página, conforme mostrado na imagem.
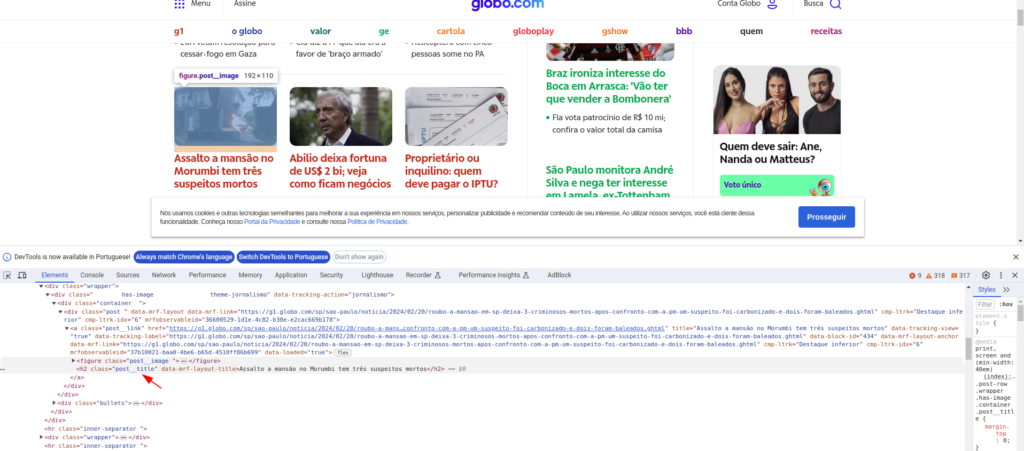
Agora, vamos a um exemplo um pouco mais complexo: capturar os preços de produtos em uma página de e-commerce.
import requests
from bs4 import BeautifulSoup
# Fazendo a requisição para a página de produtos
url = 'https://lista.mercadolivre.com.br/pcs#D[A:pcs]'
response = requests.get(url)
html = response.text
# Criando o objeto Beautiful Soup
soup = BeautifulSoup(html, 'html.parser')
# Buscando todos os elementos que contêm os preços dos produtos
precos = soup.find_all('span', class_='andes-money-amount__fraction')
# Extraindo e imprimindo os preços
for preco in precos:
print(preco.text.strip())Neste caso, o método find_all é usado para buscar todos os elementos span com a classe andes-money-amount__fraction, que identifica os preços listados. A busca foi realizada após a inspeção da página, conforme mostrado na imagem.
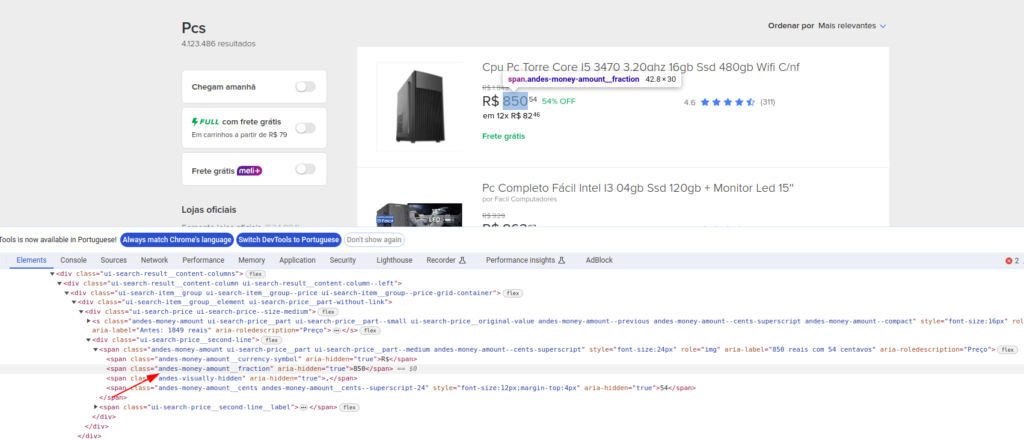
Por fim, vamos ver como coletar todos os links presentes da página de tutoriais do Python.org.
import requests
from bs4 import BeautifulSoup
# Fazendo a requisição para a página
url = 'https://docs.python.org/3/tutorial/index.html'
response = requests.get(url)
html = response.text
# Criando o objeto Beautiful Soup
soup = BeautifulSoup(html, 'html.parser')
# Buscando todos os elementos 'a', que representam links
links = soup.find_all('a')
# Extraindo e imprimindo os atributos 'href' de cada link
for link in links:
href = link.get('href')
if href:
print(href)Aqui, o método find_all é utilizado para buscar todos os elementos a, que são os links. Em seguida, extraímos o atributo href, que contém o URL do link.
O Beautiful Soup é uma ferramenta poderosa e flexível para web scraping. Com ela, é possível realizar desde tarefas simples, como extrair títulos de notícias, até tarefas mais complexas, como capturar preços de produtos ou coletar links de uma página. Esperamos que este tutorial tenha ajudado a entender melhor como utilizar essa biblioteca e que os exemplos práticos sirvam de inspiração para seus próprios projetos de web scraping.
Aprenda sobre variáveis, loops e funções e crie seu primeiro projeto Python em apenas 2 horas!
Saia do zero e analise dados com Python e Pandas neste curso gratuito com certificado!
Aprenda a programar com Python e explore a inteligência artificial! Crie um chatbot prático que interage com seus próprios dados. Comece agora!
Estudo aprofundado do potencial de LLMs multimodais: soluções, mecanismos e geração de valor Os Modelos de Linguagem de Grande Porte (LLMs) multimodais representam uma…
Quando se trata de visualização de dados em Python, o Matplotlib é uma das bibliotecas mais populares e poderosas disponíveis. Para cientistas de dados,…
Ter um portfólio online é essencial para se destacar no mercado. Se você atua na área de dados, tecnologia ou negócios, apresentar seus projetos…
Comente e participe da conversa
Crie sua conta gratuita e compartilhe sua opinião nos comentários.
Entre para a Asimov