BLOG

Ferramentas de automação: 10 projetos para aplicar no trabalho



Neste artigo, você irá entender como automatizar arquivos CSV com Python.
Se você é analista de dados ou trabalha com planilhas em sua empresa, já deve ter se deparado com um tipo de arquivo chamado CSV, que é um arquivo de texto muito útil para armazenar dados em estrutura de tabela.
É natural que, ao trabalhar com esse tipo de arquivo, surja a necessidade de automatizar alguma rotina repetitiva ou até mesmo a impossibilidade de realizar operações em arquivos com muitas linhas de dados, devido à alta demanda de processamento. O que poucos sabem é que com Python é possível resolver todos esses problemas e ainda otimizar suas rotinas com CSV.
Neste artigo vamos ensinar como usar Python para trabalhar com arquivos CSV. É interessante que você já esteja familiarizado com o básico de Python, mas se não estiver, não tem problema, temos um curso completo sobre a linguagem. Vamos lá!
A maneira mais fácil de ler arquivos CSV com Python é utilizando a biblioteca Pandas. Se você ainda não a conhece, temos um artigo completo com as principais funções do Pandas para ajudá-lo a sair do básico.
Primeiramente, você precisará instalar o Pandas em sua máquina. Para isso, basta abrir o Prompt de Comando e procurar por cmd no Menu Iniciar.
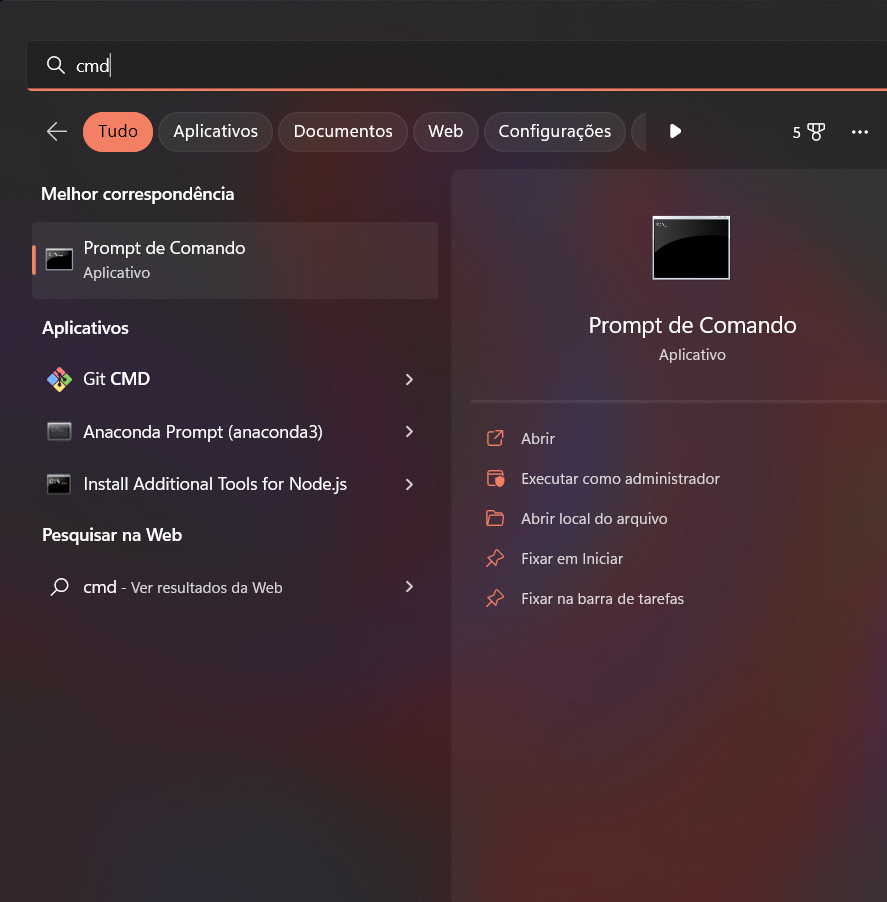
Ainda com o terminal aberto, vamos instalar a biblioteca. Basta digitar a linha de código abaixo:
pip install pandas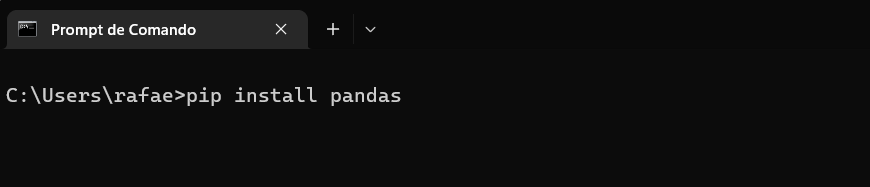
Pronto! Agora que você já instalou o Pandas, é só chamá-lo em seu script. Uma dica bem importante é usar o apelido do Pandas, pois sempre que importamos uma biblioteca no Python, podemos chamá-la por um apelido. No caso do Pandas, normalmente se usa o “pd”. Essa prática é útil porque fica mais fácil para outros programadores ou até mesmo você identificar a biblioteca quando estiver analisando o código.
import pandas as pdCom a biblioteca importada, conseguimos ler um arquivo CSV e transformá-lo em uma tabela (DataFrame) no Python com apenas uma linha de código:
pd.read_csv("caminho_arquivo/arquivo.csv")Basta passar o caminho em que o seu arquivo está localizado como argumento da função “read_csv”. O único argumento obrigatório é o diretório do arquivo, porém há diversos outros que podem ser passados para auxiliar na extração dos dados. Você pode encontrar todos eles na documentação da função.
É possível passar como argumento quais colunas você quer importar para seu DataFrame, o que fazer com valores nulos ou vazios, o formato dos dados a ser importados, dentre tantos outros. Sugerimos explorar a documentação para usufruir ao máximo dessa ferramenta.
Depois de importar seus dados, você provavelmente vai querer manipulá-los, e, por sorte, o Pandas também oferece diversas funções que nos auxiliam nisso. Inclusive, temos um artigo com as principais funções do Pandas, as quais podem ajudá-lo a melhorar suas habilidades com a biblioteca e se destacar na análise de dados.
Abaixo, deixamos um exemplo simples de manipulação de dados com Pandas, mas recomendo que leia nossos artigos e faça nossos cursos para análises mais avançadas.
Considere a seguinte tabela:
| País | População | Extensão territorial (Km²) |
| China | 1.439.323.776 | 9.596.961 |
| Índia | 1.380.004.385 | 3.287.590 |
| Estados Unidos | 331.002.651 | 9.371.174 |
| Indonésia | 273.523.615 | 1.904.569 |
| Brasil | 212.559.417 | 8.515.767 |
| Rússia | 145.934.462 | 17.098.246 |
| México | 128.932.753 | 1.964.375 |
| República Democrática do Congo | 89.561.403 | 2.344.858 |
| Irã | 83.992.949 | 1.628.750 |
O seguinte trecho de código executa algumas simples manipulações na base de dados:
import pandas as pd
df = pd.read_csv("dados_populacao.csv") # Lendo o arquivo
df['Nova coluna'] = 'A' # Incluindo uma nova coluna
df['Pop por Km²'] = df['População'] / df['Extensão territorial (Km²)'] # Fazendo operações entre colunas e criando uma nova
df.columns = ['País', 'População', 'extensao_territorial', 'nova_coluna', 'pop_por_km'] # Alterando o nome das colunas
df.head(3) # Mostrar apenas as 3 primeiras linhas
df[df['População'] >= 10000] # Filtrando apenas as linhas com população acima de 10.000Depois de manipular e analisar seus dados no Pandas, é importante salvá-los em algum local para uso futuro. Felizmente, o Pandas oferece a função para salvar o arquivo modificado em qualquer local desejado, basta utilizar o seguinte comando:
df.to_csv("caminho_para_salvar_o_arquivo/nome_do_arquivo.csv", sep=";" , decimal=".")Para salvar seu arquivo em algum diretório, passe como argumento da função o caminho no qual você deseja salvá-lo. No caso acima, passamos alguns argumentos adicionais que são importantes ao salvar um documento CSV. O primeiro, sep, indica como as colunas serão delimitadas, sendo um parâmetro importante para padronizar a leitura dos dados. Outro argumento é o decimal, que indica como serão definidos os valores decimais. No caso, definimos como ponto, mas poderíamos ter definido como vírgula, dependendo da maneira como você quer padronizar seus dados.
Agora que você já sabe manipular dados em CSV com Python, pode expandir seu conhecimento aprendendo a trabalhar com arquivos Excel ou até se aventurar na área de ciência de dados. Temos diversos cursos na nossa plataforma para fazer você dar um salto na carreira. Vamos nessa?

Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:







Comentários
30xpA automação de arquivos CSV com Python e Pandas transforma tarefas operacionais repetitivas em fluxos escaláveis e padronizados de tratamento de dados, reduzindo esforço manual e aumentando confiabilidade analítica. Com poucas linhas de código, é possível ler, manipular, filtrar, enriquecer e exportar grandes volumes de informação, tornando o Pandas uma ferramenta estratégica para produtividade, preparação de dados e suporte a análises avançadas.
Olá, Henrique!
Isso aí! Python traz muito s benefícios na automação.
Qualquer dúvida, estamos à disposição!
Ao otimizar pequenas tarefas do dia-a-dia, nos permite olhar para problemas mais complexos.
Olá, Henrique!
Sim!!! É uma excelente forma de estudar rotas de automação.