

Leitura recomendada
Pronto para transformar a forma como sua equipe lida com projetos de IA? Com o Kubeflow, você ganha uma plataforma open‑source, construída sobre Kubernetes, que simplifica desde a criação de pipelines até a implantação de modelos em produção. Ao unir automação de fluxos de trabalho, notebooks colaborativos e ferramentas avançadas de MLOps em um único painel, o Kubeflow elimina barreiras técnicas e acelera cada etapa do ciclo de vida do seu modelo.
Ao longo deste artigo, você verá como, usando Python, é possível orquestrar tarefas, rastrear experimentos e escalar recursos de forma consistente independentemente de rodar on‑premises ou na nuvem. Vamos explorar os principais componentes, entender suas vantagens e dar os primeiros passos para elevar seus projetos de machine learning a um novo patamar.
O que é o Kubeflow?

O Kubeflow é uma plataforma de código aberto criada para facilitar a vida de quem trabalha com machine learning. Ele foi projetado especialmente para rodar sobre o Kubernetes, oferecendo uma estrutura robusta e escalável para o desenvolvimento, gerenciamento e execução de fluxos de trabalho de machine learning. Em vez de precisar lidar com todos os detalhes técnicos da conteinerização e da orquestração de serviços, engenheiros e cientistas de dados podem se concentrar no que realmente importa: criar, treinar e implantar modelos.
Com o Kubeflow, é possível montar pipelines, ou seja, fluxos de trabalho organizados em etapas que automatizam desde a preparação dos dados até a avaliação e a publicação do modelo treinado. Essa organização torna o processo mais claro e reprodutível, especialmente em equipes maiores ou quando o projeto precisa escalar para diferentes ambientes de nuvem, como Google Cloud, AWS, Azure ou IBM Cloud. A plataforma também inclui ferramentas para rastrear experimentos, controlar versões de modelos e monitorar o desempenho, promovendo práticas de MLOps.
Um dos grandes diferenciais do Kubeflow é que ele fornece uma interface acessível com abstrações de alto nível. Isso permite que cientistas de dados interajam com ferramentas complexas sem precisar entender todos os detalhes sobre como o Kubernetes conecta e gerencia essas partes. Por trás dessa simplicidade, o Kubeflow adota conceitos avançados do Kubernetes, como o modelo de operador, que ajuda a manter a estrutura modular e organizada.
Por que usar o Kubeflow para Machine Learning?
Usar o Kubeflow para machine learning significa dar um salto na forma como sua equipe lida com todo o ciclo de vida de modelos inteligentes. Em vez de montar ambientes separados para cada etapa, desde a preparação dos dados até a implantação em produção, você conta com uma plataforma única que aproveita toda a robustez do Kubernetes. Isso libera seu time para focar nas partes criativas do projeto, enquanto o Kubeflow cuida de distribuir cargas de trabalho, monitorar experimentos e manter tudo organizado.
1. Escalabilidade nativa em Kubernetes
A escalabilidade nativa é um dos maiores trunfos do Kubeflow. Quando seu conjunto de dados cresce ou você precisa treinar modelos mais complexos com GPUs e TPUs, basta ajustar o número de nós em seu cluster. Esse mesmo fluxo funciona em diferentes nuvens (AWS, GCP, Azure) ou em ambientes híbridos, garantindo que não haja o risco de ficar preso a um único fornecedor e mantendo a consistência entre desenvolvimento e produção.
2. Automação de fluxos de trabalho com Kubeflow Pipelines
Automatizar pipelines de machine learning deixa de ser um desafio quando você define suas etapas como um grafo de tarefas interligadas. Com os Kubeflow Pipelines, cada execução gera metadados que documentam parâmetros e resultados, tornando cada experimento rastreável e fácil de reproduzir. Componentes modulares permitem reaproveitar trechos de código seja no pré-processamento, no treinamento ou na validação e misturá-los em novas receitas de forma ágil.
3. Ferramentas integradas para todo o ciclo de ML
- Katib: autoML para ajuste de hiperparâmetros e busca de arquitetura neural;
- KServe: serviço de inferência unificado para modelos de frameworks como TensorFlow e PyTorch;
- Central dashboard: interface única para gerenciar notebooks, pipelines e serviços;
- Treinamento distribuído: suporte nativo a frameworks como TensorFlow, PyTorch e JAX via Training Operator.
4. Padronização de MLOps
Por fim, adotar o Kubeflow é também abraçar práticas de MLOps. Com metadados centralizados, notebooks versionados e dashboards que exibem o desempenho em tempo real, a sua equipe ganha governança e colaboração em um só lugar. E, por ser compatível com bibliotecas como XGBoost, ONNX e frameworks variados, o Kubeflow se encaixa facilmente no ecossistema que você já usa, simplificando a integração e empoderando todos os envolvidos no projeto.
Componentes principais do Kubeflow
O Kubeflow é composto por vários componentes que trabalham juntos para fornecer uma plataforma abrangente para machine learning. Vamos explorar alguns dos principais componentes.
Kubeflow Pipelines: o que são e como funcionam

O Kubeflow reúne diversos módulos que, juntos, formam uma solução completa para todo o ciclo de vida de machine learning sobre Kubernetes. Um dos alicerces dessa plataforma são os Pipelines, que permitem desenhar fluxos de trabalho como se fossem mapas de etapas interligadas. Cada pipeline descreve, de forma detalhada, fases como pré-processamento de dados, treinamento, avaliação e implantação de modelos. Tudo roda em containers Docker, o que garante portabilidade e escalabilidade.
A interface web dos pipelines oferece uma visão clara das execuções, com registro de métricas e acompanhamento de experimentos. Isso torna mais simples entender o comportamento de cada etapa.
Jupyter Notebooks: integração e uso no Kubeflow

Para quem gosta de um ambiente mais interativo, o Kubeflow se integra perfeitamente aos Jupyter Notebooks. Basta escolher o kernel (Python, R ou Scala) e começar a explorar dados, testar ideias e desenvolver modelos de maneira colaborativa. Esses notebooks rodam dentro do próprio cluster Kubernetes, o que significa que você tem acesso direto aos dados e ao poder de processamento necessários, sem precisar configurar nada no seu computador.
Kubeflow Serving: como implantar modelos de ML
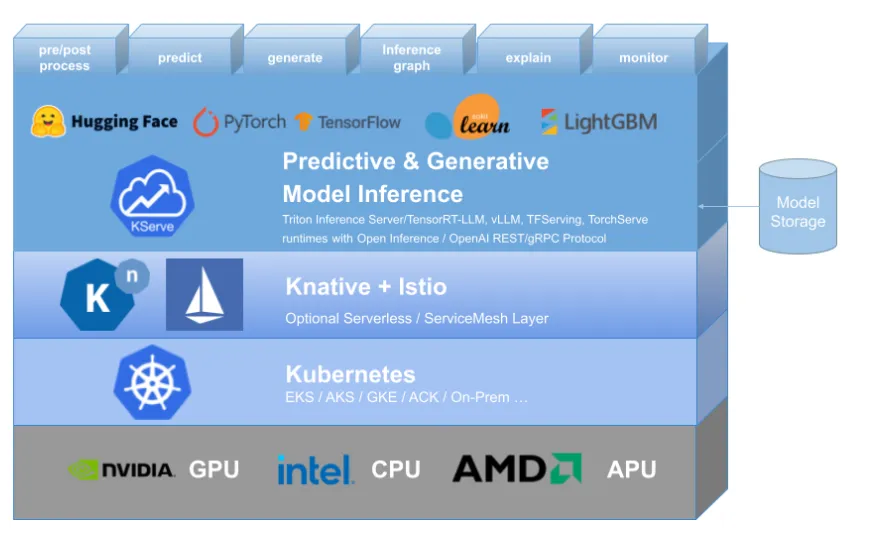
Depois de treinar um modelo, o próximo passo é colocá-lo em produção, e é aí que o Kubeflow Serving entra em cena. Ele transforma seu modelo treinado em um serviço HTTP escalável, suportando frameworks como TensorFlow Serving, Seldon Core, PyTorch e Scikit-Learn. Quer sejam suas previsões para lotes de dados, quer sejam chamadas em tempo real, o Serving ajusta automaticamente réplicas e recursos, garantindo que suas aplicações continuem responsivas conforme o uso cresce.
Kubeflow Training Operator: treinamento de modelos em escala
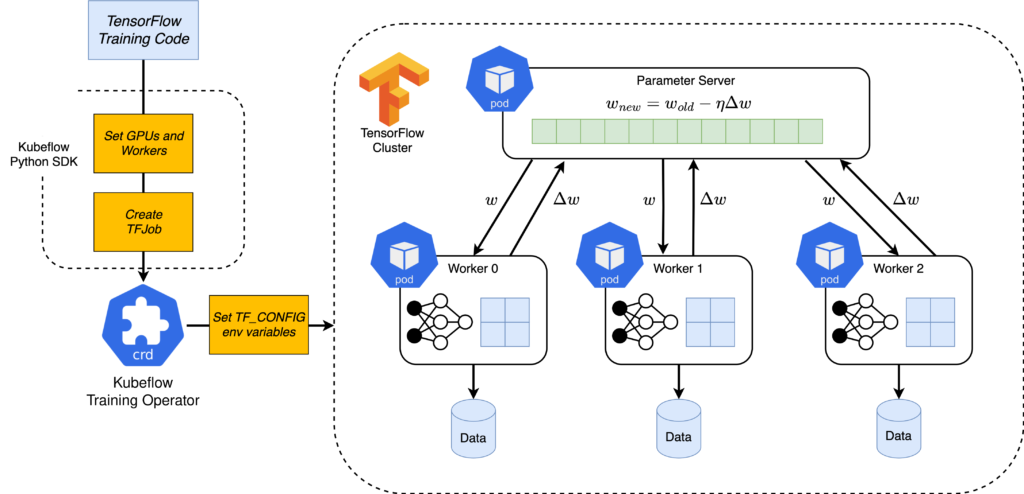
Já o Kubeflow Training Operator se encarrega de facilitar o treinamento distribuído. Utilizando operadores nativos do Kubernetes, ele gerencia recursos e replicasets para rodar tarefas de treinamento com TensorFlow, PyTorch, XGBoost e outros, liberando você das complexidades de escalonar nós manualmente.
Dessa forma, grandes volumes de dados podem ser processados de forma paralela e eficiente, aproveitando ao máximo o cluster de máquinas disponível.
Kubeflow Metadata: rastreamento e gerenciamento de metadados
Por fim, manter o controle sobre experimentos, conjuntos de dados e versões de modelos é essencial para equipes que trabalham em projetos complexos. É exatamente esse papel que o Kubeflow Metadata desempenha. Ele centraliza informações sobre cada execução de pipeline, registrando artefatos, parâmetros de treino e resultados, o que facilita a reprodução de experimentos, a auditoria de processos e a colaboração entre diferentes profissionais.
Como começar a usar o Kubeflow com Python?
Agora que você já conhece os principais componentes do Kubeflow, vamos ver como começar a usá-lo com Python.
Configuração do ambiente de desenvolvimento
Começar a usar o Kubeflow com Python é mais simples do que parece, e logo você vai perceber como ele traz organização e escalabilidade ao seu fluxo de trabalho de machine learning. Primeiro, é preciso preparar o terreno: defina onde seu cluster Kubernetes vai rodar.
Se você quer testar tudo na sua máquina, ferramentas como Minikube ou MicroK8s são ótimas opções; se prefere partir para a nuvem, o Google Kubernetes Engine (GKE) e outros provedores oferecem suporte transparente ao Kubeflow. Com o Kubernetes pronto, siga a documentação oficial para instalar o Kubeflow normalmente usando o kfctl e garantir que você tenha acesso ao dashboard web, onde todo o gerenciamento acontece.
Criando seu primeiro pipeline de ML com Kubeflow
Com o ambiente configurado, o próximo passo é criar seu primeiro pipeline. Graças ao Kubeflow Pipelines, você não precisa mergulhar em YAML ou Helm charts; é só usar a SDK de Python para definir um pipeline como uma função decorada. Cada etapa do seu fluxo pré-processamento, treinamento do modelo e avaliação vira um componente isolado, executado em contêineres Docker.
Você escreve tudo em Python, compila o pipeline em um arquivo JSON e o submete ao servidor de pipelines diretamente do seu script ou de um notebook. Em poucos minutos, o layout do seu pipeline aparece na interface gráfica, pronto para ser executado e monitorado.
Para ilustrar, veja um exemplo bem enxuto em que criamos um pipeline chamado “Meu Pipeline de ML”:
Exemplos práticos de integração com Python
import kfp
from kfp import dsl
@dsl.pipeline(
name='Meu Pipeline de ML',
description='Um pipeline simples de Machine Learning'
)
def meu_pipeline():
# Aqui você adiciona as tarefas: carga de dados, treino, validação...
pass
if __name__ == '__main__':
kfp.Client().create_run_from_pipeline_func(meu_pipeline, arguments={})Nesse trecho, o decorator @dsl.pipeline marca a função como ponto de partida do seu fluxo. Depois, ao chamar create_run_from_pipeline_func, o Kubeflow Pipelines gera e executa o gráfico de tarefas, tudo automaticamente. A partir daí, é só ir adicionando componentes: uma etapa que lê dados do seu bucket, outra que treina um modelo com TensorFlow ou PyTorch e uma terceira que registra métricas e armazena artefatos.
Futuro do Kubeflow e tendências em MLOps
O Kubeflow vem se firmando como uma das principais soluções open source para operacionalizar projetos de machine learning em ambientes Kubernetes e suas últimas evoluções mostram como a plataforma acompanha as demandas do setor. Hoje, ela oferece um conjunto de componentes modulares como Pipelines, Katib para AutoML, KServe para serving de modelos, Notebooks interativos e o Trainer para treinamento distribuído que podem ser combinados de acordo com as necessidades de cada equipe. Essa flexibilidade permite que você inclua apenas o que for útil ao seu fluxo de trabalho, ao mesmo tempo em que mantém tudo integrado e compatível com outras ferramentas do ecossistema de ML.
Outro ponto forte do Kubeflow é a portabilidade. Seja rodando em datacenters on‑premises, nas principais nuvens públicas ou em configurações híbridas, os pipelines e modelos criados permanecem os mesmos, sem amarrações a um único provedor. Isso facilita a migração de workloads entre diferentes ambientes e reduz o risco de ficar “presa” a uma única infraestrutura.
A escalabilidade é garantida pelo uso do Kubernetes como base: tanto o treinamento quanto a inferência podem crescer automaticamente conforme a demanda, sem necessidade de intervenção manual. E, graças à automação de pipelines reprodutíveis, equipes maiores mantêm processos confiáveis, com etapas padronizadas que vão do pré‑processamento à avaliação do modelo.
Comece agora: curso gratuito de Python para IA
Neste artigo, exploramos o que é o Kubeflow, suas vantagens, componentes principais e como começar a usá-lo com Python. Agora você está pronto para transformar sua forma de trabalhar com dados e entrar de cabeça no mundo da IA? Inscreva‑se agora no curso Python para IA: do zero ao seu primeiro chatbot, da Asimov Academy, e descubra:
- Como seu cérebro aprende melhor e como criar hábitos de estudo eficientes;
- Os fundamentos de Python e IA, mesmo sem experiência prévia;
- A biblioteca LangChain para desenvolver chatbots que entendem sites, vídeos e PDFs;
- O passo a passo para automatizar tarefas e liberar tempo para o que importa.
O professor Adriano vai acompanhá‑lo em cada etapa, garantindo que você construa seu próprio chatbot do início ao fim. Não perca a chance de dar seus primeiros passos em programação e inteligência artificial, tudo de forma prática, completa e gratuita!
Curso Gratuito

Seu primeiro projeto de IA com Python – curso grátis com certificado
Aprenda a programar com Python e explore a inteligência artificial! Crie um chatbot prático que interage com seus próprios dados.
Comece agoraVocê também pode gostar:




Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp