TUTORIAL
PDF com senha: como abrir PDFs com senha usando Python
 Ana Maria Gomes • 11 meses atrás
Ana Maria Gomes • 11 meses atrás
 Luiza Cherobini Pereira
Luiza Cherobini Pereira
Você já se deparou com a necessidade de extrair imagens de um arquivo PDF? Seja para salvar aquela ilustração que chamou sua atenção, para analisar dados gráficos ou até mesmo para reutilizar em outro documento, saber como realizar essa tarefa pode ser extremamente útil. Neste tutorial, vamos explorar como o Python, uma linguagem de programação poderosa e acessível, pode nos ajudar a extrair imagens de PDFs de maneira simples e eficaz.
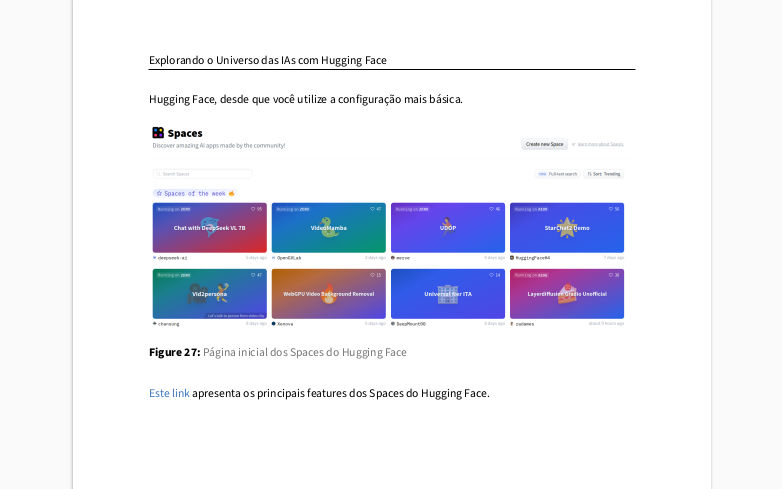
Primeiro, vamos entender por que essa habilidade é tão valiosa. PDFs são formatos de arquivo versáteis que podem conter uma riqueza de informações, incluindo texto, imagens, gráficos e tabelas. No entanto, essa flexibilidade tem um preço: nem sempre é possível trabalhar com PDFs de forma padronizada, especialmente quando o texto está salvo como uma imagem.
Imagine que você precisa apresentar dados de um relatório em uma reunião, mas esses dados estão em um PDF como gráficos ou tabelas. Copiar e colar diretamente não é uma opção. Ou talvez você queira analisar visualmente as imagens de um documento para um projeto de pesquisa. Em ambos os casos, extrair as imagens do PDF é a solução.
Para começar, você precisará ter o Python instalado em seu computador. Além disso, vamos utilizar algumas bibliotecas específicas que facilitam a manipulação de PDFs. A primeira delas é a pypdf, que nos permite acessar e iterar sobre as páginas de um PDF. Outra ferramenta útil é o Pillow, uma biblioteca que nos ajuda a trabalhar com imagens.
Abra o terminal e instale as bibliotecas necessárias com os seguintes comandos:
pip install pypdf
pip install PillowAgora que temos tudo pronto, vamos ao código. Primeiro, importe as bibliotecas que acabamos de instalar:
import pypdf
from PIL import ImageEm seguida, vamos abrir o arquivo PDF do qual queremos extrair as imagens:
leitor_pdf = pypdf.PdfReader('seu_arquivo.pdf')Agora, vamos iterar sobre cada página do PDF e extrair as imagens:
for pagina in leitor_pdf.pages:
for obj_imagem in pagina.images:
# Aqui, obj_imagem é um objeto ImageFile que contém a imagem
# Vamos salvar cada imagem em um arquivo separado
with open(f'imagem_{pagina.index}_{obj_imagem.index}.jpg', 'wb') as arquivo_imagem:
arquivo_imagem.write(obj_imagem.data)E pronto! Com esse código, você extraiu todas as imagens do PDF e as salvou em arquivos separados.
Extrair imagens de um arquivo PDF com Python é uma habilidade prática que pode economizar tempo e abrir novas possibilidades para o seu trabalho ou estudo. Com as bibliotecas certas e um pouco de código, você pode automatizar esse processo e focar no que realmente importa: a análise e utilização dessas imagens. Experimente e veja como é fácil!
Aprenda a programar e desenvolva soluções para o seu trabalho com Python para alcançar novas oportunidades profissionais. Aqui na Asimov você encontra:







Comentários
30xp