

O Web Scraping é uma técnica poderosa utilizada para extrair informações de páginas da web. Para quem trabalha com dados, é uma habilidade essencial, pois permite coletar dados de sites de forma automatizada. No entanto, para realizar o Web Scraping de maneira eficaz, é necessário entender o básico de HTML. Neste artigo, vamos explorar os conceitos fundamentais de HTML para Web Scraping que você precisa saber para começar a raspar dados da web.
Entendendo a Estrutura de uma Página Web
Antes de mais nada, é importante compreender como uma página web é estruturada. O HTML (HyperText Markup Language) é a espinha dorsal de qualquer página na internet. Ele é composto por uma série de elementos chamados de “tags”, que definem o conteúdo e a estrutura da página.
Tags, Atributos e Elementos
Uma tag HTML é um elemento delimitado por colchetes angulares, como <html>, <body>, <div>, <span>, e assim por diante. Cada tag pode ter atributos, que fornecem informações adicionais sobre o elemento. Por exemplo, uma tag de link (<a>) pode ter um atributo href que indica o URL de destino do link.
Um elemento HTML é composto pela tag de abertura, seus atributos, o conteúdo e a tag de fechamento. Por exemplo:
<a href="https://www.exemplo.com">Visite nosso site</a>Estrutura Básica de uma Página HTML
Uma página HTML típica tem a seguinte estrutura:
<!DOCTYPE html>
<html>
<head>
<title>Título da Página</title>
</head>
<body>
<h1>Este é um cabeçalho</h1>
<p>Este é um parágrafo.</p>
</body>
</html><!DOCTYPE html>: Define o tipo de documento e a versão do HTML.<html>: O elemento raiz de uma página HTML.<head>: Contém metadados e links para scripts e folhas de estilo.<title>: Define o título da página, que é exibido na aba do navegador.<body>: Contém o conteúdo da página, como cabeçalhos, parágrafos, imagens, etc.
Classes e IDs
Classes e IDs são atributos que fornecem identificadores únicos para elementos HTML. Eles são extremamente úteis no Web Scraping, pois permitem que você direcione elementos específicos para extrair dados.
- Classes: podem ser aplicadas a vários elementos e são usadas principalmente para estilização com CSS. No entanto, no contexto de Web Scraping, você pode usar classes para localizar grupos de elementos semelhantes.
<div class="informacao">Dados importantes</div>- IDs: são únicos em uma página e são uma maneira de identificar um único elemento. IDs são muito úteis para localizar um elemento específico rapidamente.
<div id="conteudo-principal">Conteúdo exclusivo</div>Ferramentas de Inspeção
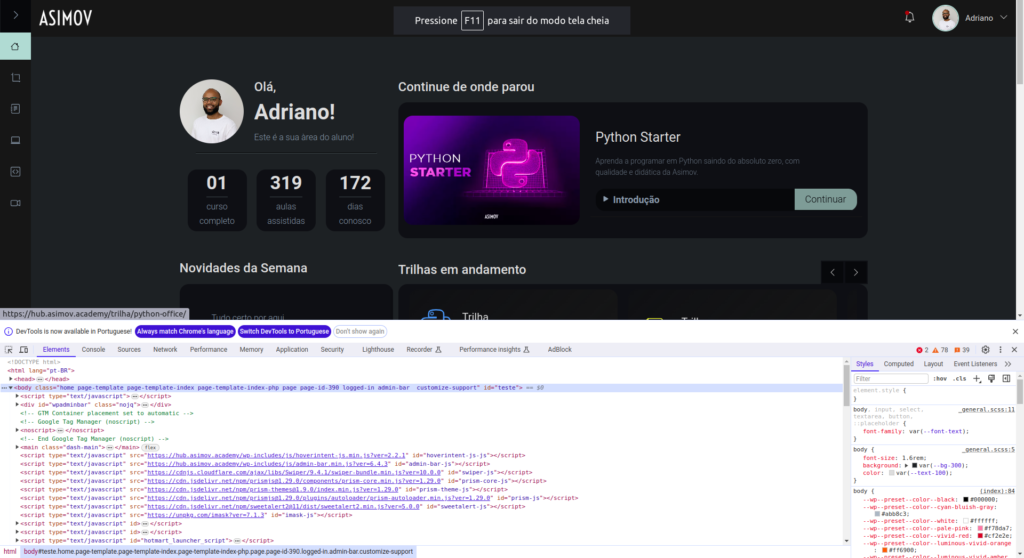
Para realizar o Web Scraping, você precisa inspecionar a página e entender como os dados estão organizados. Isso pode ser feito usando as ferramentas de desenvolvedor do navegador (DevTools), acessíveis geralmente pressionando F12 ou clicando com o botão direito em um elemento e selecionando “Inspecionar”.
Ao inspecionar um elemento, você pode ver sua tag, classes, IDs e outros atributos. Essas informações são cruciais para escrever os seletores que você usará para extrair os dados.
Localizar Elementos por Tag
Localizar elementos por tag é útil quando queremos interagir com tipos específicos de conteúdo em uma página. Por exemplo, se quisermos extrair todos os parágrafos de um artigo, podemos buscar por todas as tags <p>. Essa abordagem é simples e direta, mas tem suas limitações, pois muitas vezes diferentes elementos podem compartilhar a mesma tag.
Como Localizar Elementos por Tag
Para localizar elementos por tag, utilizamos ferramentas e bibliotecas de Web Scraping, como o BeautifulSoup em Python. O BeautifulSoup permite que você especifique a tag que está procurando e retorna todos os elementos que correspondem a essa tag. Vejamos um exemplo básico:
from bs4 import BeautifulSoup
import requests
url = 'https://exemplo.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Localizando todos os parágrafos
paragrafos = soup.find_all('p')
for paragrafo in paragrafos:
print(paragrafo.text)No código acima, find_all('p') é usado para encontrar todas as tags <p> na página, e então imprimimos o texto de cada parágrafo
Limitações e Considerações
Localizar elementos apenas por tag pode não ser suficiente em páginas complexas com muitos elementos compartilhando a mesma tag. Além disso, é importante estar ciente das questões legais e éticas relacionadas ao Web Scraping, como respeitar o robots.txt dos sites e não sobrecarregar os servidores com muitas requisições.
Conclusão
Entender o básico de HTML é o primeiro passo para se tornar eficiente em Web Scraping. Com o conhecimento das estruturas de páginas, tags, classes e IDs, você estará bem equipado para começar a extrair dados da web. Lembre-se de que a prática leva à perfeição, então comece a explorar diferentes sites e pratique a identificação e extração de elementos HTML. Com o tempo, você desenvolverá as habilidades necessárias para realizar Web Scraping em qualquer site.
Você também pode gostar:








Cursos de programação gratuitos com certificado
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:
- Conteúdos gratuitos
- Projetos práticos
- Certificados
- +20 mil alunos e comunidade exclusiva
- Materiais didáticos e download de código
Comentários
30xp